







什么是 LLM Agents
Agent,我们一般将其翻译为代理人、代理商、智能体等。
在人工智能领域,Agent 通常被定义为一种具有感知能力的实体,它能够通过对其所处环境的观察来做出相应的决策和反应。这种 Agent 既可以是软件形式的程序,例如对话机器人,也可以具备物理形态,比如扫地机器人。
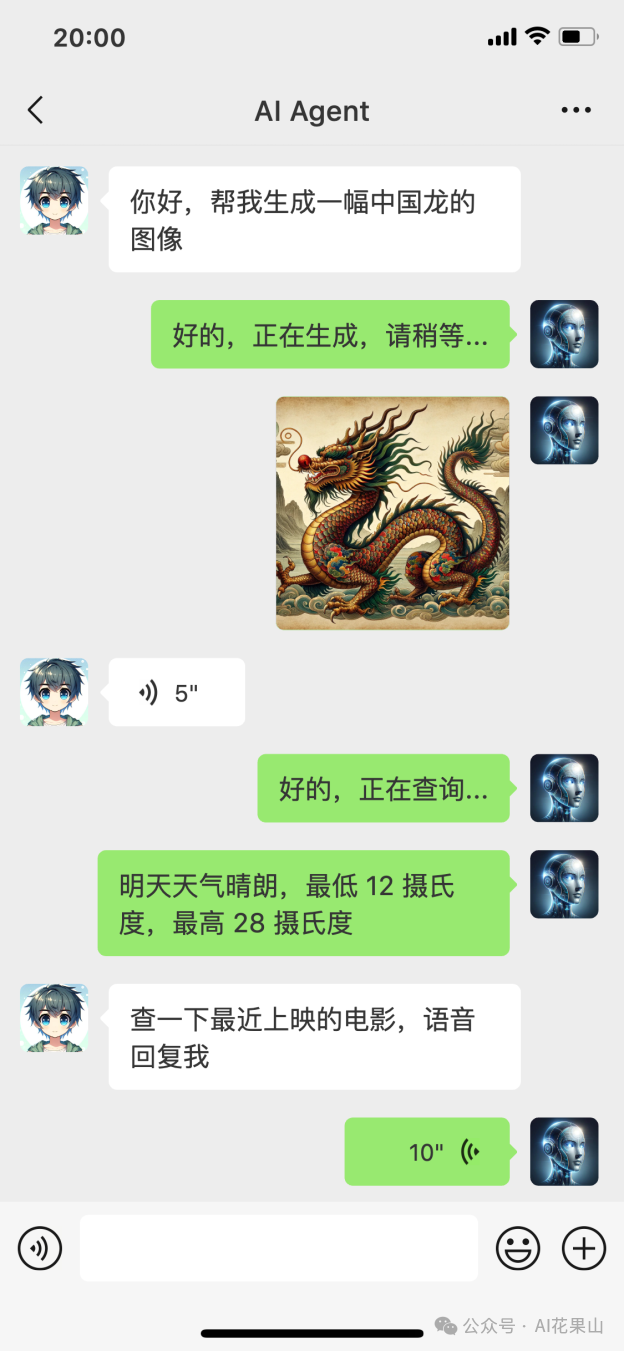
如图所示,是一次虚构的聊天会话,其中,Agent 通过思考和规划,然后使用绘画、搜索、语音等工具来完成用户的任务。
那么,LLM Agents 表示什么呢?以 ChatGPT 为代表的 LLM 展示了强大的语言理解、生成和推理能力等,从而将 Agent 的智能程度提升到了前所未有的高度。
OpenAI 的 Lilian Weng 在个人网站上发表了一篇博客 LLM Powered Autonomous Agents,详细阐述了 LLM 驱动下的智能体的架构。Lilian 将以 LLM 为驱动的 AI Agent,形式化为如下的公式: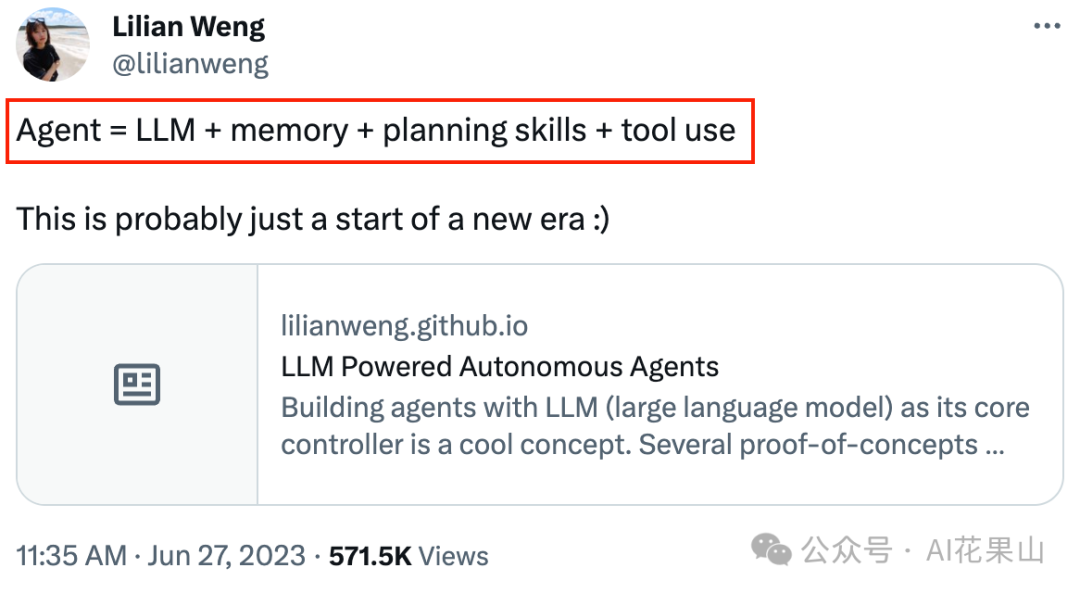 也就是说,以 LLM 为驱动的 AI Agent,包括以下几个重要组件:
也就是说,以 LLM 为驱动的 AI Agent,包括以下几个重要组件:
- LLM:大型语言模型,提供语言理解和生成能力等
- Planning:规划,基于LLM,将任务拆解为较小的、可管理的子任务,从而有效处理复杂任务
- Memory:记忆功能,LLM 本身是无状态的,需要外挂 Memory 来存储短期和长期的信息
- Tool use:像人类一样使用工具,突破 LLM 本身的限制,使用诸如搜索、代码执行、数学计算等工具
