







写在前面,此文记录常用的优化算法包括:随机梯度下降(SGD),Momentum算法,AdaGrad算法,RMSProp算法,Adam算法,牛顿法和拟牛顿法(包括L-BFGS
参考1:https://www.cnblogs.com/ljygoodgoodstudydaydayup/p/7294671.html
参考2:https://blog.csdn.net/qsczse943062710/article/details/76763739
参考3:视频讲解
梯度下降法根据每次求解损失函数L带入的样本数,可以分为:全量梯度下降(计算所有样本的损失),批量梯度下降(每次计算一个batch样本的损失)和随机梯度下降(每次随机选取一个样本计算损失)。
在第n次迭代中,参数
θ
t
=
θ
t
−
1
+
Δ
θ
t
θ_t=θ_{t−1}+Δθ_t
θt=θt−1+Δθt
SGD
现在的SGD一般都指mini-batch gradient descent。SGD就是每一次迭代计算mini-batch的梯度,然后对参数进行更新,是最常见的优化方法了。即:
其中,
η
\eta
η是学习率,
g
t
g_t
gt是梯度。 SGD完全依赖于当前batch的梯度
- 优点:操作简单,计算量小,在损失函数是凸函数的情况下能够保证收敛到一个较好的全局最优解。
- 缺点:
- η \eta η是个定值(在最原始的版本),它的选取直接决定了解的好坏,过小会导致收敛太慢,过大会导致震荡而无法收敛到最优解。
- 对于非凸问题,只能收敛到局部最优,并且没有任何摆脱局部最优的能力(一旦梯度为0就不会再有任何变化)。
Momentum
SGD中,每次的步长一致,并且方向都是当前梯度的方向,这会收敛的不稳定性:无论在什么位置,总是以相同的“步子”向前迈。
Momentum的思想就是模拟物体运动的惯性:当我们跑步时转弯,我们最终的前进方向是由我们之前的方向和转弯的方向共同决定的。Momentum在每次更新时,保留一部分上次的更新方向:
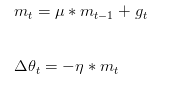
其中,
μ
\mu
μ是动量因子,决定了保留多少上次更新方向的信息,值为0~1,初始时可以取0.5,随着迭代逐渐增大;
g
t
g_t
gt是梯度;
η
\eta
η为学习率,同SGD。
- 优点:
- 一定程度上缓解了SGD收敛不稳定的问题(由于考虑到以前的梯度,从而减少改变的幅度)。
- 有一定的摆脱局部最优的能力(当前梯度为0时,仍可能按照上次迭代的方向冲出局部最优点),直观上理解,它可以让每次迭代的“掉头方向不是那个大“。左图为SGD,右图为Momentum。
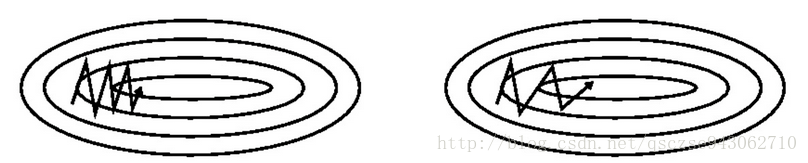
- 缺点:这里又多了另外一个超参数 μ \mu μ需要我们设置,它的选取同样会影响到结果
PS 类似Momentum算法这种对前进方向进行选择和调整的方法,还有Nesterov Momentum、共轭梯度法(Conjugate Gradient),这里不做过多介绍;后面这些算法主要研究如何选择合适的学习率 η \eta η
Adagrad
同一个更新速率不一定适合所有参数,比如有的参数可能已经到了仅需要微调的阶段,但又有些参数由于对应样本少等原因,还需要较大幅度的调动。Adagrad(自适应梯度法)通过记录每次迭代过程中的前进方向和距离,从而使得针对不同问题,有一套自适应调整学习率的方法:
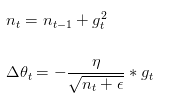
此处,相当于在给学习率增加了一个约束项,
−
1
∑
r
=
1
t
(
g
r
)
2
+
ϵ
-\frac{1}{\sqrt{\sum_{r=1}^t(g_r)^2+\epsilon}}
−∑r=1t(gr)2+ϵ1,使得随着迭代次数的增加,整体的学习率
−
η
∑
r
=
1
t
(
g
r
)
2
+
ϵ
-\frac{\eta}{\sqrt{\sum_{r=1}^t(g_r)^2+\epsilon}}
−∑r=1t(gr)2+ϵη越来越小
- 优点:解决了SGD中学习率不能自适应调整的问题
- 缺点:
- 学习率不随网络当前状态的变化,只随迭代次数无脑单调递减,在迭代后期可能导致学习率变得特别小而导致收敛及其缓慢。
- 还需要我们手动设置初始的 η \eta η
Adadelta/RMSProp
Adadelta是对Adagrad的扩展,也是一种自适应约束算法,加入了移动平均思想。
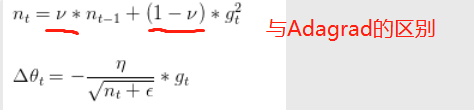
优点:与adagrad一样,不同位置不同学习率;但不是梯度无脑随累加,而是改为指数衰减的移动平均。 参考
其中,
h
n
−
1
h_{n-1}
hn−1为公式中的
n
t
−
1
n_{t-1}
nt−1
- 缺点:后期容易在小范围内产生震荡
Adam
Adam是Momentum和RMSprop的结合体,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。

其中,mt,nt分别是梯度的带权平均和带权有偏方差,初始为0向量, Adam的作者发现他们倾向于0向量(接近于0向量),特别是在衰减因子(衰减率)μ,ν接近于1时,所以要进行偏差修正,
m
t
^
,
n
t
^
\hat{m_t},\hat{n_t}
mt^,nt^是对
m
t
,
n
t
m_t,n_t
mt,nt的校正。
论文中建议:
μ
=
0.9
,
ν
=
0.999
,
ϵ
=
10
−
8
μ=0.9,ν=0.999,ϵ=10−8
μ=0.9,ν=0.999,ϵ=10−8
优点:结合Momentum和Adaprop,稳定性好,自适应学习率,同时相比于Adagrad,不用存储全局所有的梯度,适合处理大规模数据















 3714
3714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









