







安居客–抓取楼盘信息(分析加代码)
使用scrapy框架
字段描述
https://sh.fang.anjuke.com/loupan/canshu-430820.html?from=loupan_index_more
430820 每个楼盘id
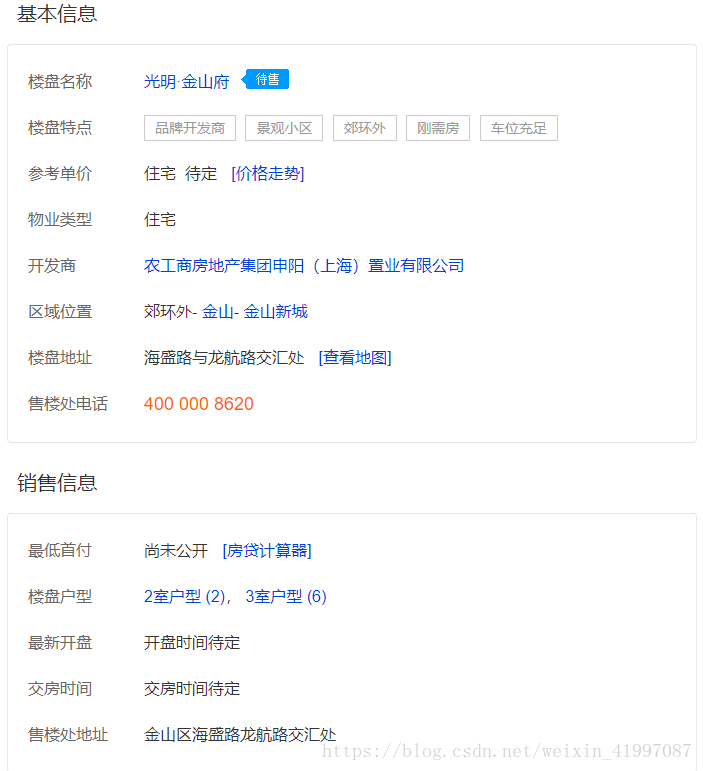