Lilian 为 LLM 为驱动的 Agent 系统绘制了如下的框架图: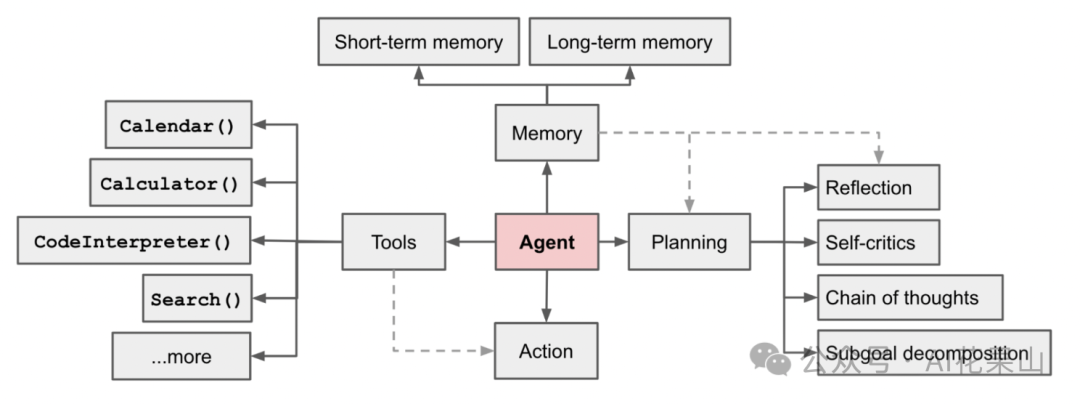
因此,LLM Agents 本质上是一个工程系统,在这个系统中,LLM 充当了「大脑」的角色,负责语言理解、思考和规划,将复杂任务分解成可管理的子任务,并制定执行策略,然后,通过使用各种工具和资源,有效完成这些复杂任务。简而言之,LLM Agents 是一个高度智能和自主的工程系统。
这里,我们也可以用汽车来打个比方。Agent 是汽车,而 LLM 类似于汽车的引擎,决定了车辆的性能。整辆车包括引擎、底盘、车身、车轮和驾驶舱等多个部件。这些部件协同工作,使得车辆能够运行。类似地,Agent 除了 LLM,还包括记忆存储、任务规划、增强工具等,这些组件协同工作,以实现更复杂的任务和目标。
下文的 Agent 如无特殊说明,都指 LLM Agent。
从 Copilot 到 Agent
这里,我们对 Copilot 和 Agent 做一个对比,进一步加深对 Agent 的认识。LLM 产品的应用范式,目前主要有 Copilot 和 Agent 两种。Copilot 是「副驾驶」、「助手」,在解决任务的时候更多的是起辅助作用,需要用户进行引导和干预。而 Agent 则更像是一个初级的「主驾驶」、「智能体」,可以根据任务目标进行自主思考和行动,具有更强的独立性和执行复杂任务的能力。
下面,我们从核心功能、流程决策、应用范围和开发重点几个方面对比 Copilot 和 Agent:
-
核心功能
-
