







★ CART回归原理:
CART回归树是二叉树,它的损失函数是最小均方差(MSE):
①
其中,N是样本数,
是我们的估计值。我们把损失函数L对
②
解②得:
③
因此我们要用这个算法预测一个值,取y的平均值是一个最佳的选择。
既然CART是一个二叉树做回归,那么它会在切分点s出把数据集分为两部分,并根据MSE作为损失函数使之最小,其数学描述是:
④
上式中,j是最优切分变量,s是切分点。
由公式④看出,第一个切分点把数据分成了两部分
,而
数据集又会被一个切分点分成两部分,
也是如此,直至满足条件才会停止切分。公式④的
就是每个被切分的数据集的最优估计值(由公式③知,这个值是切分后的数据集的平均值)。
★ 举个栗子:
x 1 2 3 4 5 6 7 8 9 10 y 5.56 5.7 5.91 6.4 6.8 7.05 8.9 8.7 9 9.05 1. 选择最优切分变量j与最优切分点s:
在本数据集中,只有一个变量,因此最优切分变量自然是x。接下来我们考虑9个切分[1.5,2.5,3.5,4.5,5.5,6.5,7.5,8.5,9.5]
你可能会问,为什么会带小数点呢?类比于篮球比赛的博彩,倘若两队比分是96:95,而盘口是“让1分 A队胜B队”,那A队让1分之后,到底是A队赢还是B队赢了?所以我们经常可以看到“让0.5分 A队胜B队”这样的盘口。在这个实例中,也是这个道理。
2. 我们开始根据公式④,来对数据集进行切分:
首先尝试计算第一个切分点 s=1.5,s=1.5把数据集分成了两部分:
x 1 y 5.6
x 2 3 4 5 6 7 8 9 10 y 5.7 5.91 6.4 6.8 7.05 8.9 8.7 9 9.05 两部分的最优估计值(平均值)
。同理,计算切分点s=2.5时的
s 1.5 2.5 3.5 4.5 5.5 6.5 7.5 8.5 9.5 5.56 5.63 5.72 5.89 6.07 6.24 6.62 6.88 7.11 7.5 7.73 7.99 8.25 8.54 8.91 8.92 9.03 9.05 现在我们计算损失函数的值,比如在切分点s=1.5处:
同样计算出切分点在s = 2.5,...,9.5时的损失函数,汇总成表格是:
s 1.5 2.5 3.5 4.5 5.5 6.5 7.5 8.5 9.5 L(s) 15.72 12.07 8.36 5.78 3.91 1.93 8.01 11.73 15.74 由此我们可以看出,在切分点s=6.5时,损失函数最小,因此s=6.5是最佳切分点,它把数据集切分成两部分:
和
3. 然后我们再对这两个子区域继续上述的切分,比如再对
区域进行切分,
x 1 2 3 4 5 6 y 5.56 5.7 5.91 6.4 6.8 7.05
s 1.5 2.5 3.5 4.5 5.5 5.56 5.63 5.72 5.89 6.07 6.37 6.54 6.75 6.93 7.05 计算出每个切分点s对应的损失函数值:
s 1.5 2.5 3.5 4.5 5.5 L(s) 1.3087 0.754 0.2771 0.4368 1.0644 由此我们看出,子区域
也会找到最佳切分点,也会把
4. 满足条件,停止切分,构造树:
假如上述例子生成了三个区域后停止切分(即
我们的切分点是 s =[3.5,6.5],将整个数据集分成三个区域,我们再计算每个区域的最优估计值
(即每个子区域的平均值),汇总成表格:
R 5.72 6.75 8.91 数学描述是:
画出图来:

★ 代码实践:
✿ 下面代码是我对<<机器学习实战>>代码的小小改动,并把改动和不理解之处提出来和大家讨论:
1. 改动 loadDataSet() 函数:
原程序使用了map函数把列表中的数据由字符串型转化为float类型,可是python3已经改了,map返回的是迭代器,所以再map执行后需使用list()函数转换成具体的float数据。
2. 改动 binSplitDataSet() 函数:
该书中说大于特征值的为左子树,小于等于的为右子树,可是根据我们的习惯(包括画图展示),都是小于等于的在左边,大于的在右边,因此我将程序的 binSplitDataSet() 改为小于等于特征值为左子树,大于特征值为右子树,这也是为了我们做图方便。
3. 对 regLeaf() 和 regErr() 的疑问:
这两个函数都是取的样本的最后一个特征来进行求均值或者方差,这就默认了我们的数据样本只能是(x,y)这种二维形式,这里也就是默认了x为最优切分变量,y为输出变量,这里也可以从函数 chooseBestSplit () 中的遍历最优切分变量的时候看出来(for featIndex in range(n-1)),正好跟我们上面举的例子是一样的。
4. 对 chooseBestSplit() 中三个停止条件的疑问:
三个停止条件是: (1) if len(set(dataSet[:,-1])) == 1: # 停止切分的条件之一
return None, leafType(dataSet)(2) if (S-bestS) < tols: # 如果切分之前的损失减切分之后的损失小于1,那么就是切分前
return None,leafType(dataSet) #后损失减小的太慢,停止.它是主要的停止条件(3) if (shape(mat0)[0] < tolN) or (shape(mat1)[0] <tolN): # 如果任意子区域的样本数小于4,停止
return None, leafType(dataSet)对于(3)停止条件,个人感觉此停止条件没用,因为上面选择切分点的时候就把这个情况删除了,请看选择切分点时:
if (shape(mat0)[0] < tolN) or (shape(mat1)[0] < tolN): # 如果任意子区域的叶子节点小于4个,跳过此切分点
continue5. 对 chooseBestSplit() 的理解:
此函数返回值有两种情况:
(1) 如果满足继续切分条件,那么该函数会返回最优切分变量的下标(由于此程序默认了数据集只有两个特征(x,y),因此这里最优变量只能是x)和最优切分点s。
(2) 如果满足了停止条件,那么该函数返回None和该子区域的最优估计值(也就是平均值,这个可由本文开头的推导得出为什么要求平均值),也就是书中提到的叶子节点。
6. 画图的一些小技巧:
(1) 我们通过 creatTree() 函数得到了回归树,比如此数据集产生的回归树是:
