



前言
以diffusion为核心技术的文生图模型大放异彩,但大多闭源,而Stable Diffusion(SD)作为开源模型的代表,其在很多方面表现出了强劲的效果。
目前已经有很多框架项目支持sd,今天笔者这里就给一个hf的官方demo,可以快速infer和微调,以一个直观的例子来展示效果,为想快速上手的小伙伴提供一个极其简单的demo。
注意:所有demo核心都来自hf的官方,所以大家也可以直接看原博客。
链接:https://huggingface.co/blog/zh/sd3#使用-dreambooth-和-lora-进行微调
如果大家对diffusion扩散模型更底层的实现和原理感兴趣的话可以看笔者更早之前写过的一篇:https://zhuanlan.zhihu.com/p/599642809
废话不多说,进入正题。
快速体验
需要首先下载sd3.5模型到本地,链接如下:
https://hf.co/stabilityai/stable-diffusion-3.5-large
下载后就可以使用gradio来简单体验下了
import torch
import argparse
import os
import traceback
import gradio as gr
from PIL import Image
import os
import torch
from diffusers import StableDiffusion3Pipeline
pipe = StableDiffusion3Pipeline.from_pretrained("model/stable-diffusion-3.5-large", torch_dtype=torch.bfloat16).to("cuda")
def generate_image(prompt):
