







系列文章目录
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
例如:第一章 Python 机器学习入门之pandas的使用
文章目录
一、创建项目所需的snowflake环境
1. 创建数据库和schema
- 创建数据库
create database if not exists cricket;
- 使用当前数据库
use database cricket
- 创建所需的schema
create or replace schema land;
create or replace schema raw;
create or replace schema clean;
create or replace schema consumption;
2. 创建json的格式和internal stage
- 创建本次项目所需要处理的json的格式
create or replace file format my_json_format
type = json
null_if = ('\\n', 'null', '')
strip_outer_array = true
comment = 'Json File Format with outer stip array flag true';
- 创建internal stage用来将我们的文件上传至此(PS:一般创建的是external stage来自外部的)
create or replace stage my_stg;
二、Landing Layer 原始数据的存放层(存放数据的源文件)
Landing层是将数据源保存在snowflake里的最初层,这里由于是internal stage,类似于将snowflake当成了一个数据库;如果我们使用external stage 外部cloud上的数据,就不需要直接将数据保存在snowflake里,该层则只是一个引用external stage的层。
1. 上传文件到internal stage里
- 在UI里直接上传到internal stage里的
/cricket/json(PS:可以使用snowflake cli 结合airflow来上传)
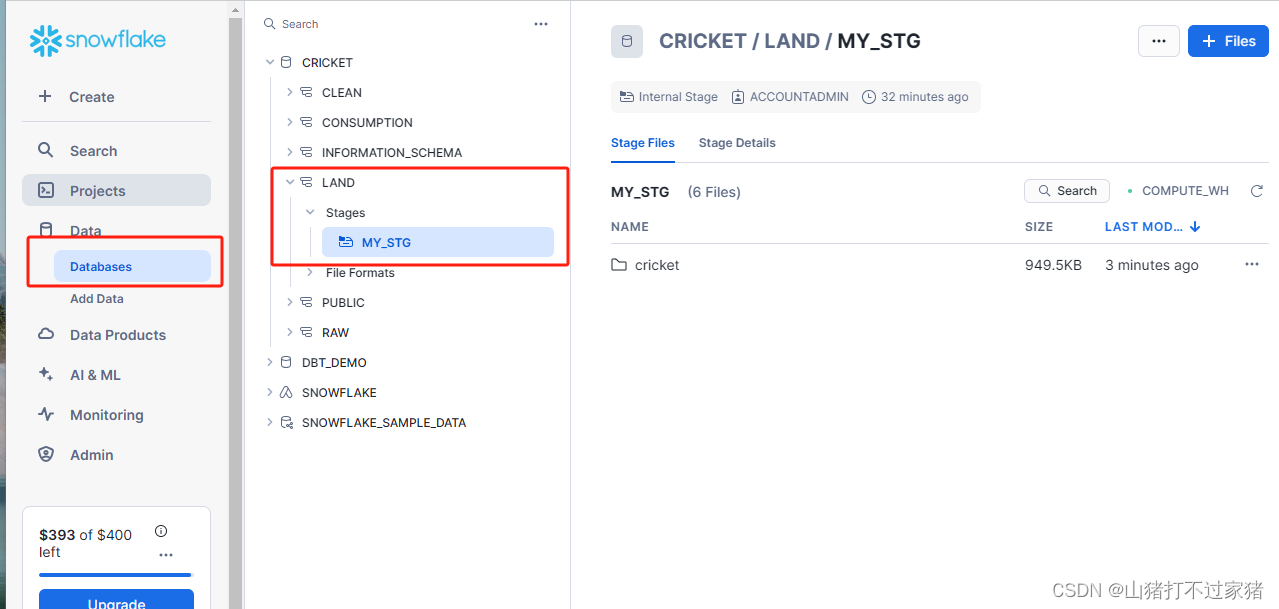
- 查看刚才上传的文件
list @my_stg;
2. 查看上传的文件
- 这时候landing层的文件已经存放完毕
select
t.$1:meta::variant as meta,
t.$1:info::variant as info,
t.$1:innings::array as innings,
metadata$filename as file_name,
metadata$file_row_number int,
metadata$file_content_key text,
metadata$file_last_modified stg_modified_ts
from @my_stg/cricket/json/1384405.json (file_format => 'my_json_format') t;
注意:如果json里的是对象,则它在snowflake里的格式是object,取值时使用[ ];如果是一个数组,它在snowflake里则是array,取值时使用:
三、Raw Layer 数据初始处理(只转为可用的snowflake数据类型)
对应snowflake里schema的raw,这里我们将landing层的最原始的数据只进行了snowflake里的数据类型转换,这样以后的操作都是snowflake里的数据对象。
由于该层是从原始数据转为snowflake 的类型,所以需要添加上文件源的信息
1. 创建表match_raw_tbl用来存放所有json file
- 创建一个表,将所有的json文件存放进来; meta/info/innings 是Json文件的3个主要的大结构
- 只有大括号的形式:类型是object
- 大括号开始,里面包含中括号:类型是variant,英语变体的意思
- 中括号开始:array类型
-- lets create a table inside the raw layer
create or replace transient table cricket.raw.match_raw_tbl (
meta object not null,
info variant not null,
innings ARRAY not null,
stg_file_name text not null,
stg_file_row_number int not null,