{'spInd': 0, 'spVal': 0.39435, 'left': {'spInd': 0, 'spVal': 0.197834, 'left': -0.023838155555555553, 'right': 1.0289583666666666}, 'right': {'spInd': 0, 'spVal': 0.582002, 'left': 1.980035071428571, 'right': {'spInd': 0, 'spVal': 0.797583, 'left': 2.9836209534883724, 'right': 3.9871632}}}
我们可以看到‘spVal’的键值就是最优切分点,'right'或者'left‘对应的就是最优预测值c。
注意:画图时最优切分点的顺序我们不会在意,但是最优预测值的顺序我们必须搞清楚,书中的最优预测值的顺序就是我们画阶梯图时的y的值的顺序(主要还是得益于第2步的 binSplitDataSet() 的改动)
(2) 由(1)知,我们需要保证最优预测值的顺序不变(也就是把Tree字典中的最优预测值完整的按顺序的提出来),于是我们想到了把Tree字典转化为字符串,然后通过正则表达式把最优分点和最优估计值分别取出来。
观察这个回归树Tree,发现最优估计值在'right'或者'left‘后面,所以我们应用了正则表达式的 “|“来实现或操作,匹配数字我们使用了(-?\d+\.?\d*)来实现。
(3) 我们的回归树是阶梯图形,因此我们使用 step() 函数来画。
from numpy import * import matplotlib.pyplot as plt import matplotlib import re def loadDataSet(fileName): # 加载数据集 dataMat = [] fr = open(fileName) for line in fr.readlines(): curLine = line.strip().split('\t') fltLine = list(map(float,curLine)) # 加上list就是完整功能了,不然只用map会生成内存地址 dataMat.append(fltLine) dataMat = array(dataMat) # 转化为array数组,便于计算 return dataMat def binSplitDataSet(dataSet, feature, value): # 把数据集根据变量(特征)feature按照切分点value分为两类 mat0 = dataSet[nonzero(dataSet[:,feature] <= value)[0], :] # 大于成为左子树,实际图形却在右边,为了画图方便我把它改了 mat1 = dataSet[nonzero(dataSet[:,feature] > value)[0],:] return mat0, mat1 def regLeaf(dataSet): # 计算平均值,负责生成叶子节点,叶子节点根据公式不就是求所在子区域的平均值 return mean(dataSet[:,-1]) def regErr(dataSet): # 方差×个数 = 每个点与估计值的差的平方和,这是根据损失函数公式来的 return var(dataSet[:,-1]) * shape(dataSet)[0] def chooseBestSplit(dataSet, leafType=regLeaf, errType=regErr, ops=(1,4)): tols = ops[0] # 最小下降损失是1 tolN = ops[1] # 最小样本数是4 if len(set(dataSet[:,-1])) == 1: # 停止切分的条件之一 return None, leafType(dataSet) m,n = shape(dataSet) S = errType(dataSet) bestS = inf # 最优切分点的误差 bestIndex = 0 # 最优切分变量的下标 bestValue = 0 # 最优切分点 for featIndex in range(n-1): # 遍历除最后一列的其他特征,我们的数据集是(x,y),因此这里只能遍历x for splitVal in set(dataSet[:,featIndex]): # splitVal是x可能去到的每一个值作为切分点 mat0, mat1 = binSplitDataSet(dataSet, featIndex, splitVal) # 根据切分点划分为两个子区域 if (shape(mat0)[0] < tolN) or (shape(mat1)[0] < tolN): # 如果两个子区域的叶子节点小于4个,跳过此切分点 # print("内层判别小于4___________________") # print(shape(mat0)[0],shape(mat1)[0]) continue newS = errType(mat0) + errType(mat1) # 计算两部分的损失函数 if newS < bestS: # 如果损失函数小于最优损失函数 bestIndex = featIndex # 最优切分变量保存起来 bestValue = splitVal # 最优切分点保存起来 bestS = newS # 最优损失函数保存起来 if (S-bestS) < tols: # 如果切分之前的损失减切分之后的损失小于1,那么就是切分前后损失减小的太慢,停止.它是主要的停止条件 return None,leafType(dataSet) mat0,mat1 = binSplitDataSet(dataSet, bestIndex, bestValue) # 按照最优切分点分成两个区域 if (shape(mat0)[0] < tolN) or (shape(mat1)[0] <tolN): # 如果任何一个子区域的样本数小于4个,停止切分 # print("外层判断切分样本数小于4******************") # 个人感觉此判断没用,因为上面选择切分点的时候就把这个情况删除了 return None, leafType(dataSet) return bestIndex,bestValue def createTree(dataSet,leafType=regLeaf, errType=regErr, ops=(1,4)): feat,val = chooseBestSplit(dataSet, leafType, errType, ops) # 最优切分点切分 if feat == None: # 如果是叶子节点,那么val是那个数据集的平均值,即c # print("NOne/执行了",val) return val # print("没执行",val) retTree = {} retTree['spInd'] = feat # 最优切分变量(特征)的下标值 retTree['spVal'] = val # 最优切分点s,假如执行到这里,说明找到了最优切分点,将继续切分 lSet, rSet = binSplitDataSet(dataSet, feat, val) # 切分成两个子区域,lSet是大于切分点的,相当于我们图形的右边 retTree['left'] = createTree(lSet, leafType, errType, ops) # 左子树继续切分 retTree['right'] = createTree(rSet, leafType, errType, ops) # 右子树继续切分 return retTree def drawPicture(dataSet,x_division, y_estimate): # x_division是切分点,y_estimate是估计值 matplotlib.rcParams["font.sans-serif"]=["simhei"] # 显示中文 matplotlib.rcParams['axes.unicode_minus'] = False fig = plt.figure() # 创建画布 ax = fig.add_subplot(111) points_x = dataSet[:,0] # 因为咱们的数据是(x,y)二维图形,x是切分变量,y是估计变量,可参照博客中的具体实例加以理解 points_y = dataSet[:,1] x_min = min(points_x) # 创造切分区域,所以需要x的最小值和最大值,从而构造区域 x_max = max(points_x) y_estimate.append(y_estimate[-1]) ax.step([x_min]+list(x_division)+[x_max],y_estimate,where='post',c='green',linewidth=4,label="最优估计值") # 画最优估计值 ax.scatter(points_x, points_y,s=30,c='red',marker='s',label="样本点") # 画样本点 ax.legend(loc=4) # 添加图例 # ax.grid() # 添加网格 ax.set_yticks(y_estimate) # 设置总坐标刻度 ax.set_xlabel("x") ax.set_ylabel("y") plt.show() if __name__ == '__main__': myData = loadDataSet('/home/zhangqingfeng/test/cart_tree.txt') retTree = createTree(myData) # 创建树 retTree_str = str(retTree) # 转化为字符串好用正则 print(retTree_str) x_division_str = "'spVal': (\d+\.?\d*)" # 正则提取出切分节点 y_estimate_str = "'left': (-?\d+\.?\d*)|'right': (-?\d+\.?\d*)" # 正则表达式取出来叶子节点数据,即最优估计值 x_division = re.compile(x_division_str).findall(retTree_str) y_estimate = re.compile(y_estimate_str).findall(retTree_str) x_division = sort(list(map(float,x_division))) # 切分点排序,因为我们画图都是从左往右画,正好对应下面的最优估计值c y_estimate = [float(x) for y in y_estimate for x in y if x != ''] # 估计值的顺序不能乱,树中的是什么顺序就是什么顺序 print(x_division) print(y_estimate) drawPicture(myData,x_division,y_estimate) # 画图,画出样本点和最优估计值
★ 运行效果:



★ 数据集: https://github.com/zhangqingfeng0105/Machine-Learn/blob/master/cart_tree/cart_tree.txt
★ 剪枝处理
为了有效改观回归树的过拟合,我们对树进行后剪枝。它的方法是把两个叶子节点合并成一个叶子(即求两个叶子的平均值作为一个新叶子,看起来就像把叶子剪了一样),分别计算两个叶子合并前的误差和合并后的误差,如果合并后的误差更小,那么进行剪枝,用一个图来说明:
继续合并:
剪枝的过程是:
从树的最左边最下边开始寻找在同一个子节点上的两个叶子,求他俩平均值,计算误差,其实在同一节点上的两个叶子就是该节点对应的子数据集再次被切分成左右两个区域,左区域的平均值是左叶子,右区域的平均值是右叶子,因此没剪这两个叶子之前的误差就是:
(左区域数据 - 左叶子)的平方 + (右区域数据 - 右叶子)的平方
合并两个叶子之后的误差就是:
(两个叶子上面的子节点对应的数据集的数据 - 两个叶子的平均值)的平方
然后就比较这两个误差的大小,合并后的误差小就进行剪枝,否则就不剪枝。就这样从左往右还得找同一节点的两个叶子进行合并,再进行误差比较,这一过程可以用递归函数来实现。


★ 剪枝的代码:
✿ 剪枝代码的理解:
(1.) 首先遍历顺序是这样:
(2.) 塌陷处理函数 getMean()
因为我们用训练集生成的回归树的子节点(spVal)来切分测试集,有可能会出现把测试集的某个子区域
按照某一子节点切分成左右两个区域(
)的时候,这两个区域某一个是空集,那么 原本该子节点下面的左子树对应该子区域(
),右子树对应右部分(
),现在某一部分是空集了,这样切分就不成立了,总不能对空集还切吧,还求平均值吧,所以现在进行塌陷处理,即把以该子节点为根的下面的所有子树合并成一叶子,如图:
(3.) prune() 函数的理解:
