







系列文章目录
Pipevn/git/docker使用
Windows环境使用docker配置dbt
文章目录
一、在Models里创建Staging文件夹(source table)
Staging层的作用是,从数据源中抽取原始数据,通常,数据会按其原始形式加载,不做任何转换。
/models
--/staging
1. 创建source文件
创建tpch_source.yml文件,将这些原始数据表注册为 dbt 的数据源,方便在模型中引用。一般情况下,最先进行的就是staging层,将原始数据加载到目标数据库,所以staging里的表和source 表是一对一的关系。
1.1 手动编写tpch_source文件
tpch_source.yml
version: 2
sources:
- name: tpch
description: ""
schema: tpch_sf1
tables:
- name: orders
description: ""
columns:
- name: o_orderkey
data_type: number
description:
1.2 使用codegen自动编写tpch_source文件
- 在Macros文件夹下创建generate_sources文件夹,专门用来创建系统的source
/macros
--/generate_sources
- 创建
generate_tpch_staging_sources.sql文件
{{ codegen.generate_source(
name = 'tpch',
schema_name = 'TPCH_SF1',
database_name = 'SNOWFLAKE_SAMPLE_DATA',
table_names = ['ORDERS','LINEITEM'],
include_descriptions = True,
generate_columns =True
) }}
- 使用dbt compile直接运行上面的脚本,在Vscode里,直接点击dbt compile的图标即可产生
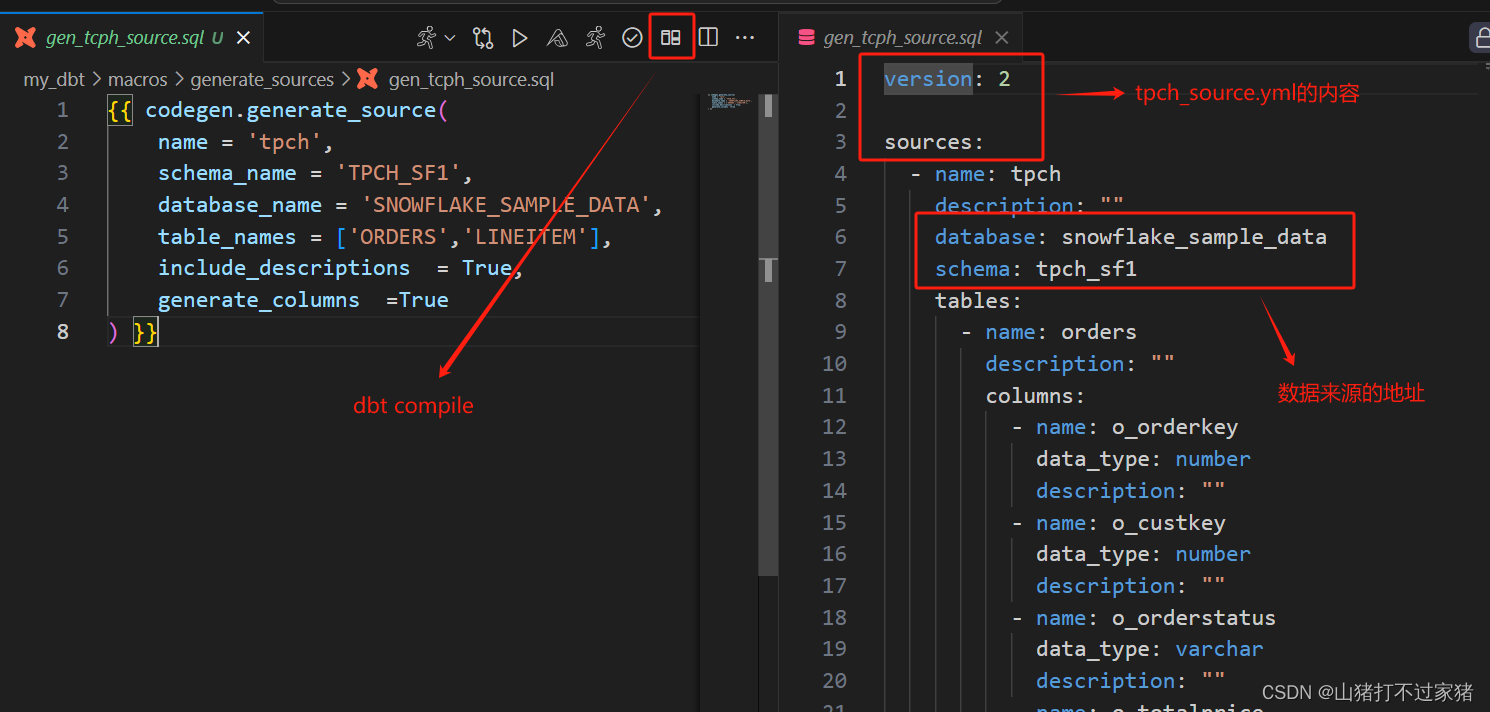
注意:使用codegen生成source的时候,会出现一个bug,sources里没有database的名称,需要我们自己手动添加进去;其次就是sources里的database和schema均是数据来源Extract的地址,而不是项目的数据库名称和地址,这里项目的目标数据库地址都是dbt_demo。
2. 加载staging层需要转换的表
2.1 加载tpch里的orders表
在staging的文件夹下,创建stg_tpch_orders.sql用来将orders表的一些字段重命名,并且作为视图加载到snowflake里
with source as (
select * from {{ source('tpch', 'orders') }}
),
renamed as (
select
o_orderkey as order_key,
o_custkey as customer_key,
o_orderstatus as status_code,
o_totalprice as total_price,
from source
)
select * from renamed
2.2 将Staging层的表都设置为View
在dbt项目的根目录,修改dbt_project.yml的内容,将staging层下的所有表,都改为view视图形式
...
models:
my_dbt:
# Config staging models as View
staging:
materialized: view
snowflake_warehouse: COMPUTE_WH
2.3 手动运行指定的model
控制台中输入,刚才的model,则只运行该Model
dbt run -s stg_tpch_orders.sql
2.4 使用airflow运行该Model
在airflow的项目文件夹dags里创建一个tcph文件夹,用来专门存放tpch项目所有的dag。
在该文件夹下创建tpch_run_stg.py
from airflow import DAG
from airflow.operators.bash import BashOperator
from datetime import datetime
from dbtOp.dbt_operator import DbtOperator
_default_args = {
'max_active_runs': 1,
'catchup': False,
'start_date': datetime(year=2020, month=9, day=1)
}
with DAG(
dag_id = 'run_stagings',
default_args= _default_args,
start_date = datetime(2024,2,3,1),
schedule_interval = None
) as dag:
task1 = DbtOperator(
task_id='run_tpch_orders',
dbt_command='dbt run -s stg_tpch_orders.sql'
)
task1
2.5 创建staging层的stg_tpch_line_items
stg_tpch_line_items.sql:提取另外一个source表的内容到view里,重点简化版
with source as (