stg_file_hashkey text not null,
stg_modified_ts timestamp not null
)
comment = 'This is raw table to store all the json data file with root elements extracted'
;
2. 复制land层的里的所有json file到该表match_raw_tbl里
- 其中
metadata$filenam/file_row_number/file_content_key/file_last_modified系统函数
copy into cricket.raw.match_raw_tbl from
(
select
t.$1:meta::object as meta,
t.$1:info::variant as info,
t.$1:innings::array as innings,
--
metadata$filename,
metadata$file_row_number,
metadata$file_content_key,
metadata$file_last_modified
from @cricket.land.my_stg/cricket/json (file_format => 'cricket.land.my_json_format') t
)
on_error = continue;
3. 查看数据
- 此时,所有6个文件的json主要分支已经存放在该原始表里,该表没有对json数据进行任何的处理,只是将数据源的数据进行了snowflake的数据类型转换。
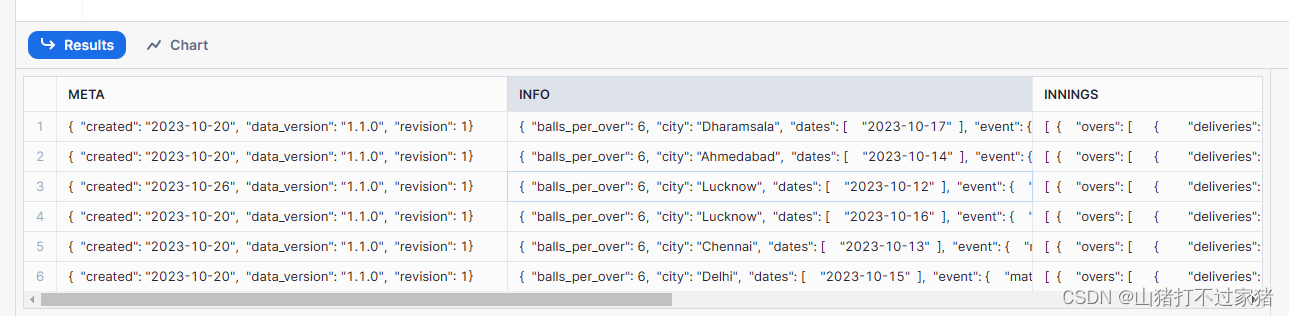
四、Clean层将json转换为我们可以使用表
将多层结构的json字段进行扁平化和字段的类型调整,这一阶段,我们将json文件正式的转成了table
该层由于是生成了信息的表,所以原表的信息一定要记录。
1. 对meta字段清洗
- 读取meta里的数据,因为meta是object 所以需要用
[ ]来读取
select
meta['data_version']:: text as data_version,
meta['created']:: date as data_version,
meta['revision']:: number as revision
from cricket.raw.match_raw_tbl
2. 对info字段清洗
2.1 清洗match字段,生成match_detail_clean 表
- 由于info是vairent 类型,所以使用:取数
create or replace transient table cricket.clean.match_detail_clean as
select
info:match_type_number::int as match_type_number,
info:event.name::text as event_name,
case
when
info:event.match_number::text is not null then info:event.match_number::text
when
info:event.stage::text is not null then info:event.stage::text
else
'NA'
end as match_stage,
info:dates[0]::date as event_date,
date_part('year',info:dates[0]::date) as event_year,
date_part('month',info:dates[0]::date) as event_month,
date_part('day',info:dates[0]::date) as event_day,
info:match_type::text as match_type,
info:season::text as season,
info:team_type::text as team_type,
info:overs::text as overs,
info:city::text as city,
info:venue::text as venue,
info:gender::text as gender,
info:teams[0]::text as first_team,
info:teams[1]::text as second_team,
case
when info:outcome.winner is not null then 'Result Declared'
