






论文原文pdf下载地址:HOFD: An Outdated Fact Detector for Knowledge Bases | IEEE Journals & Magazine | IEEE Xplore
论文发表时间:2023.2.27
Published in: IEEE Transactions on Knowledge and Data Engineering
目录
摘要:
1.问题背景:知识库是什么、为何重要?
知识库( knowledge base,KB )存储了高质量的信息,对于增强搜索结果、作为数据清洗的外部来源等许多应用至关重要。
2.引出问题及解决问题的意义
毫不奇怪,由于信息的快速变化,大多数KB中存在过时的事实。自然地,保持KB的最新状态是很重要的。
3.传统方法
传统智慧研究了使用参考数据(比如从新闻中提炼新的事实)来检测知识库中过时事实的问题。
3.传统方法存在的问题:
然而,现有的方法只能覆盖KB中的小部分事实。
4.本文怎么做?
在本文中,我们提出了HOFD,一种新颖的用于知识库中过时事实检测的人在回路方法。
5.介绍HOFD
HOFD使用事实的历史更新频率和更新时间等特征训练一个二分类器,以计算事实在KB中过时的可能性。
然后,HOFD与人类进行交互,以验证高可能性的事实是否确实过时。
此外,HOFD还利用逻辑规则,根据人类的反馈来检测更多过时的事实。
逻辑规则检测到的过时事实也将被反馈来进一步训练ML模型进行数据增强。
6.实验
在Yago和DBpedia等真实数据库上的大量实验表明了我们方案的有效性。
1 介绍
1.知识库作用:
知识库( Knowledge Bases,KBs ),如Yago [ 23 ]和DBpedia [ 35 ],提供了真实世界实体及其关系的丰富结构化信息,可以极大地增加信息抽取[ 24 ]、问答[ 27 ]和数据清洗[ 22 ]的性能。
2.存在的问题:
然而,KBs中的事实可能会随着世界的变化而变得过时,这将限制KBs的效用。
3.意义:
因此,知识库中的知识应该被看作是一个快速演化的事实集合,必须随着世界的变化而更新。
4.传统方法
一种常用的检测过时事实的方法是从新闻、媒体文本和百科网站中提取一些最新的事实作为参考数据[ 28 ],[ 36 ],[ 31 ]。这些更新的事实可以通过与KB中的事实进行比较来检测过时的事实。
5.传统方法缺陷
但是,单纯依靠参考数据是不够的,因为它们只能覆盖一个知识库中的一小部分实体和关系。
6.例1
图1中,f2、f4、f6、f8是过时事实,t1、t2是来自外部的参考事实。显然,t1、t2可被用于确认f6是过时事实而f5不是。同时,同时,KB中的其他事实由于缺乏足够的参考数据而无法得到验证。
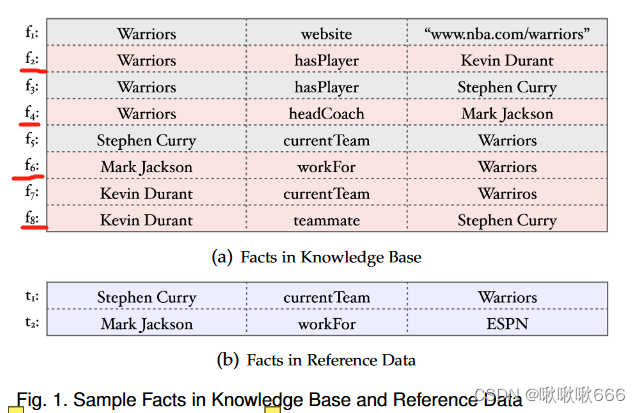
自然,一个有趣的问题是,我们如何概括参考数据中的信息,以发现更多过时的事实。
法一:利用参考数据训练机器学习( ML )模型。ML模型可以帮助区分KB中更有可能过时的活跃事实和其他永远不会改变的稳定事实。
法二:使用逻辑规则。
7.例2
给定一个逻辑规则φ 1:'如果x的headCoach是y,那么y workFor x',如果f6是过时的,则可以推断f4也是过时的。
给定另一个逻辑规则φ 2:'如果x的currentTeam是y,那么y hasPlayer x ',如果f5是最新的,那么f3也是最新的。
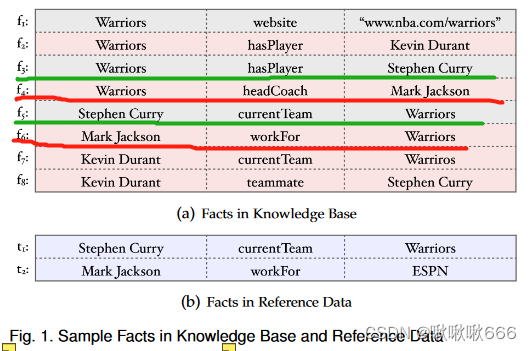
值得注意的是,KB作为知识的载体,在其生命周期中必须引入人来保证数据的准确性。虽然有些KB是由百科网站的静态转储自动构建的,但是这些KB都是基于百科网站的静态转储构建的,这些网站也需要志愿者维持并很少为KB更新提供活种子。
因此,我们应该积极汇集人类的智慧,人工检查那些具有高概率过时的事实,特别是那些不能被参考数据所覆盖的、由逻辑规则推导出来的事实。
8.例3
事实{f4,f6} (相应地 {f3、f5})可以作为正例(或负例)训练一个ML模型,该模型可以用来预测其他事实是否过时。
假设f7被预测为一个潜在过时的事实。如图2 ( a )所示,可以通过询问人类验证currentTeam of Durant is Warriors?同时,询问f7也可能借助逻辑规则知道f2和f8。