- Copilot:更像是一个辅助驾驶员,更多地依赖于人类的指导和提示来完成任务。Copilot 在处理任务时,通常是在人为设定的范围内操作,比如基于特定的提示生成答案。它的功能很大程度上局限于在给定框架内工作。
- Agent:像一个初级的主驾驶,具有更高的自主性和决策能力。能够根据目标自主规划整个处理流程,并根据外部反馈进行自我迭代和调整。
-
流程决策
-
- Copilot:在处理流程方面,Copilot 往往依赖于 Human 确定的流程,这个流程是静态的。它的参与更多是在局部环节,而不是整个流程的设计和执行。
- Agent:Agent 解决问题的流程是由 AI 自主确定的,这个流程是动态的。它不仅可以自行规划任务的各个步骤,还能够根据执行过程中的反馈动态调整流程。
-
应用范围
-
- Copilot:主要用于处理一些简单的、特定的任务,更多是作为一个工具或者助手存在,需要人类的引导和监督。
- Agent:能够处理复杂的、大型的任务,并在 LLM 薄弱的阶段使用工具或者 API 等进行增强。
-
开发重点
-
- Copilot:主要依赖于 LLM 的性能,Copilot 的开发重点在于 Prompt Engineering。
- Agent:同样依赖于 LLM 的性能,但 Agent 的开发重点在于 Flow Engineering,也就是在假定 LLM 足够强大的基础上,把外围的流程和框架系统化,坐等一个强劲的 LLM 核心。
总的来说,从 Copilot 到 Agent 的转变意味着从一个辅助角色到一个更主动角色的转变。
- Agent 相比于 Copilot,表现出更高的自主性、智能程度和处理复杂任务的能力。
- Copilot 更多是作为一个高级助手,而 Agent 才是真正的 AI Native 的应用范式。