prune() 函数有4个return 退出,如果 return getMean() 和 return treeMean 则说明进行剪枝了,后程序末尾有两个 return tree ,第一个return tree是合并之后的误差比没合并之前的误差还大,那么就不要进行剪枝了,因此它返回的不再是一个具体数,而是一个tree子树(这个tree子树就是该两个叶子的父节点作为根的子树),因为返回一个tree子树了,那么程序继续往下进行,它一定不满足: if not isTree(tree['left']) and not isTree(tree['right']): ( 这个条件是判断 left 和 rignt 都是叶子),所有程序会跳到第二个 return tree ,而这个tree 就是 上面说的子节点的再上一个父节点,如图:
返回到第二个tree之后,再按咱们上面(1.) 说的顺序继续遍历剪枝。
def isTree(obj): return (type(obj).__name__ == 'dict') # 判断是叶子还是树 def getMean(tree): if isTree(tree['left']): tree['left'] = getMean(tree['left']) if isTree(tree['right']): tree['right'] = getMean(tree['right']) return (tree['left'] + tree['right'])/2.0 def prune(tree, testData): # 剪枝 if shape(testData)[0] == 0: # 塌陷处理,这时某一个子节点把对应的子区域分成两部分,但是某一部分却是空集,因为这是测试集不是训练集,出现这种情况是正常的,这时把该子节点下面的所有叶子求平均值(当然先合并同一个节点的两个叶子),最后合并成了两个叶子,再取其平均值。 return getMean(tree) if (isTree(tree['left']) or isTree(tree['right'])): lSet, rSet = binSplitDataSet(testData,tree['spInd'],tree['spVal']) if isTree(tree['left']): tree['left'] = prune(tree['left'], lSet) # 递归左子树 if isTree(tree['right']): tree['right'] = prune(tree['right'], rSet) # 递归右子树 if not isTree(tree['left']) and not isTree(tree['right']): lSet, rSet = binSplitDataSet(testData, tree['spInd'], tree['spVal']) errorNoMerge = sum(power(lSet[:,-1] - tree['left'],2)) + sum(power(rSet[:,-1] - tree['right'],2)) treeMean = (tree['left'] + tree['right'])/2.0 errorMerge = sum(power(testData[:,-1] - treeMean,2)) if errorMerge < errorNoMerge: # 比较误差 print("merging") return treeMean # 满足剪枝就返回两个叶子平均值 else: return tree # 不满足剪枝就返回该节点子树 else: return tree # 该节点不满足剪枝,那么返回到该节点的上一个节点继续遍历,如果此时yiijng遍历结束那么再返回上一个节点



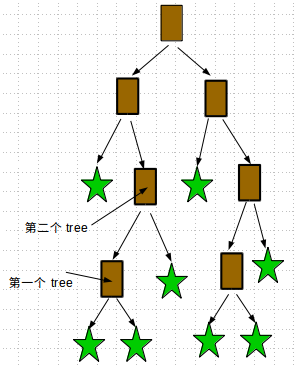
★ 画出决策树(注解树),代码
✿ 画注解树代码的理解:
(1.) getTreeLeafNum () 函数求叶子数:
当tree[key]还是树的时候,进行递归,当tree[key]不是树(即是叶子)的时候,叶子计数器numLeafs 加一,当遍历完所有子树的时候,返回叶子计数器,我们声明叶子计数器numLeafs是全局变量,当每次递归发现是叶子的时候,他就加一,如果这里用局部变量,每次递归调用本身的时候它都会被初始化,计数不准确。
如果有些小伙伴有强迫症,就是不使用全局变量,那么求叶子我给出第二个版本,使用局内变量:
def getTreeLeafNum(tree): # 第二个版本 key_list = ["left","right"] total_leaf = 0 for key in key_list: if isTree(tree[key]): # 如果还是子树,那么他不算叶子,应该用0加 child_tree_leaf_num = 0 + getTreeLeafNum(tree[key]) else: child_tree_leaf_num = 1 # 如果是叶子那么就加1 total_leaf = total_leaf + child_tree_leaf_num # 把叶子数保存起来 return total_leaf第二个版本其实不如第一个版本好理解,这也是我推荐第一个版本的原因,因为第二个版本你得理解python递归函数中的变量传参机制,这里 total_leaf = 0 是不可变对象,所以它是值传递(即提供副本)。
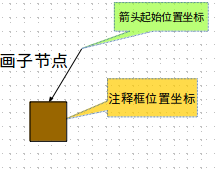
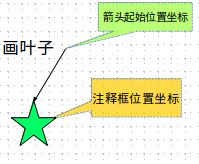
(2.) plotNode()和plotLeaf()分别画子节点和叶子:
这里注意注释函数annotate()的参数,annotate(str=“注释内容",xy=(注释箭头的起始位置),xytext=(注释框的位置),arrowprops="箭头类型", bbox={注释框的风格颜色形状等})
当只需要注释框,不需要箭头的时候,可以让 xy=xytext,这样注释框的位置和箭头起始位置在同一点,就不会显示箭头了。我们这里画一个子节点或者叶子的形状如图:
(3.) plotTree() 递归画出子节点和叶子节点:
这个函数主要的难点是 x的偏移,即画完一个注释框和箭头的时候,如何进行移动,来确定下一个子节点或者叶子的坐标位置呢?关键是求每一个子节点或叶子的横坐标和纵坐标!
a. 画子节点或者叶子时的横坐标应该怎么变化?
