







目录
最近leetcode上出了很多字典树的题。所谓字典树大概就是这个样子:

这种数据结构从顶部往下走,每个前缀有很多种不同的组合,这种应用在我们比如说网络上搜索东西的时候,自动补全用得多。
概念
introduction
树结构大家都很输入,先说一下多叉树的结构定义,其中num大于2;
struct TreeNode
{
int value;
TreeNode* children[num];
};而典型的字典树的结构如下:
struct TreeNode
{
bool isEnd;
TreeNode* children[26];
};其中bool值表示这个串是否结束
26个叉是因为字母表最多只有26个,表示这个点下面所有的子节点
值得注意的是,这个数据结构不会存储字符串本身,而是看这个节点的子节点是否为空来判断,然后bool值的作用在于判断一串字符串的结束。
扔个图意思一下
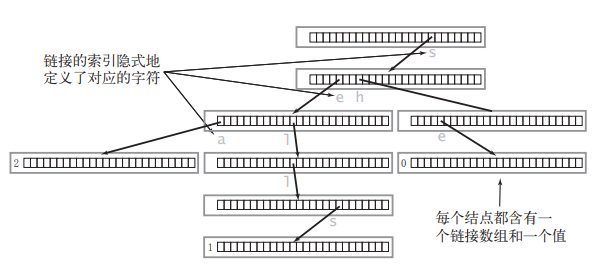
exmaple
比如我们建立一个表示apple的字典树,首先要建立头节点

在插入时候,首先插入a,除了第一个对应的指针不为空之外之外,其他的全部都是NULL,

然后该插入p我们看第二层,这一列是由第一层不为空的指出来的,同理,除了p对应的是不是空之外,其他全部都是空

第三列类推,直到最后一个字母e,标记为true表示一直到这里为止有个完整的字符串,这一层是全空

经典题
visualization
需要我们手动实现插入查找和前缀查找操作
class Trie {
public:
/** Initialize your data structure here. */
Trie() {
}
/** Inserts a word into the trie. */
void insert(string word) {
}
/** Returns if the word is in the trie. */
bool search(string word) {
}
/** Returns if there is any word in the trie that starts with the given prefix. */
bool startsWith(string prefix) {
}
};
/**
* Your Trie object will be instantiated and called as such:
* Trie* obj = new Trie();
* obj->insert(word);
* bool param_2 = obj->search(word);
* bool param_3 = obj->startsWith(prefix);
*/我们分开看:
首先看前缀树的定义:这个构造函数可以不写……,因为自动new出来的东西全部都是0,也就是false和NULL
struct ChainNode
{
bool isend;
ChainNode* children[26];
ChainNode():isend(false)
{
for(int i=0;i<26;i++)
{
children[i]=NULL;
}
};
};再看插入函数,这里记得要判断,不然后面的来了之后会覆盖掉原先的节点,会导致原先节点后续的node失效。
void insert(string&& word) {
ChainNode* cur=head;
for(int i=0;i<word.size();i++)
{
if (cur->children[word[i]-'a'] == NULL)
cur->children[word[i]-'a'] = new ChainNode();
cur=cur->children[word[i]-'a'];
}
cur->isend=true;
}再看查找函数:这里值得注意的是结束后记得判断是否真的到头了
bool search(string&& word) {
ChainNode* cur=head;
for(int i=0;i<word.size();i++)
{
if(cur->children[word[i]-'a']!=NULL)
{
cur=cur->children[word[i]-'a'];
}
else return false;
}
return cur->isend==true
}最后看前缀函数,唯一的区别就是最后不用判断是否到头就行
bool startsWith(string&& prefix) {
ChainNode* cur=head;
for(int i=0;i<prefix.size();i++)
{
if(cur->children[prefix[i]-'a']!=NULL)
{
cur=cur->children[prefix[i]-'a'];
}
else return false;
}
return true;
}提交看一下:

跑得比较快可能是因为我用了右值引用,跳过了复制直接移动。
enhancement
针对内存做进一步优化。
我们可以发现,当插入的string之间差异非常大的时候,创建了很多空节点,造成了内存的浪费,因此我们可以将数组改为哈希表的形式存储,比如这样:
struct ChainNode
{
bool isend;
unordered_map<int,ChainNode*> children;
};再提交瞅瞅:少了1mb左右,可喜可贺,可喜可贺。