- 比如,现在的 AI 编程,github copilot 可以帮我们写函数、自动代码补全等,但它还不是一个真正自主决策的 Agent,比如根据给定的需求然后创建整个项目工程、编写测试用例等。
LLM Agent 应用案例
大语言模型的浪潮推动了 AI Agent 的快速发展。在 2023 年,出现了多个热门的 Agent 研究项目和应用案例,比如 AutoGPT、BabyAGI、斯坦福的 AI 小镇、HyperWrite、HuggingGPT 和 GPTs 等。
- AutoGPT:一个开源的自主 AI 代理,基于 gpt-4 和 gpt-3.5 模型,可以根据用户给定的目标,自动生成所需的提示,并执行多种任务,如创建网站、生产社交媒体内容、读写文件、浏览网页等
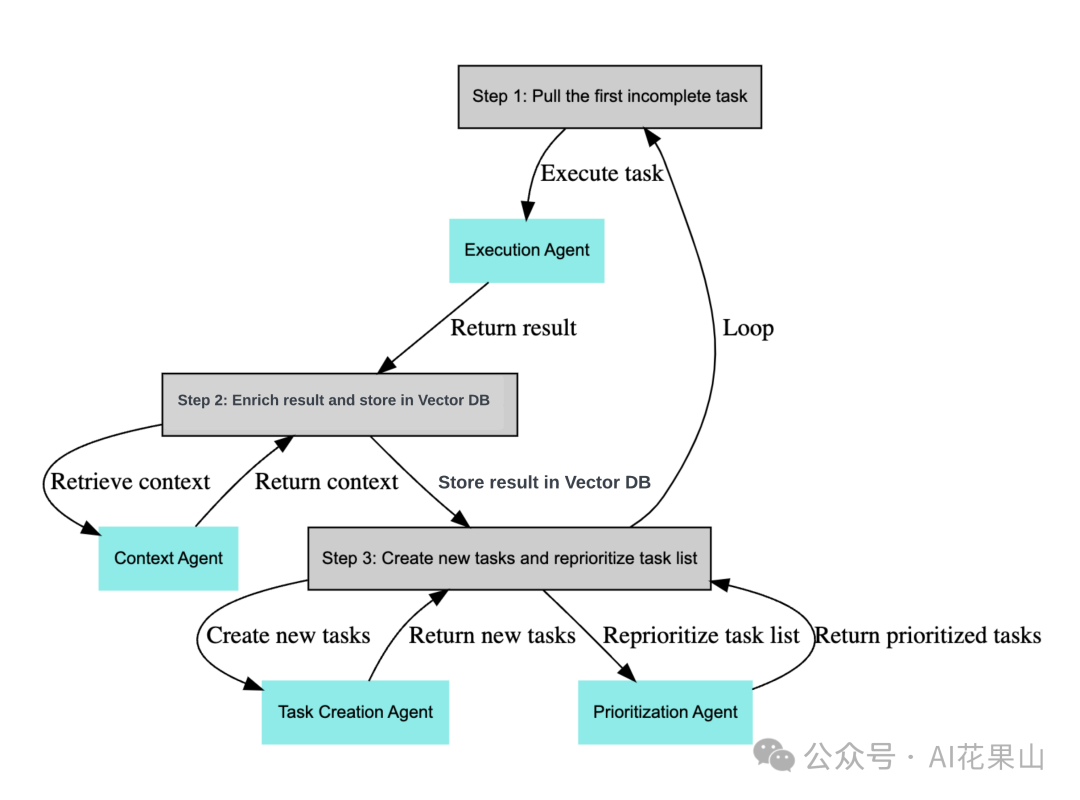
- BabyAGI:基于 AI Agent 的任务管理系统,能够使用 gpt-4 自动创建、执行和优先处理子任务。它包括 Execution Agent、Task Creation Agent 和 Prioritization Agent 等
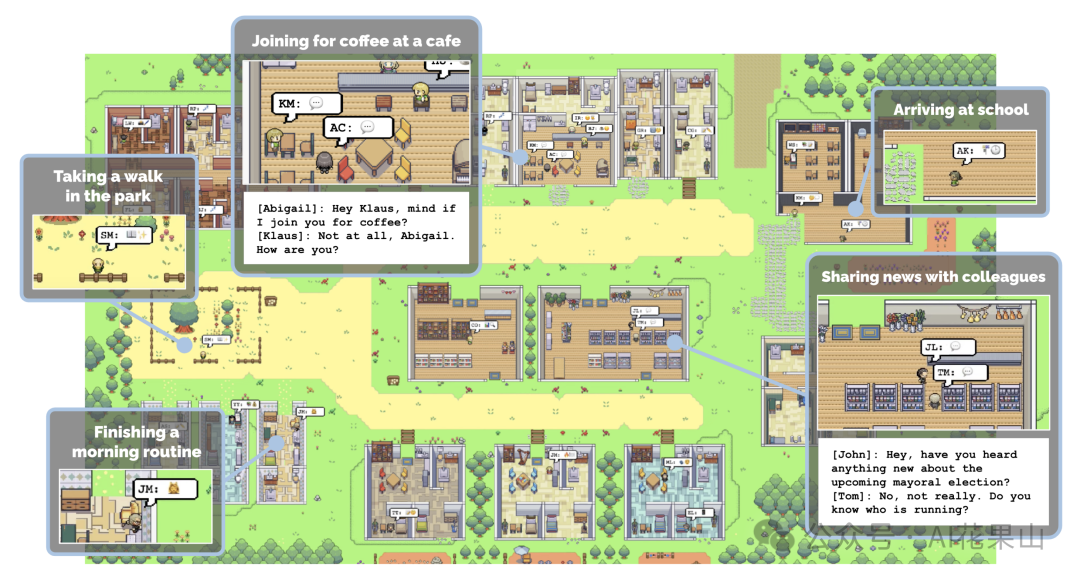
- 斯坦福 AI 小镇:一个由斯坦福和谷歌的研究人员共同开发的虚拟小镇,这个项目使用了25个由ChatGPT支持的AI代理(或称角色),每个代理都有其独特的身份和特点。这些代理被设置在一个虚拟的环境中,通过复杂的文本层来模拟和组织与每个代理相关的信息
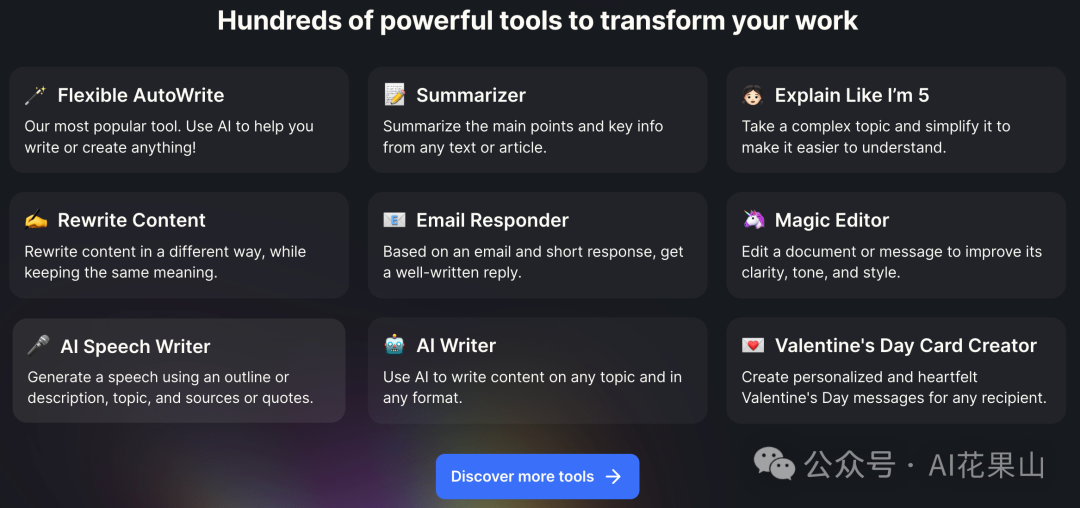