这里我们先求出 这个树的深度和宽度(宽度就是有多少个叶子),我们把画布figure默认为 1.0 × 1.0,那么根节点自然在该画布的中心往上,即(0.5,1.0),有多少个叶子我们就把这个画布的横坐标分成 2×叶子数 份,比如有6个叶子,我们就把这个画布的横坐标分为12份,那么从左往右 的叶子 的横坐标(这里横坐标是指注释框的横坐标,在图中注释框的横坐标不就是叶子的横坐标吗)就可以为 1/12 ,3/12,5/15 ,7/12,9/12 ,11/12 。所以起初我们设置 横坐标偏移为 x_offset = -1/(2×叶子数),这里我们假设了叶子数是6 ,所以这里起初的x_offset = -1/12,注意:x_offset 就是记录叶子的横坐标,而子节点的横坐标我们需要用这个变量去计算。然后每画一个叶子之前,横坐标首先会从原来的位置往右移动,而移动多少才能达到我们上述规划呢?当然移动变化量是 1/叶子数 。举个例子:我们起初 x_offset是-1/12 ,现在画第一个叶子,那么 x_offset 就要增加为:x_offset = -1/12 + 1/6 = 1/12 ,所以第一个叶子的横坐标就是1/12,这正好满足了我们的规划,画第二个叶子的时候,x_offset 要在画完第一个叶子的基础上继续增加为:x_offset = 1/12 + 1/6 = 3/12 ,所以第二个叶子的横坐标就是 3/12 可以看到这满足我们的规划,这就解释了为什么 x_offset 起初要设置成 -1/2×叶子数 ,解释了为什么每画一个叶子的时候要先让 x_offset 增加到x_offset + 1/叶子数 ,这都是为了凑出我们规划的 1/12 ,3/12,5/15 ,7/12,9/12 ,11/12 呀!
而画叶子是如上述描述,那么画子节点呢,其注释框的横坐标应该是什么?我们给出了公式: 子节点横坐标 = x_offset+(1.0+float(leaf_num))/2.0/treeWidth ,我们来探究一下这个公式,我们将括号拆开,变为:
子节点横坐标:
上式中,totalLeafNum是总叶子数也就是原式的treeWidth,而leaf_num是子树的叶子数
我们知道这棵大树是由多棵子树组成的,而子树的根节点就是我们说的子节点,因此我们在画子节点的时候,它的横坐标就应该是以它本身为根节点的子树的中心。如下图,我们确定右上角子节点(图中已用黑色箭头标记)的横坐标:
我们看到绿色虚线框把这个子节点作为根节点的子树标注出来了,假如只看绿色框,那么绿色框就相当于新构造了一个坐标系,里面放了一颗以该子节点为根节点的树,这个子节点就应该是这棵子树的横坐标中心,那么这个子节点在绿色框内的横坐标就是
,但是绿色框的坐标刻度却是整个坐标系的
倍(这里不明白的话可以看看图,对于绿色框,两个相邻叶子的距离是
,而对于整个坐标系来说却是
) ,所以该子节点虽然是以绿色框为坐标系的
,而且绿色框坐标系实际是从整个坐标系的
位置开始的,所以该子节点在整个坐标系的横坐标是:
,所以我们才总结出那个求子节点的横坐标公式:
把该式子合并一下,就是我们的程序:x_offset+(1.0+float(leaf_num))/2.0/treeWidth
b. 对于纵坐标,我们每画完一个子节点,纵坐标偏移y_offset 都减少 1/depth,每画完一个叶子呢?纵坐标不变,为什么呢?画完一个子节点,他下面肯定还有叶子或者子树,但是画完叶子呢,他下面肯定没有东西了,所以才是上述的情况。
c. 上述的a. b. 叙述了如何求得注释框的横坐标和纵坐标,那么箭头的坐标是什么呢,无论叶子的箭头还是子节点的箭头,他们的坐标都是其上一个子节点(即父节点)的注释框的坐标。
from numpy import * import matplotlib.pyplot as plt def isTree(obj): # 判断是否为叶子 return (type(obj).__name__ == 'dict') def getTreeLeafNum(tree): # 得到叶子数 global numLeafs key_list = ['left','right'] for key in key_list: if isTree(tree[key]): getTreeLeafNum(tree[key]) else: numLeafs += 1 return numLeafs def getTreeDepth(tree): # 得到树的深度 max_depth = 0 key_list = ['left','right'] for key in key_list: if isTree(tree[key]): depth = 1 + getTreeDepth(tree[key]) else: depth =1 if depth > max_depth: max_depth = depth return max_depth def plotNode(ax,str,xy_point,xytext_points): # 画节点 ax.annotate(str,xy=xy_point,xytext=xytext_points,va="center",ha="center",arrowprops=dict(arrowstyle="<-"), bbox=dict(boxstyle="square",color="red",alpha=0.3)) def plotLeaf(ax,str,xy_point,xytext_points): # 画叶子 ax.annotate(str,xy=xy_point,xytext=xytext_points,va="center",ha="center",arrowprops=dict(arrowstyle="<-"), bbox=dict(boxstyle="round",color="green",alpha=0.6)) def midText(ax,annotation_location,xy_location,content_str): # 画中间注释 x=(xy_location[0]-annotation_location[0])/2 + annotation_location[0] y=(xy_location[1]-annotation_location[1])/2 + annotation_location[1] ax.text(x,y,content_str) def plotTree(ax,tree,xy_location,treeWidth,treeDepth,midtext): # 递归画树 global x_offset global y_offset leaf_num = getTreeLeafNum(tree) # 叶子数 global numLeafs numLeafs = 0 depth = getTreeDepth(tree) # 深度 annotation = round(tree['spVal'],2) print('tree=',tree) print('leaf_num=',leaf_num) annotation_location = (x_offset+(1.0+float(leaf_num))/2.0/treeWidth,y_offset) midText(ax,annotation_location,xy_location,midtext) plotNode(ax,annotation,xy_location,annotation_location) # 画节点 y_offset = y_offset -1.0/treeDepth key_list = ['left', 'right'] for key in key_list: if type(tree[key]).