延申题
introduction
单词查找2,大致意思是要在网格里面找出我们目标单词堆中可以组成单词的格子。
比如我们要在下面格子中要找出tae和oath和djskdkajd,最后返回值就是能够找到的单词的数组
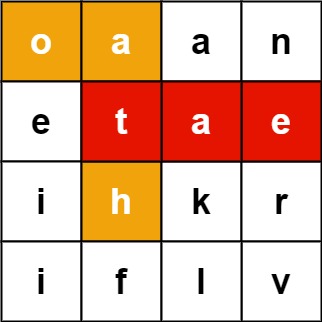
class Solution {
public:
vector<string> findWords(vector<vector<char>>& board, vector<string>& words) {
}
};第一次碰到这个题我直接上的暴力搜索,尽管用了哈希表去重但是最后一个测试案例还是超时歇逼了,放上我自己的代码:
constexpr int opt[4][2] = {1,0, 0,1, -1,0, 0,-1};
class Solution {
vector<string> res;
unordered_map<string,bool> isvisited;
int n;
int m;
public:
vector<string> findWords(vector<vector<char>>& board, vector<string>& words) {
n=board.size();
m=board[0].size();
if(n==1&&m==1)
{
for(auto& str:words)
{
if(str.size()==1&&str[0]==board[0][0]) return {str};
}
}
int pos=0;
for(auto& str:words)
{
for(int i=0;i<n*m;i++)
{
vector<vector<bool>> isvisted(n,vector(m,false));
traceback(isvisted,board,str,i,0);
}
}
return res;
}
void traceback(vector<vector<bool>>& isvisted,vector<vector<char>>& board,string& str,int pos,int p)
{
if(p==str.size())
{
if(isvisited[str]==false)
{
isvisited[str]=true;
res.push_back(str);
}
return;
}
int curn=pos/m;
int curw=pos-curn*m;
for(int i = 0; i < 4; ++i)
{
int newcurn=opt[i][0]+curn;
int newcurw=opt[i][1]+curw;
if(newcurn>=0&&newcurn<n&&newcurw>=0&&newcurw<m
&&isvisted[newcurn][newcurw]==false&&board[newcurn][newcurw]==str[p])
{
isvisted[newcurn][newcurw]=true;
traceback(isvisted,board,str,newcurn*m+newcurw,p+1);
isvisted[newcurn][newcurw]=false;
}
}
}
};真正的解法需要用到字典树。
我们先定义字典树结构体,这里跟传统字典树不同的是需要在字典树内部存储对应的string,因为方格里面每一个都可以停止,然后我们为了避免从头遍历一遍,直接在结构体存储,这样就能直接拿到对应的string
struct TrieNode {
string word;
unordered_map<char,TrieNode *> children;
TrieNode() {
this->word = "";
}
};定义插入函数,这里定义是否存在,利用count函数
void insertTrie(TrieNode * root,const string & word) {
TrieNode * node = root;
for (auto c : word){
if (!node->children.count(c)) {
node->children[c] = new TrieNode();
}
node = node->children[c];
}
node->word = word;
}
同样要定义四个前进的方向,加个哈希表去重,定义输出结构体
constexpr int dirs[4][2] = {1,0, 0,1, -1,0, 0,-1};
unordered_map<string,bool> pool;
vector<string> ans;自然而然我们的函数就能写成这样,这里判断1是因为如果只有一格下面的遍历算法是无法起作用的,因此要单独拎出来说,剩下的就是简单的遍历了。
vector<string> findWords(vector<vector<char>> & board, vector<string> & words) {
TrieNode * root = new TrieNode();
for (auto & word: words){
insertTrie(root,word);
}
if(board.size()==1&&board[0].size()==1)
{
for(auto& str:words)
{
if(str.size()==1&&str[0]==board[0][0]) return {str};
}
}
for (int i = 0; i < board.size(); ++i) {
for (int j = 0; j < board[0].size(); ++j) {
dfs(board, i, j, root);
}
}
return ans;
}剩下的我们要实现dfs函数,这里用字典树的目的是为了剪枝,就是说如果下面都没有就不要再继续找了,也正是因为如此降低了去四处查找后再确定是否没有的时间消耗。
之所以用‘#’覆盖原先位置的原因是为了保证不会走回去
void dfs(vector<vector<char>>& board, int x, int y, TrieNode * root) {
char ch = board[x][y];
if (!root->children.count(ch)) {
return;
}
root = root->children[ch];
if (root->word.size() > 0) {
if(pool[root->word]==false)
{
pool[root->word]=true;
ans.emplace_back(root->word);
}
}
board[x][y] = '#';
for (int i = 0; i < 4; ++i) {
int nx = x + dirs[i][0];
int ny = y + dirs[i][1];
if (nx >= 0 && nx < board.size() && ny >= 0 && ny < board[0].size()) {
if (board[nx][ny] != '#') {
dfs(board, nx, ny, root);
}
}
}
board[x][y] = ch;
}上述的方法还是有点问题,问题就在于还是太慢了;

enhancement
我们可以换一种方式定义可以将时间缩小2个数量级:
这里除了定义插入add之外还定义了删除和查找下一个。
constexpr int dir[4][2] = {1,0, 0,1, -1,0, 0,-1};
class dt{
public:
unordered_map<char, dt*> next;
string str;
void add(const string& s){
dt* p = this;
for(char c: s) p = p->next[c] = p->next.count(c) ? p->next[c] : new dt;
p->str = move(s);
}
inline void del(char c){ next.erase(c);}
inline dt* getNext(char c){ return next.count(c) ? next[c] : nullptr; }
};再定义查找函数,里面我们用来函数封装以及lambda,位置交换用swap替代了直接赋值防止重复访问
注意这里的del调用时机,如果下一个是空那么就说明我们到头了,到头了就一定匹配到了,那么我们就删除这个点,防止再次匹配到,这样就不用哈希去重了。
vector<string> findWords(vector<vector<char>>& board, vector<string>& words) {
for(auto&& s: words) tree.add(s);
int m = board.size(), n = board[0].size();
vector<string> ans;
function<void(int, int, dt*)> dfs = [&](int x, int y, dt* root){
dt* nextTree = root->getNext(board[x][y]);
if(nextTree == nullptr) return;
if(nextTree->str.size()) ans.emplace_back(move(nextTree->str));
char save = 0;
swap(save, board[x][y]);
for(int i = 0; i < 4; ++i){
int nx = x + dir[i][0], ny = y + dir[i][1];
if(nx >= 0 && ny >= 0 && nx < m && ny < n && board[nx][ny])
dfs(nx, ny, nextTree);
}
swap(save, board[x][y]);
if(nextTree->next.empty()) root->del(board[x][y]);
};
for(int i = 0; i < m; ++i)
for(int j = 0; j < n; ++j)
dfs(i, j, &tree);
return ans;
}再提交看看?

















 1718
1718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











