






背景
近期涉及到spark属地化相关工作,原有的cdh部署模式明显不适合,于是调研了spark-operator&volcano on k8s部署
部署流程
1、安装volcano
volcano安装:
kubectl apply -f https://raw.githubusercontent.com/volcano-sh/volcano/master/installer/volcano-development.yaml
master可以替换为指定的标签或者分支(比如,release-1.5分支表示最新的v1.5.x版本,v1.5.1标签表示v1.5.1版本)以安装指定的Volcano版本。
2、安装spark-operator
$ helm repo add spark-operator https://googlecloudplatform.github.io/spark-on-k8s-operator
查看版本与spark对应关系(版本不匹配会引发各种奇异的问题)
helm search repo spark-operator/spark-operator --versions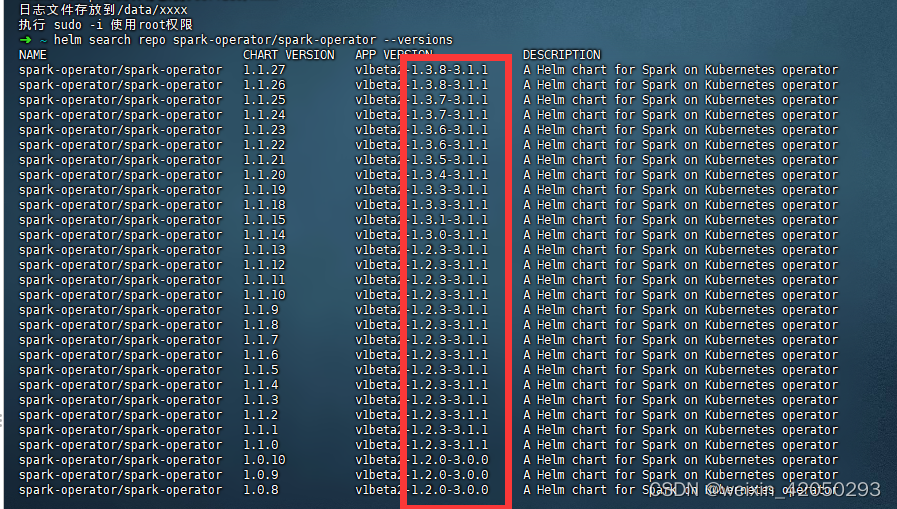
选择合适版本安装
helm install my-release spark-operator/spark-operator --namespace spark-operator --create-namespace --version 1.1.27 --set webhook.enable=true其中,my-release为自定义命名, webhook.enable需开启才能使用文件挂载功能(volumes)。
确认安装状态
kubectl get po -nspark-operator准备运行任务角色
apiVersion: v1
kind: ServiceAccount
metadata:
name: spark
namespace: default
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
namespace: default
name: spark-role
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["*"]
- apiGroups: [""]
resources: ["services"]
verbs: ["*"]
- apiGroups: [""]
resources: ["configmaps","persistentvolumes","persistentvolumeclaims"]
verbs: ["*"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: spark-role-binding
subjects:
- kind: ServiceAccount
name: spark
namespace: default
roleRef:
kind: ClusterRole
name: spark-role
apiGroup: rbac.authorization.k8s.io3、基础镜像准备
spring-operator提供的镜像国内无法拉取,因此需要自行构建基础spark镜像。
且Spark官方spark-docker只提供了3.3及以上构建文件,因此需要在此基础上修改相应spark版本,启动类等参数。结合Spark-operator项目中/spark-docker部分以及spark-docker综合后,得到以下部署文件:Dockerfile、entrypoint.sh、spark.tgz、spark.tgz.asc。
自行下载spark安装包:
Index of /dist/spark/spark-3.1.1
下载其包含hadoop组件的压缩包,否则无法正常运行
Dockerfile参考:
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
FROM eclipse-temurin:8-jre-focal
ARG spark_uid=185
RUN groupadd --system --gid=${spark_uid} spark && \
useradd --system --uid=${spark_uid} --gid=spark spark
RUN set -ex && \
apt-get update && \
ln -s /lib /lib64 && \
apt install -y gnupg2 wget bash tini libc6 libpam-modules krb5-user libnss3 procps net-tools gosu && \
apt install -y r-base r-base-dev && \
mkdir -p /opt/spark && \
mkdir -p /opt/spark/examples && \
mkdir -p /opt/spark/work-dir && \
touch /opt/spark/RELEASE && \
chown -R spark:spark /opt/spark && \
rm /bin/sh && \
ln -sv /bin/bash /bin/sh && \
echo "auth required pam_wheel.so use_uid" >> /etc/pam.d/su && \