- HyperWrite:基于 AI Agent 的写作工具,它包含了很多工具,比如利用 Flexible AutoWrite 工具来协助内容创作,Summarizer 工具用于提炼文本关键点,还有 Rewrite Content 对文本进行润色和优化等
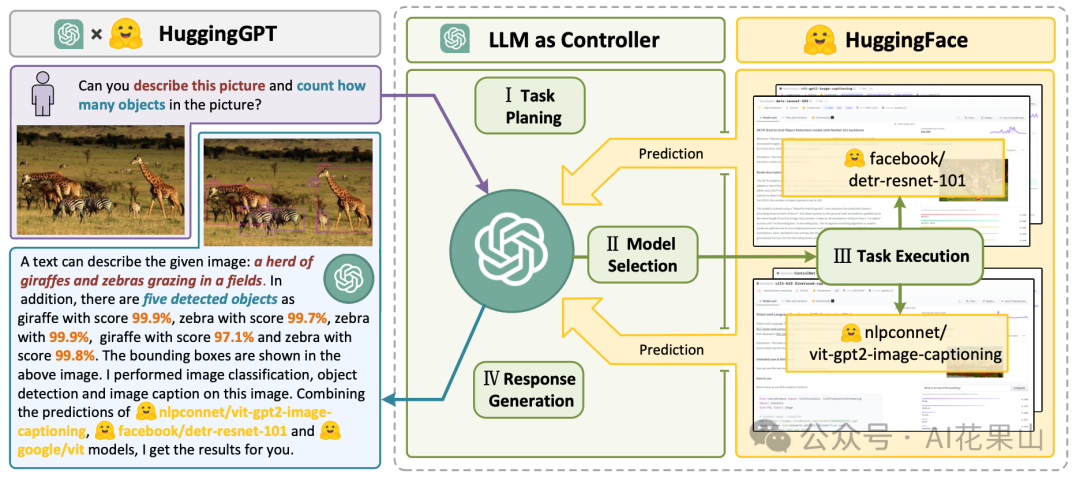
- HuggingGPT:由微软开发的一种 AI 协作系统,可以使用 Huggingface 上的多个模型来完成给定的任务。HuggingGPT 通过 ChatGPT 来协调各 AI 模型之间的合作,可以很好地处理多模态任务,如文本分类、物体检测、文本转语音、文本转视频等。
- GPTS:2023 年 11 月,OpenAI 在首届开发者大会(OpenAI Devday)上推出了引人瞩目的 GPTs。GPTs 可以看成是一种初级的 Agent 形态。GPTs 可以添加知识库,也可以执行代码,还可以通过 Action 调用外部 API(如在线检索),大大突破了 ChatGPT 本身能力的限制,因此 GPTs 可以处理很多复杂的任务。
更多 Agent 应用案例,可以参考 https://github.com/e2b-dev/awesome-ai-agents 。
LLM Agent 入门实现
现在,我们已经知道了 Agent = LLM + 规划 + 记忆 + 工具,那**如何把这几个核心组件有效地结合起来,实现一个简单的 Agent 系统呢?**这样我们可以更加深刻地理解,Agent 如何根据任务目标,拆解任务,并决定在什么时候使用什么工具。
根据 Prompt Engineering 实现的不同、是否支持聊天历史和是否支持多输入工具等,我们可以将 Agent 分成多种类型,比如 ReAct Agent,Self-ask Agent,Plan-and-Solve Agent 等。