select * from {{ source('tpch', 'lineitem') }}
),
renamed as (
select
{{ dbt_utils.generate_surrogate_key(
['l_orderkey',
'l_linenumber']) }}
as order_item_key,
l_orderkey as order_key,
l_partkey as part_key,
from source
)
select * from renamed
2.6 使用airflow一起执行staging层的所有task
创建run_tpch_stg.py一直执行上面两个tasks
from airflow import DAG
from airflow.operators.bash import BashOperator
from datetime import datetime
from dbtOp.dbt_operator import DbtOperator
_default_args = {
'max_active_runs': 1,
'catchup': False,
'start_date': datetime(year=2020, month=9, day=1)
}
with DAG(
dag_id = 'run_tpch',
default_args= _default_args,
start_date = datetime(2024,6,3,1),
schedule_interval = None
) as dag:
task1 = DbtOperator(
task_id='run_stg_tpch_orders',
dbt_command='dbt run -s stg_tpch_orders.sql'
)
task2 = DbtOperator(
task_id='run_stg_tpch_lineItems',
dbt_command='dbt run -s stg_tpch_line_items.sql'
)
task1 >> task2
二、Models里创建marts文件夹(fact/dimention)
marts文件夹里存放的都是业务相关的fact table 和 dimention table,是最终转换完成的数据
1. 创建dimention table
创建dim_order_items.sql 构建dimention table,下面为该项目的简化语法,具体语法参考完整代码。
{{ ref('stg_tpch_orders') }} 该语法可以直接引用dbt里的任何表
with orders as (
select * from {{ ref('stg_tpch_orders') }}
),
line_item as (
select * from {{ ref('stg_tpch_line_items') }}
)
select
*
from
orders
inner join line_item
on orders.order_key = line_item.order_key
order by
orders.order_date
2.创建fact table
在marts文件夹下,创建fact table fct_orders.sql ,简略语法
with orders as (
select * from {{ ref('stg_tpch_orders') }}
),
order_item as (
select * from {{ ref('int_order_items') }}
)
3. 使用airflow的TriggerDagRunOperator来执行marts里的逻辑
使用TriggerDagRunOperator可以先指定完成staging里的逻辑后,在执行marts里的逻辑。
3.1 创建marts层执行的主要逻辑
首先,我们先将marts层执行dimension table 和fact table的逻辑写出来
tpcp_run_fct.py
from airflow import DAG
from airflow.operators.bash import BashOperator
from datetime import datetime
from dbtOp.dbt_operator import DbtOperator
from airflow.operators.trigger_dagrun import TriggerDagRunOperator
_default_args = {
'max_active_runs': 1,
'catchup': False,
'start_date': datetime(year=2020, month=9, day=1)
}
with DAG(
dag_id = 'run_tpch_fct',
default_args= _default_args,
start_date = datetime(2024,6,3,1),
schedule_interval = None
) as dag:
task1 = DbtOperator(
task_id='run_dim_order_items',
dbt_command='dbt run -s dim_order_items.sql'
)
task2 = DbtOperator(
task_id='run_fct_orders',
dbt_command='dbt run -s fct_orders.sql'
)
task1 >> task2
3.2 添加TriggerDagRunOperator