__name__ == 'dict': print("x_off:{0}\ny_off:{1}".format(x_offset,y_offset)) plotTree(ax,tree[key],annotation_location,treeWidth,treeDepth,str(key)) else: x_offset = x_offset+ 1.0/treeWidth print("x_off:{0}\ny_off:{1}-----------".format(x_offset,y_offset)) plotLeaf(ax,round(tree[key],2),annotation_location,(x_offset,y_offset)) midText(ax,(x_offset,y_offset),annotation_location,str(key)) y_offset = y_offset + 1.0/treeDepth def creatPlot(tree): # 创建画布 fig = plt.figure() ax = fig.add_subplot(111,frameon=False) tree_width = getTreeLeafNum(tree) global numLeafs numLeafs = 0 tree_depth = getTreeDepth(tree) print("宽:",tree_width) print("深:",tree_depth) global x_offset x_offset = -0.5/tree_width global y_offset y_offset = 1.0 plotTree(ax,tree,(0.5,1.0),tree_width,tree_depth,"") ax.set_xticks([]) ax.set_yticks([]) plt.show() if __name__ == "__main__": global numLeafs numLeafs = 0 global x_offset x_offset =0 global y_offset y_offset = 0 tree = {'spInd': 0, 'spVal': 0.499171, 'left': {'spInd': 0, 'spVal': 0.339397, 'left': -2.637719329787234, 'right': -0.05}, 'right': {'spInd': 0, 'spVal': 0.729397, 'left': 107.68699163829788, 'right': {'spInd': 0, 'spVal': 0.952833, 'left': {'spInd': 0, 'spVal': 0.759504, 'left': 78.08564325, 'right': 95.7366680212766}, 'right': 108.838789625}}} print('tree=',tree) creatPlot(tree)★ 运行效果图是:



★ 最后我们使用 cart_tree_ex2.txt 数据集创造回归树,使用cart_tree_ex2test.txt 做测试集进行剪枝,数据集是:
训练集:https://github.com/zhangqingfeng0105/Machine-Learn/blob/master/cart_tree/cart_tree_ex2.txt
测试集:https://github.com/zhangqingfeng0105/Machine-Learn/blob/master/cart_tree/cart_tree_ex2test.txt
总的程序代码是:
from numpy import * import matplotlib.pyplot as plt import matplotlib import re import copy def loadDataSet(fileName): # 加载数据集 dataMat = [] fr = open(fileName) for line in fr.readlines(): curLine = line.strip().split('\t') fltLine = list(map(float,curLine)) # 加上list就是完整功能了,不然只用map会生成内存地址 dataMat.append(fltLine) dataMat = array(dataMat) # 转化为array数组,便于计算 return dataMat def binSplitDataSet(dataSet, feature, value): # 把数据集根据变量(特征)feature按照切分点value分为两类 mat0 = dataSet[nonzero(dataSet[:,feature] <= value)[0], :] # 大于成为左子树,实际图形却在右边,为了画图方便我把它改了 mat1 = dataSet[nonzero(dataSet[:,feature] > value)[0], :] return mat0, mat1 def regLeaf(dataSet): # 计算平均值,负责生成叶子节点,叶子节点根据公式不就是求所在子区域的平均值 return mean(dataSet[:,-1]) def regErr(dataSet): # 方差×个数 = 每个点与估计值的差的平方和,这是根据损失函数公式来的 return var(dataSet[:,-1]) * shape(dataSet)[0] def chooseBestSplit(dataSet, leafType=regLeaf, errType=regErr, ops=(1,2)): tols = ops[0] # 最小下降损失是1 tolN = ops[1] # 最小样本数是4 if len(set(dataSet[:,-1])) == 1: # 停止切分的条件之一 return None, leafType(dataSet) m,n = shape(dataSet) S = errType(dataSet) bestS = inf # 最优切分点的误差 bestIndex = 0 # 最优切分变量的下标 bestValue = 0 # 最优切分点 for featIndex in range(n-1): # 遍历除最后一列的其他特征,我们的数据集是(x,y),因此这里只能遍历x for splitVal in set(dataSet[:,featIndex]): # splitVal是x可能去到的每一个值作为切分点 mat0, mat1 = binSplitDataSet(dataSet, featIndex, splitVal) # 根据切分点划分为两个子区域 if (shape(mat0)[0] < tolN) or (shape(mat1)[0] < tolN): # 如果两个子区域的叶子节点小于4个,跳过此切分点 # print("内层判别小于4___________________") # print(shape(mat0)[0],shape(mat1)[0]) continue newS = errType(mat0) + errType(mat1) # 计算两部分的损失函数 if newS < bestS: # 如果损失函数小于最优损失函数 bestIndex = featIndex # 最优切分变量保存起来 bestValue = splitVal # 最优切分点保存起来 bestS = newS # 最优损失函数保存起来 if (S-bestS) < tols: # 如果切分之前的损失减切分之后的损失小于1,那么就是切分前后损失减小的太慢,停止.