另外,也有很多用于开发 Agent 的框架,比如 LangChain、LlamaIndex、AutoGen 和 AutoGPT 等。
这里,我们先不用框架,基于 ReAct(https://react-lm.github.io/) 实现一个简单的 Agent。
ReAct 原理
ReAct 的灵感来自于作者对人类行为的一个洞察:当人们需要执行多个步骤的任务时,通常会在每一步之间进行推理,并利用上一步的推理结果进行下次推理。基于这一理念,ReAct 的作者提出让 LLM 将推理过程以类似「内心独白」的形式表达出来,然后 LLM 根据这些独白来指导其后续动作。ReAct 就是 Reason + Act,它将推理(Reason)和行动(Action)融合到了 LLM 中,是一种有效的 Prompt Engineering 的范式。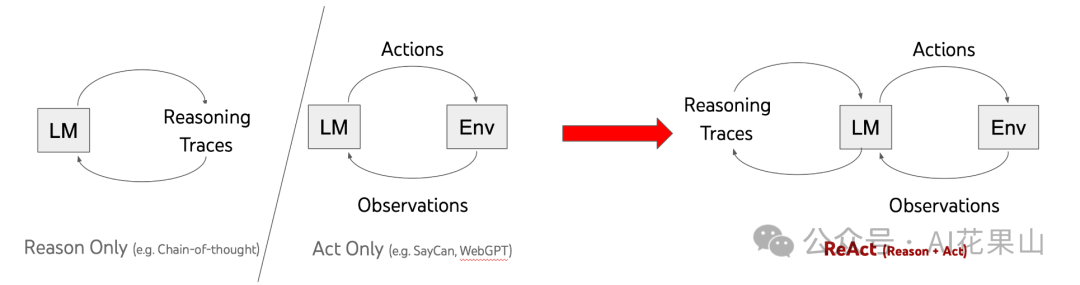
ReAct 仅包含了 Thought-Action-Observation 三个步骤,很容易判断推理过程的正确性,跟思维链(Chain-of-Thought,CoT)的主要区别是 CoT 只是在静态的 prompt 中加入了 “Let’s think step by step”,而 ReAct 的 prompt 是动态变化的。另外,CoT 只调用一次 LLM 即可,而 ReAct 是多次调用 LLM。
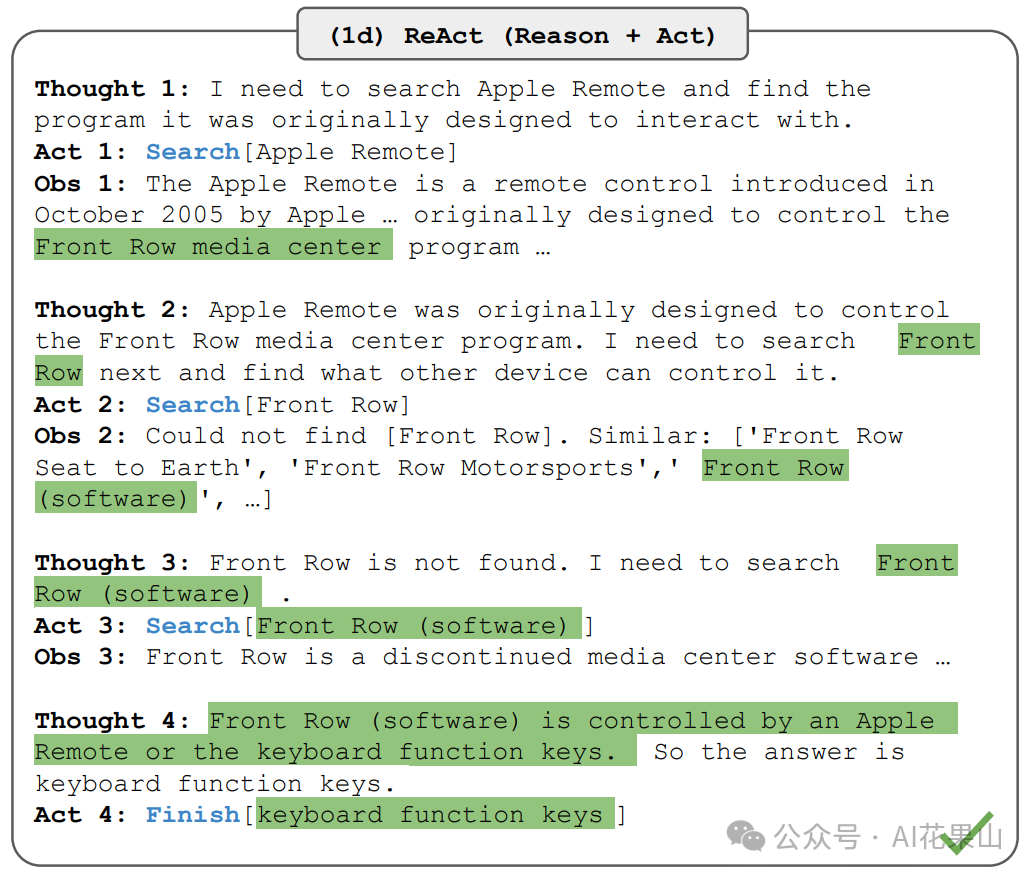
我们看下 ReAct 论文中的一个案例,在这个例子中,用户的提问是:除了苹果遥控器,还有什么其他设备可以控制苹果遥控器最初设计用来交互的程序?