# 使用 Stable Diffusion 模型生成图片
image = pipe(
prompt=prompt,
negative_prompt="",
num_inference_steps=40,
height=1024,
width=1024,
guidance_scale=4.5,
).images[0]
# save img
image.save("temp_save_img/demo.png")
return image
with gr.Blocks() as demo:
gr.Markdown("## 来画画画!")
with gr.Row():
with gr.Column():
prompt_input = gr.Textbox(lines=2, placeholder="Enter your prompt here...", label="Prompt")
submit_button = gr.Button("Submit")
with gr.Column():
output_image = gr.Image(label="Generated Image")
submit_button.click(fn=generate_image, inputs=prompt_input, outputs=output_image)
# Launch the Gradio interface
demo.launch(share=False, server_name='0.0.0.0',server_port=57653)
下面是原生sd的一些效果图
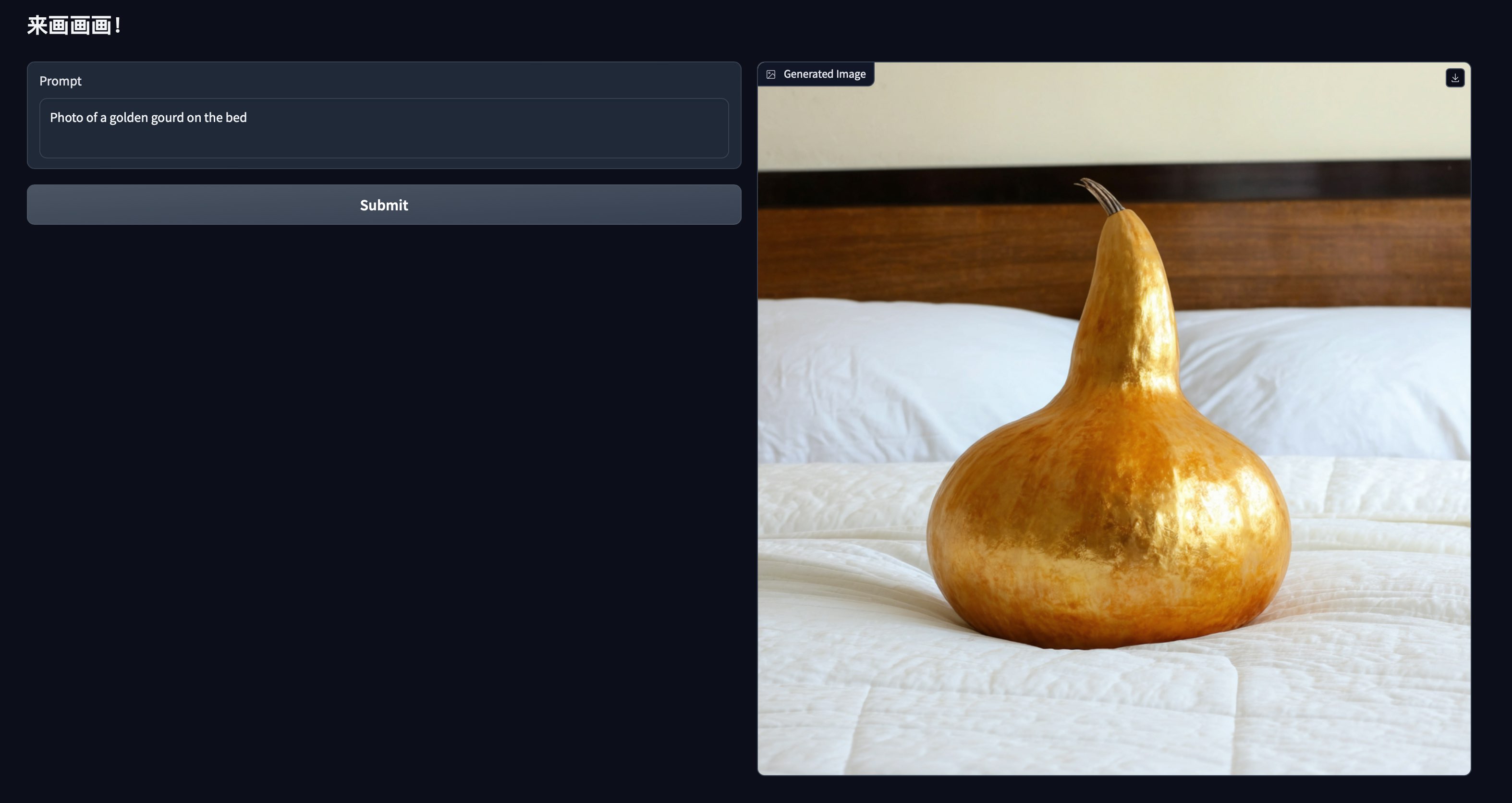

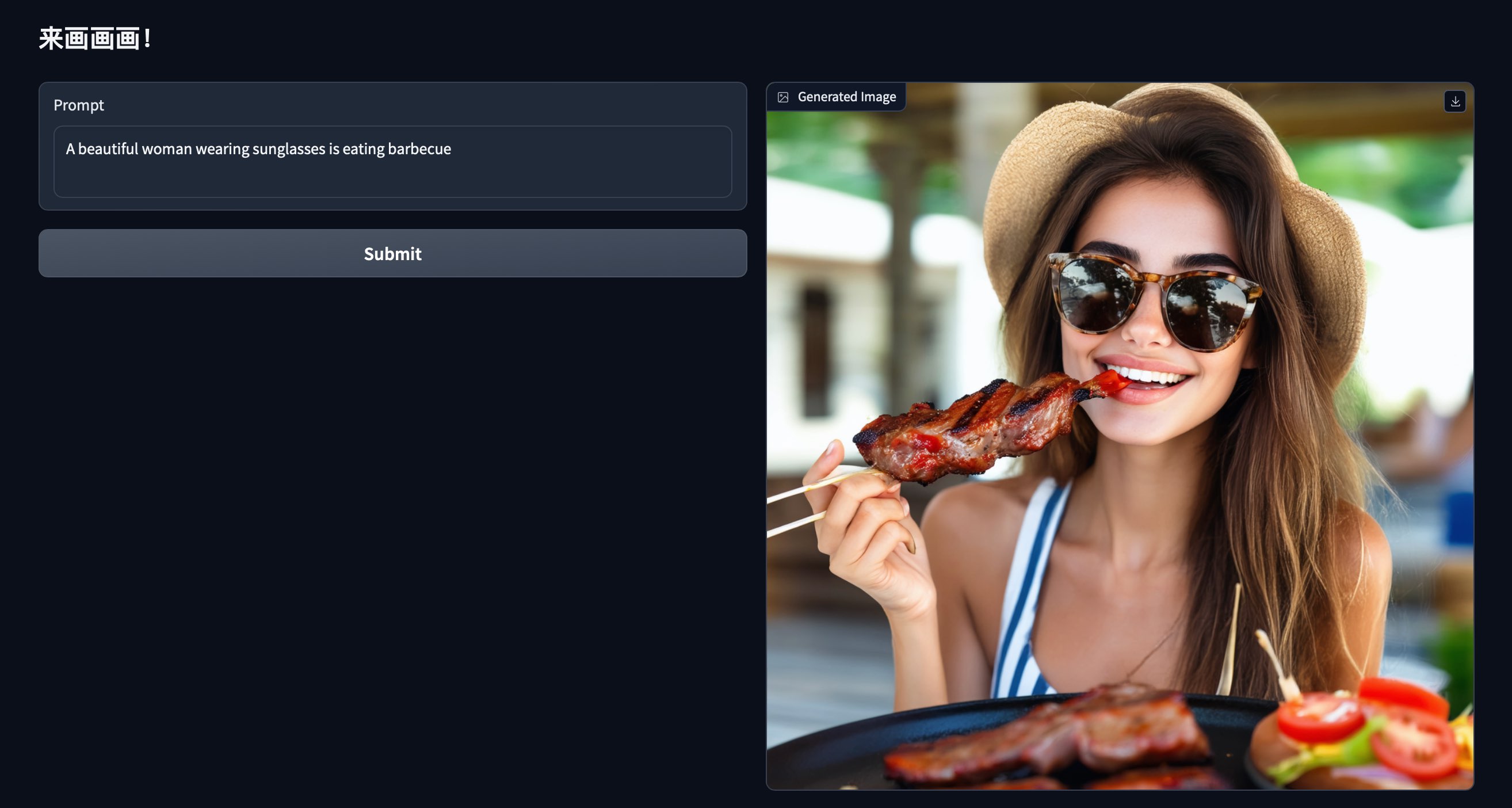
自己怎么 train 以及训练后怎么infer?