它是主要的停止条件 return None,leafType(dataSet) mat0,mat1 = binSplitDataSet(dataSet, bestIndex, bestValue) # 按照最优切分点分成两个区域 if (shape(mat0)[0] < tolN) or (shape(mat1)[0] <tolN): # 如果任何一个子区域的样本数小于4个,停止切分 # print("外层判断切分样本数小于4******************") # 个人感觉此判断没用,因为上面选择切分点的时候就把这个情况删除了 return None, leafType(dataSet) return bestIndex,bestValue def createTree(dataSet,leafType=regLeaf, errType=regErr, ops=(1,4)): feat,val = chooseBestSplit(dataSet, leafType, errType, ops) # 最优切分点切分 if feat == None: # 如果是叶子节点,那么val是那个数据集的平均值,即c # print("NOne/执行了",val) return val # print("没执行",val) retTree = {} retTree['spInd'] = feat # 最优切分变量(特征)的下标值 retTree['spVal'] = val # 最优切分点s,假如执行到这里,说明找到了最优切分点,将继续切分 lSet, rSet = binSplitDataSet(dataSet, feat, val) # 切分成两个子区域,lSet是大于切分点的,相当于我们图形的右边 retTree['left'] = createTree(lSet, leafType, errType, ops) # 左子树继续切分 retTree['right'] = createTree(rSet, leafType, errType, ops) # 右子树继续切分 return retTree # ------------------------------------ 剪枝处理 ---------------------------------------- def isTree(obj): return (type(obj).__name__ == 'dict') # 判断是叶子还是树 def getMean(tree): if isTree(tree['left']): tree['left'] = getMean(tree['left']) if isTree(tree['right']): tree['right'] = getMean(tree['right']) return (tree['left'] + tree['right'])/2.0 def prune(tree, testData): # 剪枝 if shape(testData)[0] == 0: print("判断测试集为空,执行过吗?") return getMean(tree) if (isTree(tree['left']) or isTree(tree['right'])): lSet, rSet = binSplitDataSet(testData,tree['spInd'],tree['spVal']) if isTree(tree['left']): tree['left'] = prune(tree['left'], lSet) if isTree(tree['right']): tree['right'] = prune(tree['right'], rSet) if not isTree(tree['left']) and not isTree(tree['right']): lSet, rSet = binSplitDataSet(testData, tree['spInd'], tree['spVal']) errorNoMerge = sum(power(lSet[:,-1] - tree['left'],2)) + sum(power(rSet[:,-1] - tree['right'],2)) treeMean = (tree['left'] + tree['right'])/2.0 errorMerge = sum(power(testData[:,-1] - treeMean,2)) if errorMerge < errorNoMerge: print("merging") return treeMean else: return tree else: return tree def reExtract(retTree_str): # 正则提取 x_division_str = "'spVal': (\d+\.?\d*)" # 正则提取出切分节点 y_estimate_str = "'left': (-?\d+\.?\d*)|'right': (-?\d+\.?\d*)" # 正则表达式取出来叶子节点数据,即最优估计值 x_division = re.compile(x_division_str).findall(retTree_str) y_estimate = re.compile(y_estimate_str).findall(retTree_str) x_division = sort(list(map(float,x_division))) # 切分点排序,因为我们画图都是从左往右画,正好对应下面的最优估计值c y_estimate = [float(x) for y in y_estimate for x in y if x != ''] # 估计值的顺序不能乱,树中的是什么顺序就是什么顺序 return x_division,y_estimate def drawPicture(dataSet,x_division, y_estimate,title_name): # x_division是切分点,y_estimate是估计值 fig = plt.figure() # 创建画布 ax = fig.add_subplot(111) points_x = dataSet[:,0] # 因为咱们的数据是(x,y)二维图形,x是切分变量,y是估计变量,可参照博客中的具体实例加以理解 points_y = dataSet[:,1] x_min = min(points_x) # 创造切分区域,所以需要x的最小值和最大值,从而构造区域 x_max = max(points_x) y_estimate.append(y_estimate[-1]) ax.step([x_min]+list(x_division)+[x_max],y_estimate,where='post',c='green',linewidth=4,label="最优估计值") # 画最优估计值 ax.scatter(points_x, points_y,s=30,c='red',marker='s',label="样本点") # 画样本点 ax.legend(loc=4) # 添加图例 # ax.grid() # 添加网格 ax.set_yticks(y_estimate) # 设置总坐标刻度 ax.set_xlabel("x") ax.set_ylabel("y") ax.set_title(title_name) plt.show() # ------------------------------------------画树状图--------------------------------------- def getTreeLeafNum(tree): # 得到叶子数 global numLeafs key_list = ['left','right'] for key in key_list: if isTree(tree[key]): getTreeLeafNum(tree[key]) else: numLeafs += 1 return numLeafs def getTreeDepth(tree): # 得到树的深度 max_depth = 0 key_list = ['left','right'] for key in key_list: if isTree(tree[key]): depth = 1 + getTreeDepth(tree[key]) else: depth =1 if depth > max_depth: max_depth = depth return max_depth def plotNode(ax,str,xy_point,xytext_points): # 画节点 