基于这个问题,ReAct 进行 Though-Action-Observation,总共有 4 轮,如图所示:
-
Round 1**:**LLM 基于 Question 进行 Thought,决定采取什么 Action,执行 Action 得到 Observation
-
- 思考 1:我需要搜索苹果遥控器,并找出它最初设计用来与哪个程序交互
- 行动 1:Search[Apple Remote]
- 观察 1:苹果遥控器是苹果公司于2005年10月推出的一款遥控器,最初设计用来控制Front Row媒体中心程序。
-
Round 2**:**LLM 基于 Question, Thought 1, Action 1 和 Observation 1,汇总所有信息再次进行 Thought、Action 和 Observation
-
- 思考 2:苹果遥控器最初是设计来控制Front Row媒体中心程序的。接下来我需要搜索Front Row,并找出什么其他设备可以控制它。
- 行动 2:Search[Front Row]
- 观察 2:找不到 [Front Row]。类似:[‘Front Row Seat to Earth’, ‘Front Row Motorsports’, 'Front Row (software) ', …]
-
Round 3**:**LLM 汇总前面两轮得到的信息,进行再次 Thought、Action 和 Observation
-
- 思考 3:找不到Front Row。我需要搜索Front Row (software)
- 行动 3:Search[Front Row (software)]
- 观察 3:Front Row 是一个已停止使用的媒体中心软件
-
Round 4**:**
-
- 思考 4:苹果遥控器或者键盘功能键可以控制Front Row (software)。所以答案是键盘功能键。
- 观察 4:Finish[keyboard function keys]
可以看到,LLM 通过 ReAct 很好地解决了用户的问题,先思考,再通过 Action 获取外部信息,进行观察,循环往复,最终得到正确的答案。
入门实现
基于 ReAct 的原理,我们设计一个简单的案例:让 Agent 根据用户给定的话题搜索谷歌新闻并进行总结,主要使用了两个工具:谷歌新闻搜索和文本摘要总结。
ReAct 的提示词模板如下:
agent_prompt = """解决问答任务时,需要交错进行思考(Thought)、行动(Action)和观察(Observation)这三个步骤。思考环节可以对当前情况进行推理分析,行动环节分为以下四种类型:
1. Search[keywords]: 使用多个关键词进行搜索,多个关键词使用,分隔。
2. TTS[text]: 使用 TTS 技术将 text 转成语音。
3. Summary[text]: 对 text 进行摘要总结。
4. Finish[answer]: 返回答案并完成任务。
以下是一个示例。
Question: 总结最近的aigc热点新闻。
Thought 1: 我需要搜索最近跟aigc相关的热点新闻,具体关键词有aigc,llm,人工智能,gpt,大模型等
Action 1: Search[aigc,llm,人工智能,gpt,大模型]
Observation 1: AI for Science将人工智能与科学研究深度结合,推动科学发现和生活改变。Quora筹集7500万美元用于加速其AI聊天平台Poe的发展,主要投入AI开发者创作货币化。
Thought 2: 我需要对搜索结果进行摘要总结。
Action 2: Summary[AI for Science将人工智能与科学研究深度结合,推动科学发现和生活改变。Quora筹集7500万美元用于加速其AI聊天平台Poe的发展,主要投入AI开发者创作货币化。]
Observation 2: AI for Science 推动科学与生活创新。Quora筹集7500万美元加速AI平台Poe开发。
Thought 3: 我已总结出最近的热点新闻:AI for Science 推动科学与生活创新。Quora筹集7500万美元加速AI平台Poe开发。
Action 3: Finish[AI for Science 推动科学与生活创新。Quora筹集7500万美元加速AI平台Poe开发。]
"""
核心代码如下:
def react_agent(question, system_prompt):
user_query = f"Question: {question}\n"
print(user_query)
for i in range(1, 5):
# 设置停止词 Observation,让 LLM 生成每一轮的 thought 和 action
thought_action = llm(system_prompt, user_query + f"Thought {i}:", stop=[f"\nObservation {i}:"])
try:
thought, action = thought_action.strip().split(f"\nAction {i}: ")
except:
print('ohh...', thought_action)
thought = thought_action.strip().split('\n')[0]
action = llm(system_prompt, user_query + f"Thought {i}: {thought}\nAction {i}:", stop=[f"\n"]).strip()
# 根据 action 执行相应的操作,得到 observation
obs, done = step(action)
obs = obs.replace('\\n', '')