9.问题
总而言之,有三个主要问题需要解决。
( P1 )如何概括参考数据中的信息,以检测知识库中的过时事实?
( P2 )如何让人们参与验证可能过时的事实,从而最大限度地发现过时的事实,减少人力成本?
( P3 )如何高效地挖掘出有用的逻辑规则用于过时事实检测?
10.我们的方法
为了处理P1,我们将最新的参考数据映射到KB中的事实,以生成用于分类器训练的正例和负例。从KB修改历史中提取特征,如历史更新频率和一个事实的存在时间。然后,我们利用分类器来预测KB中的过时事实。
为了处理P2,我们在每次迭代中与众包工人进行交互,以标记k个事实。对事实进行选择,使能够检测到的过时事实数量最大化。同时,我们提出联合使用ML模型和基于规则的方法来降低人力成本。
为了处理P3,我们使用KB的修改历史来挖掘逻辑规则,而不仅仅是整个KB。我们定义了规则模式,并提出了一种剪枝策略来避免不可满足规则的产生。我们还建立了索引来提高效率。
11.贡献。
- 我们提出了一个新颖的人在回路框架( HOFD )来检测知识库中的过时事实,该框架包括候选过时事实预测阶段、人工验证阶段和事实扩展阶段(第3节)。
- 我们建立了一个迭代分类模型来预测过时事实。我们精心设计了冷启动和特征工程的有效技术,以提高模型的性能(第4节)。
- 我们审慎地为用户迭代地选择问题,以验证候选过时事实。我们将问题选择问题建模为图模型,并证明了在每次人工迭代中选择最好的k个问题是NP难的。我们提出了该问题的一个最优解和一个贪心算法( 第5节)
- 我们定义了逻辑规则的模式,并利用KBs的修改历史来挖掘规则。为了提高规则挖掘的效率,提出了两种新颖的策略(第6节)。
- 我们在包括Yago和DBpedia在内的真实知识库上进行了实验,并将HOFD与当前最先进的方法进行了比较,以表明我们的框架的有效性和效率(第7节)。
2 相关工作
知识库更新:
- 最直接、目前大多数的办法:
- 定期重启整个百科全书KB创建的整个流程。
- but,耗时!
- DBpedia Live:
- 通过监控 维基百科上的 编辑 并 提取文章修改后的结构化信息。
- but,许多其他的百科全书网站并没有提供实时抽取的活种子!
- USB系统:
- 通过热点预测一些最有可能改变的实体,并爬取相应的百科文章,使KB与在线百科保持同步。
- but,当某一事件发生时,百科网站的更新存在数天的延迟,热点的覆盖率难以保证。如何确定不同实体(百科网站爬取的频率)的更新频率是另一个需要解决的重要问题。
知识库清洗:
- 交互式KB清洗已经在一些工作中进行了研究
- KB约束被广泛用于检测KB中的违规行为,并减少人力成本。
- 众包技术也被用于检查知识库中的质量问题,包括不正确的对象值、类型和关系
- 基于统计的方法和基于知识表示学习的方法来区分正确和错误的三元组。
- but,KB清洗旨在检测和修复不合理的脏三元组,而过时事实是语义正确但与真实世界的变化不同步的事实
知识推理:
定义:指从已有的事实中推断出新的知识,是KB补全和错误检测的关键技术。
推理规则:已被广泛用于预测实体之间的缺失关系,如何挖掘这些规则已经被广泛研究。
- 基于概率图模型的推理方法
- 基于嵌入的推理方法
众包:
定义:利用人类的智能来解决计算机难以解决的问题。例如:实体解析,实体收集和情感分析。
众包平台:AMT
可以用来丰富数据、清理数据、匹配模式
时序知识图谱:
近年来,时序知识图谱( TKGs )的补全与推理、时间感知语言模型的构建等方面都投入了大量的研究工作。
TKGs是具有时间特征的事实集合的图,
而我们的工作作用于广泛使用的静态KBs。
这些工作也证明了考虑知识动态演化的重要性
3 本文工作






创作不易,您的鼓励是我创作做大的动力!!!
点个关注再走呗~















 3137
3137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