爬虫项目结构
spider.py代码如下
# -*- coding: utf-8 -*-
import scrapy
import re
class AjkSpider(scrapy.Spider):
name = 'Ajk'
allowed_domains = ['zz.fang.anjuke.com']
start_urls = ['http://zz.fang.anjuke.com/']
info_url = 'https://zz.fang.anjuke.com/loupan/canshu-{}.html?from=loupan_index_more'
def start_requests(self):
url = 'https://zz.fang.anjuke.com/loupan/all/p1_s6/'
yield scrapy.Request(url=url)
def parse(self, response):
house_list = response.xpath("//div[@class='key-list']/div")
for house in house_list:
house_info_link = house.xpath('./div[@class="infos"]/a[1]/@href').extract_first()
id = re.findall(r'loupan/(.*?).html',house_info_link)[0]
yield scrapy.Request(url=self.info_url.format(id),callback=self.parse_info)
try:
next_link = response.xpath('//div[@class="list-page"]/div[@class="pagination"]/a[text()="下一页"]/@href').extract_first()
print('下一页: ',next_link)
yield scrapy.Request(url=next_link,callback=self.parse)
except Exception as e:
print(e,'没有下一页连接')
def parse_info(self,response):
item = {}
# 基本信息
item['楼盘名称'] = response.xpath('//div[@class="can-border"]/ul/li[1]/div/a/text()').extract_first()
item['楼盘在售状态'] = response.xpath('//div[@class="can-border"]/ul/li[1]/div/i/text()').extract_first()
li_list1 = response.xpath('//div[@class="can-left"]/div[1]//ul/li')
for li in li_list1[1:-1]:
key = li.xpath('./div[1]/text()').extract_first()
value = ''.join([i.replace(' ', '') for i in li.xpath('./div[2]//text()').extract()])
item[key] = value
li_list2 = response.xpath('//div[@class="can-left"]/div[2]//ul/li')
for li in li_list2:
key = li.xpath('./div[1]/text()').extract_first()
value = ''.join([i.replace(' ', '') for i in li.xpath('./div[2]//text()').extract()])
item[key] = value
li_list3 = response.xpath('//div[@class="can-left"]/div[3]//ul/li')
for li in li_list3:
key = li.xpath('./div[1]/text()').extract_first()
value = ''.join([i.replace(' ', '') for i in li.xpath('./div[2]//text()').extract()])
item[key] = value
yield item
middlewares.py
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
request.cookies = {'aQQ_ajkguid': '9AFB4A62-E667-BC70-F0B8-14E48617A70A',
'lps': 'http%3A%2F%2Fzhengzhou.anjuke.com%2Fsale%2F%3Fpi%3Dbaidu-cpc-zz-tyongzz1%26kwid%3D354272438%26utm_term%3D%25e9%2583%2591%25e5%25b7%259e%25e6%2588%25bf%25e4%25ba%25a7%25e7%25bd%2591%7Chttps%3A%2F%2Fwww.baidu.com%2Fbaidu.php%3Fsc.Ks0000amqZra9B-651ZvTMfKnsPpQFkArdgDJUafypdBIoY23nNf7kkulb3OLqPg9tyj1LZHxv8uCsL7dwlHiosIQngohpsfGhsPc5Asgwlo2GRF1zVrbkznwdbNM_n_9ZnihlRUZzgBINGdyu8dRJIRaLIDKDWjhUoE-1eikcDi8rF_G0.7R_NR2Ar5Od663pb48AGvjzuBz3rd2ccvp2mrSPe7erQKM9ks4SZ91YPj_LjsdqXL6knTILubtTMukvIT7jHzYD1pyn2ISZukselt2IvAOkseY3RqrZu_sLlt2X1jX19utT2xZjxI9LdJN9h9mePSHcC.U1Yk0ZDqdJ5yLUXO_EoPS0KspynqnfKY5IpWdVvLEeQl1x60pyYqnWcd0ATqmhNsT1D0Iybqmh7GuZR0TA-b5Hnz0APGujYzP1m0UgfqnH0kndtknjDLg1DsnH-xn10kPNt1PW0k0AVG5H00TMfqQHD0uy-b5HDYPH-xnWm4nH7xnWDknjwxnWm1PHKxnW04nWb0mhbqnW0Y0AdW5HD3nW61rjRvndtLrjTsrj6vPWwxnH0snNtzPjTdrjf1PWRzg100TgKGujYkP0Kkmv-b5Hnzn6KzuLw9u1Yk0A7B5HKxn0K-ThTqn0KsTjYs0A4vTjYsQW0snj0snj0s0AdYTjYs0AwbUL0qn0KzpWYs0Aw-IWdsmsKhIjYs0ZKC5H00ULnqn0KBI1Ykn0K8IjYs0ZPl5fKYIgnqnHT1n164nW04nW63P1nsPWnsnWc0ThNkIjYkPHnLrjRvrjDLnWms0ZPGujY4nHRkPjm1n10snj7-ujnk0AP1UHYvnj-jnWckwRD3fbDdwDD30A7W5HD0TA3qn0KkUgfqn0KkUgnqn0KlIjYs0AdWgvuzUvYqn7tsg1Kxn7ts0Aw9UMNBuNqsUA78pyw15HKxn7tsg1Kxn0Ksmgwxuhk9u1Ys0AwWpyfqnWm3PjndPjRv0ANYpyfqQHD0mgPsmvnqn0KdTA-8mvnqn0KkUymqn0KhmLNY5H00uMGC5H00uh7Y5H00XMK_Ignqn0K9uAu_myTqnfK_uhnqn0KWThnqnHDzP1T%26ck%3D4720.1.72.290.177.278.178.460%26shh%3Dwww.baidu.com%26sht%3Dbaidu%26us%3D1.0.1.0.1.300.0%26ie%3Dutf-8%26f%3D8%26tn%3Dbaidu%26wd%3D%25E9%2583%2591%25E5%25B7%259E%25E6%2588%25BF%25E4%25BA%25A7%25E7%25BD%2591%26oq%3D%2525E4%2525B9%2525B0%2525E6%252588%2525BF%2525E7%2525BD%252591%26rqlang%3Dcn%26inputT%3D11553%26bs%3D%25E4%25B9%25B0%25E6%2588%25BF%25E7%25BD%2591%26bc%3D110101', 'ctid': '26', 'twe': '2', 'sessid': '5AEE4532-EB7D-8A7C-1C69-C6CE92CF5ACF', '_ga': 'GA1.2.241737769.1537856823', '_gid': 'GA1.2.463505834.1537856823', '58tj_uuid': 'd35956f1-2db3-487d-a70f-970cb62098ee', 'als': '0', 'isp': 'true', 'init_refer': '', 'new_uv': '2', 'Hm_lvt_c5899c8768ebee272710c9c5f365a6d8': '1537859039', 'new_session': '0', 'ajk_member_captcha': 'af863f7718fa2c550f0c60d8b544cf80', 'lp_lt_ut': 'c31592ba401e3949743172cb515496e2', '__xsptplus8': '8.2.1537859039.1537860596.24%232%7Cwww.baidu.com%7C%7C%7C%25E9%2583%2591%25E5%25B7%259E%25E6%2588%25BF%25E4%25BA%25A7%25E7%25BD%2591%7C%23%23HHbVaf59daFvUy64ssk3hQoEFnshtL2z%23', 'Hm_lpvt_c5899c8768ebee272710c9c5f365a6d8': '1537860599'}
return None
pipelines.py
import os
import csv
import pandas as pd
class AjkPipeline(object):
def init(self):
self.df = pd.DataFrame()
def process_item(self, item, spider):
print(item)
self.df = self.df.append(item,ignore_index=True)
def close_spider(self,spider):
self.df.to_csv('郑州楼盘信息.csv')
class Pipeline_ToCSV(object):
def __init__(self):
# csv文件的位置,无需事先创建
store_file = os.path.dirname(__file__) + '/spiders/qtw.csv'
# 打开(创建)文件
self.file = open(store_file, 'w')
# csv写法
self.writer = csv.writer(self.file)
# 将字典的values写入
def process_item(self, item, spider):
# 判断字段值不为空再写入文件
print(item)
self.writer.writerow(item)
return item
def close_spider(self, spider):
# 关闭爬虫时顺便将文件保存退出
self.file.close()














 1487
1487











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