step_str = f"Thought {i}: {thought}\nAction {i}: {action}\nObservation {i}: {obs}\n"
user_query += step_str # 将之前的 思考-行动-观察 也加入
print(f"step {i} \n{user_query}\n")
if done:
break
if not done:
obs, done = step("Finish[]")
return obs
完整代码在 GitHub 仓库 https://github.com/ethan-funny/explore-llm-agents,后续会持续更新,比如增加 langchain 的实现等,敬请关注。
上面代码的输出如下:
LLM Agent 落地挑战
目前,LLM Agent 在落地过程中也存在不少问题和挑战,比如:
- LLM 的性能有待提升
- Agent 的服务成本过高
- Agent 的工程化问题
- 多模态能力还需加强
LLM 的性能有待提升
LLM 是 Agent 的大脑,因此它的性能直接决定了 Agent 的上限。具体表现在:
- 推理能力:当前 LLM 的推理/规划能力还是比较有限的,尽管它们已经展现出了一定的链式推理(CoT)能力。一些研究认为,LLM 缺乏真正的规划推理能力,其涌现能力实际上是上下文学习的结果。
- 上下文长度限制:LLM 的上下文长度受到 token 的限制,这会极大限制 Agent 的性能,随着多次交互的进行,Prompt 可能变得越来越长。
- 模型幻觉:LLM 在缺乏准确信息或上下文时可能会产生误导性的输出,因此可能会带偏 Agent 的输出。
Agent 服务成本过高
- 模型成本:LLM Agent 通常需要使用先进的大语言模型,如 gpt-4,但这些高级模型的使用成本相对较高,因为它们涉及昂贵的计算资源和维护费用。
- 多组件集成:LLM Agent 不仅依赖 LLM 本身,还需要结合记忆、工具使用等多个组件。这些额外组件的集成增加了整体的复杂性和成本。
- 性能评估和测试成本:为了确保LLM Agent的有效性和可靠性,需要对其性能进行持续的评估和测试。
Agent 工程化问题
- 推理速度:目前 LLM 的推理速度较慢,延迟过高,尤其是 Agent 需要多次迭代调用 LLM 的情况,推理速度是一个非常重要的因素,目前已经有一些针对 LLM 推理加速优化的方案了,比如量化、蒸馏和并行解码等,也许在未来不是个大问题
- 处理循环问题:在处理某些任务时,LLM Agent可能会陷入循环,这不仅影响了它的效率,还可能导致可靠性问题。这是由于Agent可能在尝试解决问题时反复执行相同的步骤,而没有有效地向解决方案前进。
- 资源管理:LLM模型的运行需要大量的计算资源。优化这些模型的性能,同时在硬件资源和运行成本方面保持高效,是实现LLM Agent工程化的一个关键挑战。
多模态能力
人类通过多模态的方式感知世界,而 LLM Agents 在视觉、听觉等多模态感知方面还存在局限,这影响了它们在复杂环境中的应用效果。
- 感知端的限制:LLM 本身不具备听觉、视觉的感知能力,因此 LLM Agents 原生主要处理文本输入,对于视觉输入和听觉输入的处理还比较有限,当然我们可以通过集成相关领域的模型来进行处理,如 gpt-4-vision、TTS 等
- 行动端的挑战:在分析和决策之后,Agent需要采取行动。文本输出是 LLMs 的基本能力,而如何有效利用工具,生成多模态输出(如语音、图像)则是未来发展的重点。
除了以上的问题,也还有很多其他问题,这些问题的解决和优化需要持续的研究和技术发展。随着技术的进步,这些挑战有望得到逐步解决。
思考
- 自主性与可控性的平衡:在提升 LLM Agents 的自主性和智能化程度的同时,如何确保人类对这些代理人的有效控制,以防止潜在的误操作或不当行为?
- 个性化与标准化之间的平衡:LLM Agents 在处理任务时应该多大程度上进行个性化定制,以适应不同用户的独特需求?同时,如何保持足够的标准化,以确保服务的一致性和可靠性?
- 决策透明度:LLM Agents 如何确保其决策过程是透明的?用户如何理解和信任这些智能体的决策逻辑,尤其是在涉及重要或敏感任务时?
参考资料
- LLM Powered Autonomous Agents,https://lilianweng.github.io/posts/2023-06-23-agent/
- Code Generation with AlphaCodium: From Prompt Engineering to Flow Engineering,https://arxiv.org/abs/2401.08500
- ReAct,https://react-lm.github.io/
- AI Agent:基于大模型的自主智能体,在探索 AGI 的道路上前进,https://file.iyanbao.com/pdf/6a60d-a5665fd8-9437-4edb-8571-6ab5c3f1091f.pdf
- Agents | 🦜️🔗 Langchain,https://python.langchain.com/docs/modules/agents/
- AI Agent目前应用落地有哪些局限性?- 知乎,https://www.zhihu.com/question/624354739
- 当大模型不是问题时,如何应对 LLM 的工程化落地挑战,https://cloud.tencent.com/developer/article/2327384
- AI Agent的千亿美金问题:如何重构10亿知识工作职业,掀起软件生产革命?
- 复旦NLP团队发布80页大模型Agent综述,一文纵览AI智能体的现状与未来
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