(1)train
这里为了demo,笔者随手找了一件自己身边的小物件:一个钥匙环上小葫芦(正好可以和上面演示的原生能力做个对比),废话不多说,下面是笔者对自己小葫芦随手拍的5张不同角度的照片
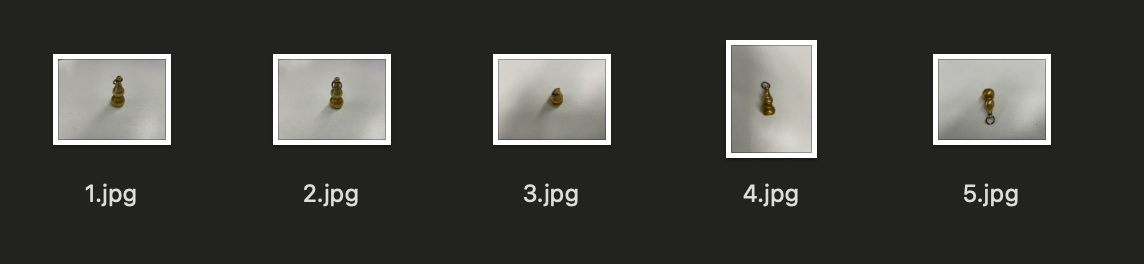
其中1.jpg如下

拍摄好了后,接下来就可以训练啦,启动脚本如下:
# https://github.com/huggingface/diffusers/tree/main/examples/dreambooth
accelerate launch train_dreambooth_lora_sd3.py \
--pretrained_model_name_or_path="model/stable-diffusion-3.5-large" \
--instance_data_dir="data/golden_gourd" \
--output_dir="output/golden_gourd_lora" \
--mixed_precision="bf16" \
--instance_prompt="photo of a golden gourd" \
--caption_column="text"\
--resolution=768 \
--train_batch_size=1 \
--gradient_accumulation_steps=1 \
--learning_rate=4e-4 \
--report_to="tensorboard" \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=700 \
--rank=16 \
--seed="0"
(a) 其中launch train_dreambooth_lora_sd3.py脚本来源:https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/train_dreambooth_lora_sd3.py,当然这里还有很多脚本可以参考,大家按需所取。
(b) 具体到这里启动脚本中有几个关键的参数是大家可能需要根据自己情况修改的,pretrained_model_name_or_path就是本地下载的原生sd模型路径、instance_data_dir就是刚笔者拍摄照片放置的本地路径、output_dir是训练后模型需要保存的路径,instance_prompt就是咱们当前要训练核心东西是啥,这里给一个描述,注意这里最好描述的务实具体一点,比如你的照片是一个名叫“小明”的小男孩的照片,不要写成“A photo of Xiao Ming”,这样效果可能不好,还不如写成“A little boy named Xiao Ming”把boy这个突出出来。这样它就起码知道我是要在这5个照片中学习的是这个boy而不是其他的,这个boy是我核心要学习的目标。
(2)infer
训练完了,就可以推理看看效果了,推理的代码也很简单只需要加一行即可
pipe.load_lora_weights("output/golden_gourd_lora")
全部代码如下
import torch
import argparse
import os
import traceback
import gradio as gr
from PIL import Image
import os
import torch
from diffusers import StableDiffusion3Pipeline
pipe = StableDiffusion3Pipeline.from_pretrained("model/stable-diffusion-3.5-large", torch_dtype=torch.bfloat16).to("cuda")
# 多加这一行即可
pipe.load_lora_weights("output/golden_gourd_lora")
def generate_image(prompt):
# 使用 Stable Diffusion 模型生成图片
image = pipe(
prompt=prompt,
negative_prompt="",
num_inference_steps=40,
height=1024,
width=1024,
guidance_scale=4.5,
).images[0]
# save img
image.save("temp_save_img/demo.png")
return image
with gr.Blocks() as demo:
gr.Markdown("## 来画画画!")