chgrp root /etc/passwd && chmod ug+rw /etc/passwd && \
rm -rf /var/cache/apt/* && \
rm -rf /var/lib/apt/lists/*
# Install Apache Spark
# https://downloads.apache.org/spark/KEYS
ENV SPARK_TGZ_URL=https://archive.apache.org/dist/spark/spark-2.4.0/spark-2.4.0-bin-without-hadoop.tgz \
SPARK_TGZ_ASC_URL=https://archive.apache.org/dist/spark/spark-2.4.0/spark-2.4.0-bin-without-hadoop.tgz.asc \
GPG_KEY=80FB8EBE8EBA68504989703491B5DC815DBF10D3
COPY spark.tgz.asc /
COPY spark.tgz /
RUN set -ex; \
export SPARK_TMP="$(mktemp -d)"; \
cd $SPARK_TMP; \
#mv /spark.tgz.asc $SPARK_TMP; \
mv /spark.tgz $SPARK_TMP; \
#export GNUPGHOME="$(mktemp -d)"; \
#gpg --keyserver hkps://keys.openpgp.org --recv-key "$GPG_KEY" || \
#gpg --keyserver hkps://keyserver.ubuntu.com --recv-keys "$GPG_KEY"; \
#gpg --batch --verify spark.tgz.asc spark.tgz; \
#gpgconf --kill all; \
#rm -rf "$GNUPGHOME" spark.tgz.asc; \
\
tar -xf spark.tgz --strip-components=1; \
chown -R spark:spark .; \
mv jars /opt/spark/; \
mv bin /opt/spark/; \
mv sbin /opt/spark/; \
#mv kubernetes/dockerfiles/spark/decom.sh /opt/; \
mv examples /opt/spark/; \
mv kubernetes/tests /opt/spark/; \
mv data /opt/spark/; \
mv R /opt/spark/; \
cd ..; \
rm -rf "$SPARK_TMP";
COPY entrypoint.sh /opt/
ENV SPARK_HOME /opt/spark
ENV R_HOME /usr/lib/R
WORKDIR /opt/spark/work-dir
RUN chmod g+w /opt/spark/work-dir
#RUN chmod a+x /opt/decom.sh
RUN chmod a+x /opt/entrypoint.sh
ENTRYPOINT [ "/opt/entrypoint.sh" ]
entrypoint.sh参考:
#!/bin/bash
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# echo commands to the terminal output
set -ex
# Check whether there is a passwd entry for the container UID
myuid=$(id -u)
mygid=$(id -g)
# turn off -e for getent because it will return error code in anonymous uid case
set +e
uidentry=$(getent passwd $myuid)
set -e
# If there is no passwd entry for the container UID, attempt to create one
if [ -z "$uidentry" ] ; then
if [ -w /etc/passwd ] ; then
echo "$myuid:x:$myuid:$mygid:${SPARK_USER_NAME:-anonymous uid}:$SPARK_HOME:/bin/false" >> /etc/passwd
else
echo "Container ENTRYPOINT failed to add passwd entry for anonymous UID"
fi
fi
SPARK_CLASSPATH="$SPARK_CLASSPATH:${SPARK_HOME}/jars/*"
env | grep SPARK_JAVA_OPT_ | sort -t_ -k4 -n | sed 's/[^=]*=\(.*\)/\1/g' > /tmp/java_opts.txt
readarray -t SPARK_EXECUTOR_JAVA_OPTS < /tmp/java_opts.txt
if [ -n "$SPARK_EXTRA_CLASSPATH" ]; then
SPARK_CLASSPATH="$SPARK_CLASSPATH:$SPARK_EXTRA_CLASSPATH"
