







什么是BN(Batch Normalization)?
在之前看的深度学习的期刊里,讲到了BN,故对BN做一个详细的了解。在网上查阅了许多资料,终于有一丝明白。
什么是BN?
2015年的论文《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》阐述了BN算法,很多论文都会引用这个算法,BN大量被用于网络训练,可见其强大。
有很多文章已经对BN的公式和流程都做了非常详细的介绍。
http://blog.csdn.net/hjimce/article/details/50866313
这里主要一些我觉得我迟迟不能理解的地方做一些记录。
1 BN 概述
对于BN来说我最开始的疑问就是,BN是什么?BN有什么用?BN放在网络模型的哪个位置?BN的作用是如何体现的?
1.1BN是什么?
就像激活函数层、卷积层、全连接层、池化层一样,BN也属于网络的一层。BN大的来说就是归一化层代替掉了LRN ( Local Response Normalization) 局部响应归一化层。详细解释可看
https://blog.csdn.net/u014296502/article/details/78839881
1.2BN有什么用?
对于之前的归一化来说,我们强行把特征做的均值为0,标准差为1,可以
通过将数据标准化,能够加速权重参数的收敛,有时可以舍弃作用不大的dropout。但一般归一化的强制又会有一定程度上破坏特征分布。
1.3BN的作用是怎么来的?
BN的关键公式:
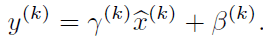
看到公式我第一个疑问就是γ与β的值该怎么来。直到我看到了
VAR(方差)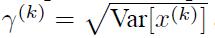
E(期望)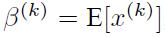
我就大致明白了文献中的变换重构,引入了可学习参数γ、β。
在前向传播中记录下来γ、β的值。
最重要的就是可学习参数的提出,还有许多具体公式运算都体现在文献中,以及很多资料都有分析。














 561
561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