with gr.Row():
with gr.Column():
prompt_input = gr.Textbox(lines=2, placeholder="Enter your prompt here...", label="Prompt")
submit_button = gr.Button("Submit")
with gr.Column():
output_image = gr.Image(label="Generated Image")
submit_button.click(fn=generate_image, inputs=prompt_input, outputs=output_image)
# Launch the Gradio interface
demo.launch(share=False, server_name='0.0.0.0',server_port=57653)
好了,接下来我们看看效果
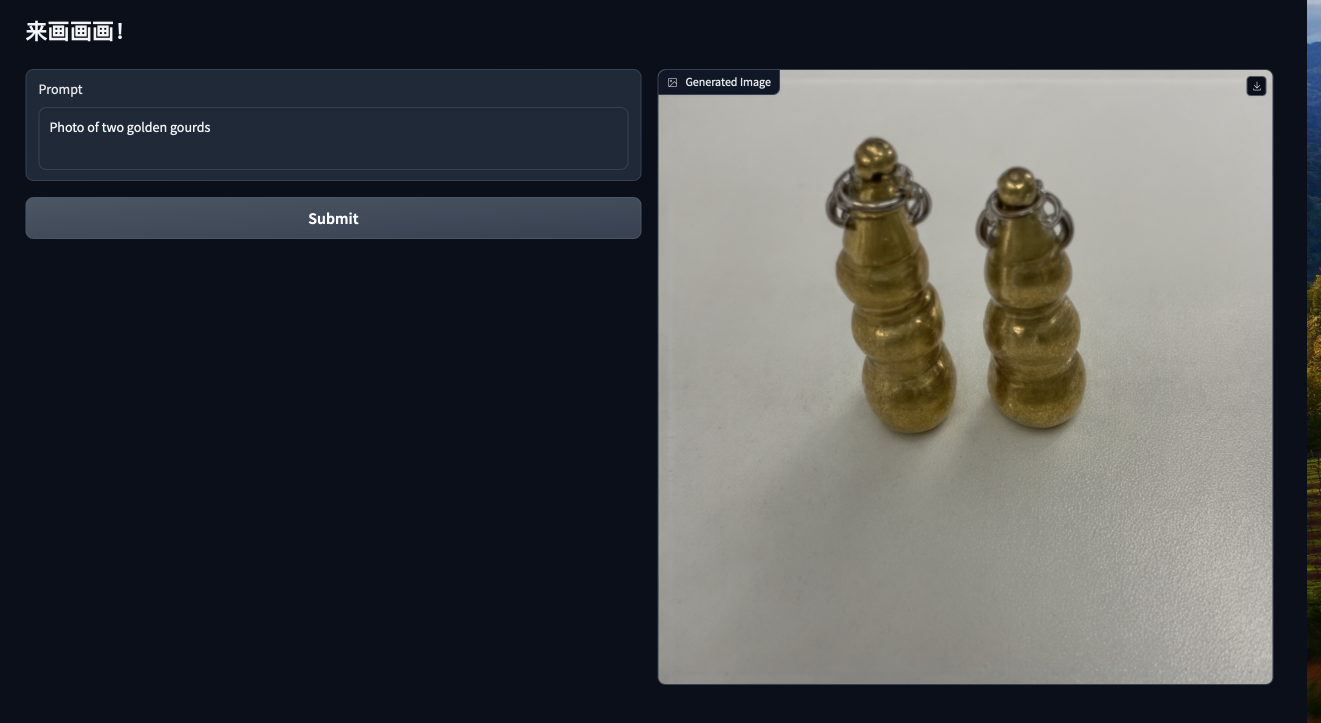
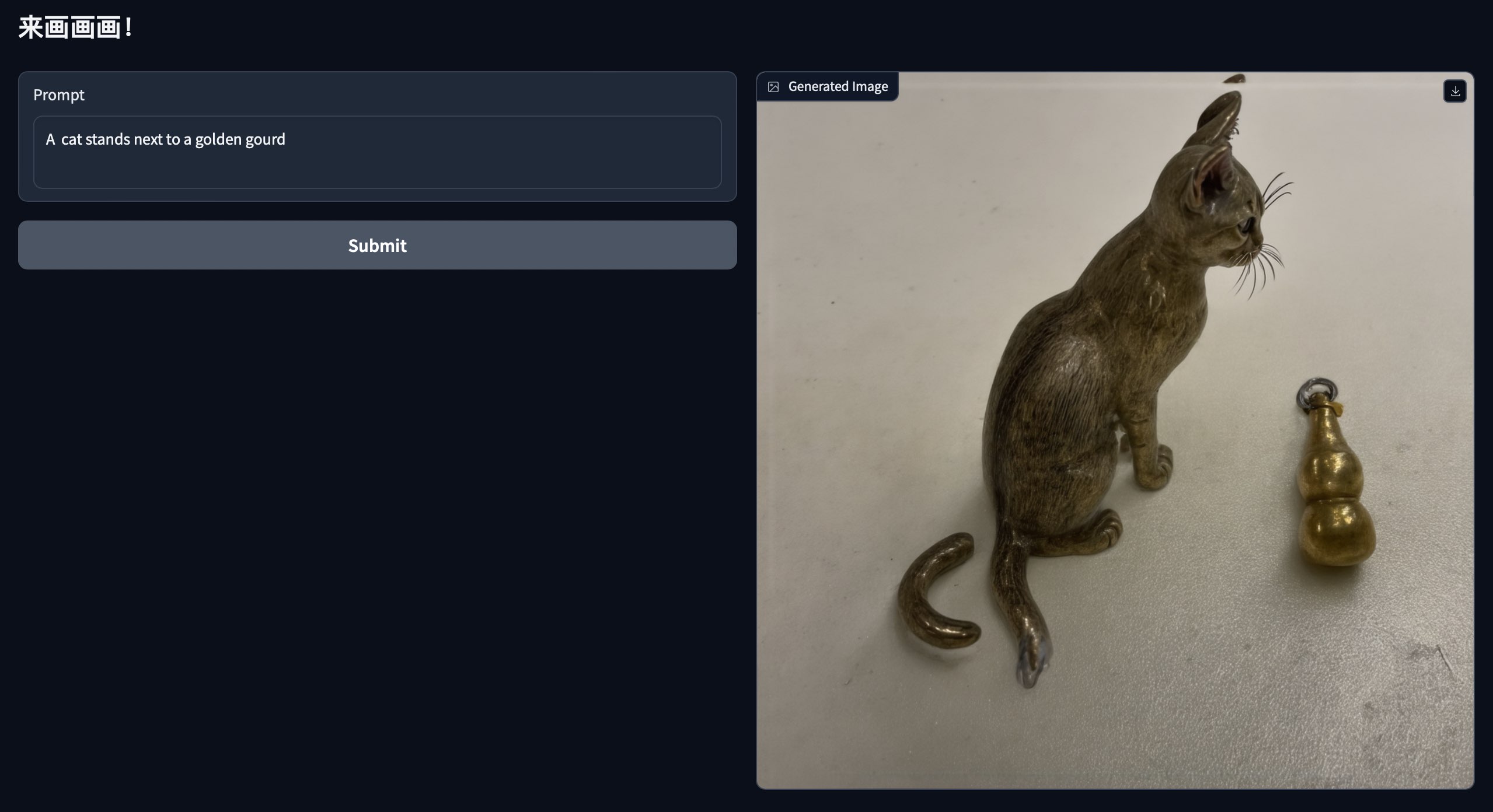
哈哈哈,第一张图稍微有些学奔,大家感兴趣的话可以试试学别的实体比如人物、宠物等等,甚至可以试试全参训练。另外就是同一个prompt多次infer的结果也差异很大,大家可以多试几次。
总结
本篇只是带大家快速尝试sd,入个门,sd还有很多东西可以折腾比如图生图等等,训练推理量化等等,大家感兴趣的话可以积极探索。
后面有时间笔者会再出一篇关于FLUX模型的实践,其是另外一个开源的文生图模型,效果同样强劲。

















 803
803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