fi
if ! [ -z ${PYSPARK_PYTHON+x} ]; then
export PYSPARK_PYTHON
fi
if ! [ -z ${PYSPARK_DRIVER_PYTHON+x} ]; then
export PYSPARK_DRIVER_PYTHON
fi
# If HADOOP_HOME is set and SPARK_DIST_CLASSPATH is not set, set it here so Hadoop jars are available to the executor.
# It does not set SPARK_DIST_CLASSPATH if already set, to avoid overriding customizations of this value from elsewhere e.g. Docker/K8s.
if [ -n "${HADOOP_HOME}" ] && [ -z "${SPARK_DIST_CLASSPATH}" ]; then
export SPARK_DIST_CLASSPATH="$($HADOOP_HOME/bin/hadoop classpath)"
fi
if ! [ -z ${HADOOP_CONF_DIR+x} ]; then
SPARK_CLASSPATH="$HADOOP_CONF_DIR:$SPARK_CLASSPATH";
fi
if ! [ -z ${SPARK_CONF_DIR+x} ]; then
SPARK_CLASSPATH="$SPARK_CONF_DIR:$SPARK_CLASSPATH";
elif ! [ -z ${SPARK_HOME+x} ]; then
SPARK_CLASSPATH="$SPARK_HOME/conf:$SPARK_CLASSPATH";
fi
case "$1" in
driver)
shift 1
CMD=(
"$SPARK_HOME/bin/spark-submit"
--conf "spark.driver.bindAddress=$SPARK_DRIVER_BIND_ADDRESS"
--deploy-mode client
"$@"
)
;;
executor)
shift 1
CMD=(
${JAVA_HOME}/bin/java
"${SPARK_EXECUTOR_JAVA_OPTS[@]}"
-Xms$SPARK_EXECUTOR_MEMORY
-Xmx$SPARK_EXECUTOR_MEMORY
-cp "$SPARK_CLASSPATH:$SPARK_DIST_CLASSPATH"
org.apache.spark.executor.CoarseGrainedExecutorBackend
--driver-url $SPARK_DRIVER_URL
--executor-id $SPARK_EXECUTOR_ID
--cores $SPARK_EXECUTOR_CORES
--app-id $SPARK_APPLICATION_ID
--hostname $SPARK_EXECUTOR_POD_IP
--resourceProfileId $SPARK_RESOURCE_PROFILE_ID
)
;;
*)
echo "Non-spark-on-k8s command provided, proceeding in pass-through mode..."
CMD=("$@")
;;
esac
# Execute the container CMD under tini for better hygiene
exec /usr/bin/tini -s -- "${CMD[@]}"
构建镜像
docker build -t spark_3.1.1 . 4、测试
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: spark-pi
namespace: default
spec:
type: Scala
mode: cluster #选择模式
image: "gcr.io/spark-operator/spark:v3.0.0" #修改为自己构建的镜像
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.12-3.1.1.jar"
sparkVersion: "3.1.1"
batchScheduler: "volcano" #Note: the batch scheduler name must be specified with `volcano`
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 1
coreLimit: "1200m"
memory: "512m"
labels:
version: 3.1.1
serviceAccount: spark
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 3.1.1
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"查看任务状态
$ kubectl apply -f spark-pi.yaml
$ kubectl get SparkApplication














 2066
2066











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