ax.annotate(str,xy=xy_point,xytext=xytext_points,va="center",ha="center",arrowprops=dict(arrowstyle="<-"), bbox=dict(boxstyle="square",color="red",alpha=0.3)) def plotLeaf(ax,str,xy_point,xytext_points): # 画叶子 ax.annotate(str,xy=xy_point,xytext=xytext_points,va="center",ha="center",arrowprops=dict(arrowstyle="<-"), bbox=dict(boxstyle="round",color="green",alpha=0.6)) def midText(ax,annotation_location,xy_location,content_str): # 画中间注释 x=(xy_location[0]-annotation_location[0])/2 + annotation_location[0] y=(xy_location[1]-annotation_location[1])/2 + annotation_location[1] ax.text(x,y,content_str) def plotTree(ax,tree,xy_location,treeWidth,treeDepth,midtext): # 递归画树 global x_offset # x的偏移全局变量,举个例子如果叶子共3个,那么从左到右,第一个叶子x坐标就是1/6,第二个叶子x坐标是3/6,第三个是5/6 global y_offset # 画一次这个总坐标就降1/总深度 leaf_num = getTreeLeafNum(tree) # 叶子数 global numLeafs numLeafs = 0 depth = getTreeDepth(tree) # 深度 annotation = round(tree['spVal'],2) annotation_location = (x_offset+(1.0+float(leaf_num))/2.0/treeWidth,y_offset) # 它是节点的注释位置,却是叶子的箭头位置 # midText(ax,annotation_location,xy_location,midtext) plotNode(ax,annotation,xy_location,annotation_location) # 画节点 y_offset = y_offset -1.0/treeDepth key_list = ['left', 'right'] for key in key_list: if type(tree[key]).__name__ == 'dict': # print("x_off:{0}\ny_off:{1}".format(x_offset,y_offset)) plotTree(ax,tree[key],annotation_location,treeWidth,treeDepth,str(key)) # 递归 else: x_offset = x_offset+ 1.0/treeWidth # 画一个叶子x_offset往右移动1/叶子总数 # print("x_off:{0}\ny_off:{1}-----------".format(x_offset,y_offset)) plotLeaf(ax,round(tree[key],2),annotation_location,(x_offset,y_offset)) # 画叶子 # midText(ax,(x_offset,y_offset),annotation_location,str(key)) y_offset = y_offset + 1.0/treeDepth # 递归完一次,总坐标y_offset需要增加一个1/总深度,即这时s形画,再回去 def createPlot(tree,title_name): # 画决策树 fig = plt.figure() ax = fig.add_subplot(111,frameon=False) # 边框去掉 tree_width = getTreeLeafNum(tree) # 树的叶子数 global numLeafs numLeafs = 0 tree_depth = getTreeDepth(tree) # 树的深度 global x_offset x_offset = -0.5/tree_width # 起始x偏移为-1/(2*叶子数) global y_offset y_offset = 1.0 # 起始y偏移为1 plotTree(ax,tree,(0.5,1.0),tree_width,tree_depth,"") ax.set_xticks([]) ax.set_yticks([]) # 坐标刻度清除 ax.set_title(title_name) plt.show() if __name__ == '__main__': global numLeafs # 定义全局变量,便于计算一棵树的总叶子数 numLeafs = 0 global x_offset # 用于画注解树 x_offset =0 global y_offset y_offset = 0 # dataset = loadDataSet('/home/zhangqingfeng/test/cart_tree/cart_tree.txt') # 加载训练集 myData = loadDataSet('/home/zhangqingfeng/test/cart_tree/cart_tree_ex2.txt') # 加载测试集 mytestData = loadDataSet('/home/zhangqingfeng/test/cart_tree/cart_tree_ex2test.txt') # first_tree = createTree(dataset,ops=(1,4)) # createPlot(first_tree,"") InialTree = createTree(myData, ops=(100,4)) # 创建训练集的树 print("裁剪前的回归树为:",InialTree) createPlot(InialTree,"剪之前的决策树") # 画出剪之前的决策树 InialTree_str = str(InialTree) x_d,y_e = reExtract(InialTree_str) drawPicture(mytestData,x_d,y_e,"剪之前的拟合") # 画出剪枝之前的拟合阶梯函数 prune_tree = prune(InialTree,mytestData) # 通过测试集对树进行剪枝 createPlot(prune_tree,"剪之后的决策树") # 画出剪枝后的决策树 retTree_str = str(prune_tree) # 转化为字符串好用正则 print("裁剪后的回归树为: ",retTree_str) x_division,y_estimate = reExtract(retTree_str) drawPicture(mytestData,x_division,y_estimate,"剪之后的拟合") # 画出剪枝后的拟合阶梯函数★ 运行效果图是:
# ------------------------------------------- 剪枝后 -----------------------------------




★ 参考链接:
1. https://blog.csdn.net/weixin_40604987/article/details/79296427
------------------------ 数据集在文中已给出(每个程序后) ---------------------















 463
463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









