






1.背景
通过pyspark读取数据库数据,然后经过数据处理写入hive时,部分中文乱码;

图1 数据处理代码
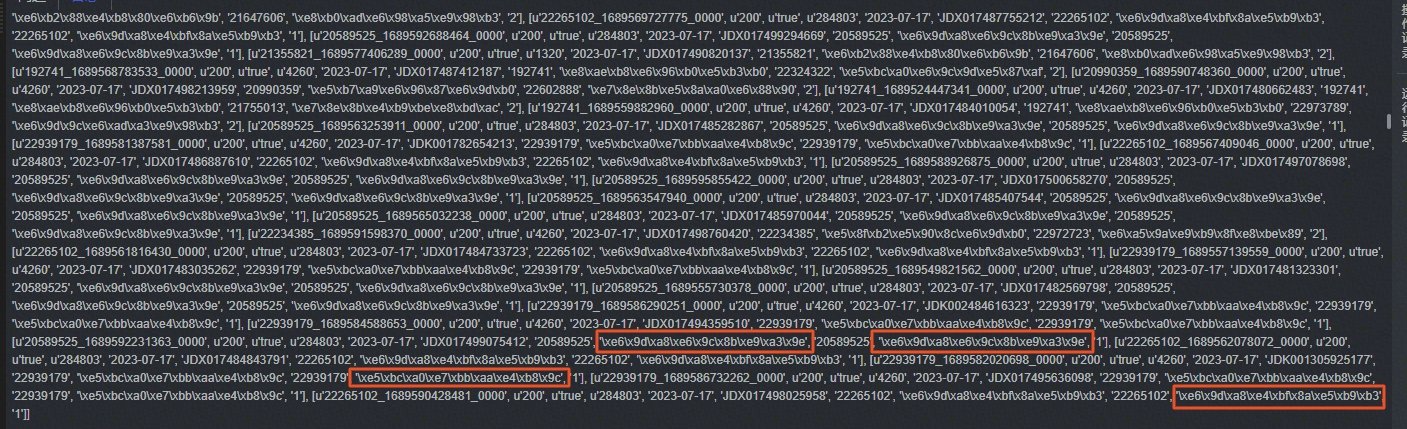
图2 原始数据list存储
组合后的DataFrame内容:
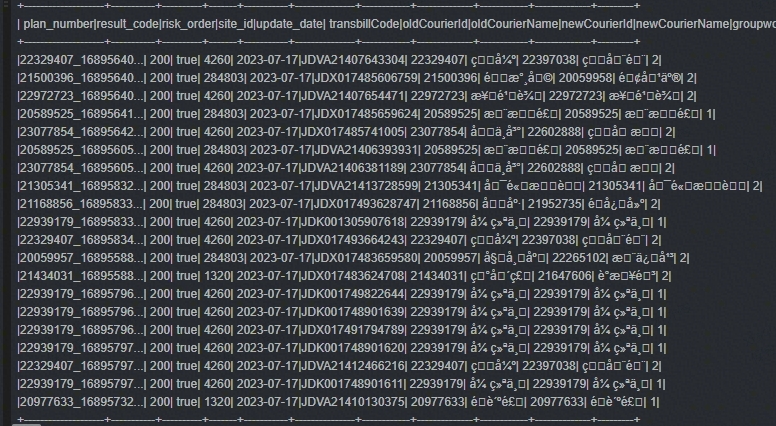
图3 原始数据DataFrame展示
2.原因
python默认使用UTF-8编码方式,处理中文时不会有任何问题;而pyspark也是可以指定UTF-8编码的,按道理来说处理中文也不会有问题,但是当数据集中存在不同编码方式时,处理中文就会存在问题,如上述两张图所示,里面有Unicode、gbk两种编码;
尝试过 以下方式均未解决
a)使用encode、decode进行重新编码:
tier3_name = arr[1].decode("utf-8").encode("ascii")b)以及声明编码:
reload(sys)
sys.setdefaultencoding('utf-8')3.解决方案【亲测有用】
从图2来看,只要是Unicode编码的字段,通过spark.createDataFrame转成DataFrame时,都可以正常显示。因此,考虑将乱码的字段由gbk转成Unicode的编码。

图4 修改后代码
可以看到下面这个图,中午字段编码已经转换成功了
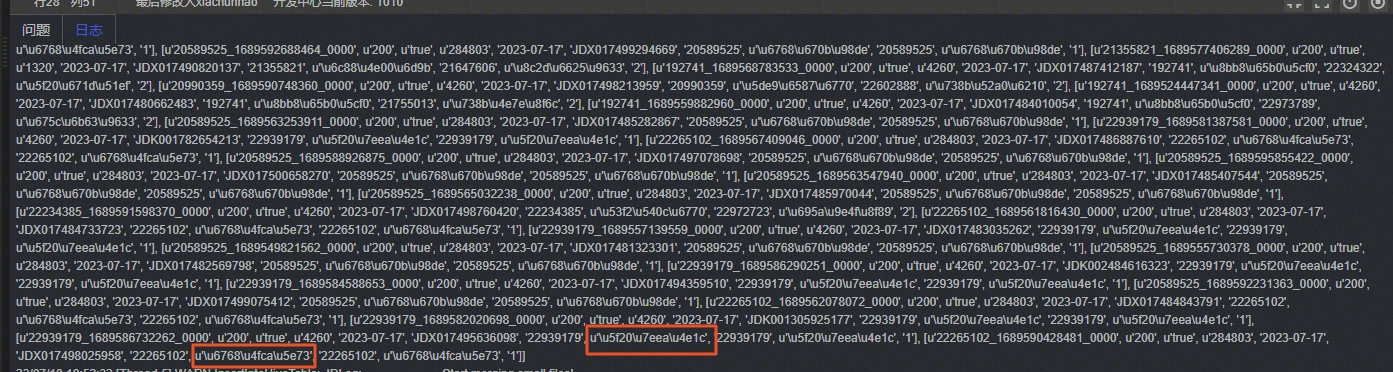
图5 修改后编码展示
组合后DataFrame内容

图6 修改后数据展示
参考:
https://www.cnblogs.com/huchong/p/9037142.html














 1012
1012











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