添加TriggerDagRunOperator,先执行staging里的tasks完成后,再执行marts的tasks
from airflow import DAG
from airflow.operators.bash import BashOperator
from datetime import datetime
from dbtOp.dbt_operator import DbtOperator
from airflow.operators.trigger_dagrun import TriggerDagRunOperator
_default_args = {
'max_active_runs': 1,
'catchup': False,
'start_date': datetime(year=2020, month=9, day=1)
}
with DAG(
dag_id = 'run_tpch_fct',
default_args= _default_args,
start_date = datetime(2024,6,3,1),
schedule_interval = None
) as dag:
task1 = DbtOperator(
task_id='run_dim_order_items',
dbt_command='dbt run -s dim_order_items.sql'
)
task2 = DbtOperator(
task_id='run_fct_orders',
dbt_command='dbt run -s fct_orders.sql'
)
trigger_stg = TriggerDagRunOperator(
task_id='trigger_stg_tpch',
trigger_dag_id='run_tpch', #ID of the dag to trigger,这里是tpch_run_stg里的dag_id
execution_date='{{ ds }}', #只有2个dag在相同日期的时候才能执行
reset_dag_run=True, #允许同一个日期多次执行
wait_for_completion=True, #等待tpch_run_stg里任务完成后,如果不加的话后面的storagin等三个任务会一直执行
poke_interval= 10 #检测tpch_run_stg是否完成10s一次
)
trigger_stg >> task1 >> task2
注意:
trigger_dag_id:是需要执行的dags的 tpch_run_stg.py 程序里的dag_id,不是.py的名称。execution_date:两个dags文件的执行日期必须是相同的,否则无法执行- 第一次执行时候,需要将所有dags都执行成功一次后,才可以实现只执行
tpcp_run_fct.py,自动触发staging的dag
三、测试(Generic and Singular Tests)
1. Generic tests
Generic tests一般直接写在models文件夹里面
例如:我们对marts文件夹下的所有fact table和dimention table进行generic tests,创建generic_testes.yml文件
- 文件结构
/models
--/marts
----generic_tests.yml
1.1 使用codegen自动生成model的yml文件用于test
与生成stg里的source不同,我们使用marts里的model名称来生成yml文件
- 在macros里编写
generate_marts_model.sql,并且compile
{{ codegen.generate_model_yaml(
model_names=['fct_orders','dim_order_items']
) }}
1.2 基于生成好的结构,编写我们的test
将上面生成好的结构复制,并且在创建generic_tests.yml
models:
- name: fct_orders
description: ""
columns:
- name: order_key
data_type: number
description: ""
tests:
- unique
- not_null
- relationships:
to: ref('stg_tpc_orders')
field: order_key
severity: warn
- name: status_code
data_type: varchar
description: ""
tests:
- not_null
- accecpted_values:
values: ['P', 'O', 'F']
severity: warn
- name: priority_code
data_type: varchar
description: ""
2. Singular tests
与generic test不用的是,singular test需要写在test文件夹下,用来完成一些直接使用column无法完成的事情
/tests
--ts_fct_orders_discount.sql
select
*
from {{ ref('fct_orders') }}
where
item_discount_amount > 0
















 260
260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









