







论文:Image as a Foreign Language: BEIT Pretraining for All Vision and Vision-Language Tasks
链接:https://arxiv.org/pdf/2208.10442
Introduction
- Motivation:从三个方面进行收敛:backbone architecture, pretraining task, and model scaling up,通过引入Multiway Transformers建模通用目标(general-purpose modeling),模型结构上能够实现both deep fusion and modality-specific encoding。这样做的好处在于在大规模数据集预训练后,可以容易的迁移到各种下游任务中。
Regarding the image as a foreign language,将图像和文本一视同仁。此外,将图像文本对视为parallel sentences对齐多模态。 - 效果
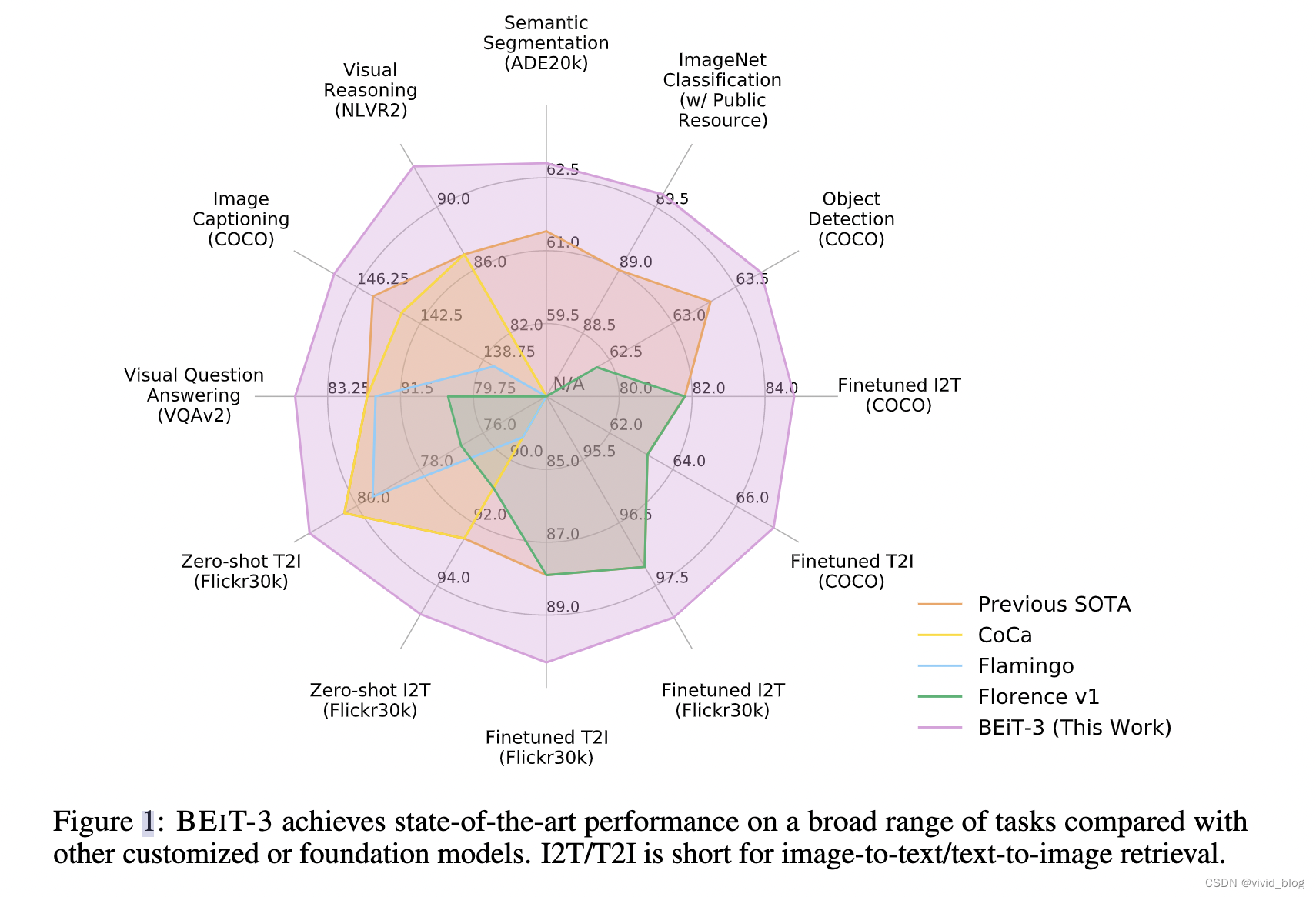
Details
整体架构:
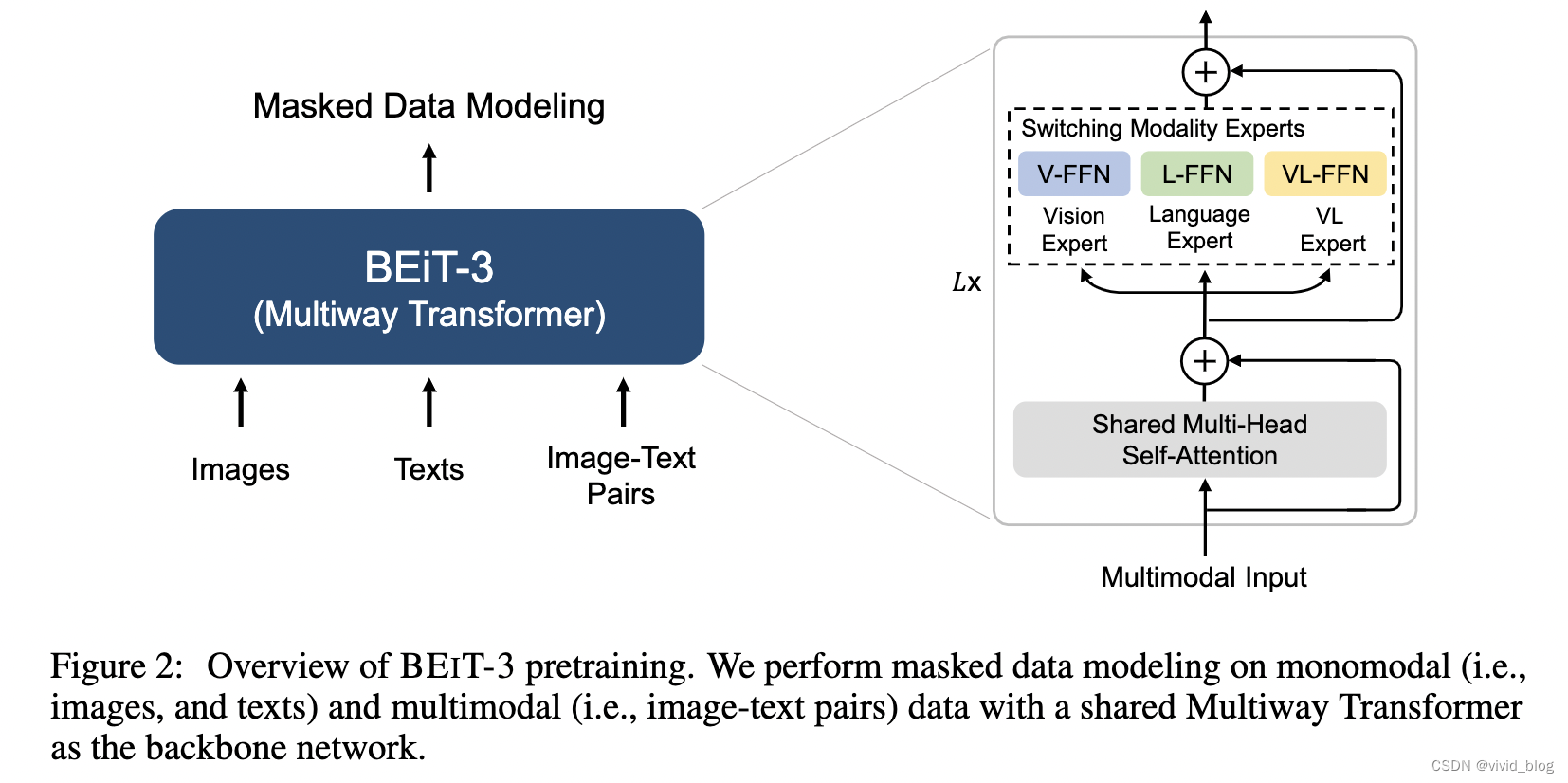
-
Backbone Network: Multiway Transformers
a. 每个Multiway Transformer 模块由一
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