when info:outcome.result = 'tie' then 'Tie'
when info:outcome.result = 'no result' then 'No Result'
else info:outcome.result
end as matach_result,
case
when info:outcome.winner is not null then info:outcome.winner
else 'NA'
end as winner,
info:toss.winner::text as toss_winner,
initcap(info:toss.decision::text) as toss_decision,
--
stg_file_name ,
stg_file_row_number,
stg_file_hashkey,
stg_modified_ts
from
cricket.raw.match_raw_tbl;
取数的核心:varient用
:;object类型可以使用:也可以使用[]
2.2 清洗players字段,生成player_clean_tbl表
- 从player的结构看出来,每个国家包含11个队员的名称,所以需要进行扁平化处理
- 查看player的结构,player是一个value是array
select
raw.info:match_type_number:: int as match_type_number,
raw.info:players,
from cricket.raw.match_raw_tbl raw
where match_type_number = 4669
- 扁平化处理player,可以看出p的key是国家名称,value则是 每个运动员的名称
select
raw.info:match_type_number:: int as match_type_number,
p.*
from cricket.raw.match_raw_tbl raw,
lateral flatten(input => raw.info:players) p,
where match_type_number = 4669

3. 接着对p.value进行flatten,就可以获得里面的运动员名称 ,至此就完成了一个Json文件的展开
select
raw.info:match_type_number:: int as match_type_number,
p.key:: text as country,
team.value :: text as player_name,
from cricket.raw.match_raw_tbl raw,
lateral flatten(input => raw.info:players) p,
lateral flatten(input => p.value) team,
where match_type_number = 4669
- 对表里的所有文件的player进行flatten,生成最终的player_clean_tbl表
create or replace table player_clean_tbl as
select
raw.info:match_type_number:: int as match_type_number,
p.key:: text as country,
team.value :: text as player_name,
stg_file_name ,
stg_file_row_number,
stg_file_hashkey,
stg_modified_ts
from cricket.raw.match_raw_tbl raw,
lateral flatten(input => raw.info:players) p,
lateral flatten(input => p.value) team
#
2.3 为上面的表生成关系
- 上面的表在创建的时候,都是独立的没有通过键来进行链接,所以我们需要找到一个建立练习的key;不难看出来,这个是比赛的信息,所以比赛的ID是唯一的且和这些球员是有联系的,所以我们使用
MATCH_DETAIL_CLEAN表里的MATCH_TYPE_NUMBER当做外键
- 设置
MATCH_TYPE_NUMBER为primary key
alter table cricket.clean.match_detail_clean
add constraint pk_match_type_number primary key (match_type_number);
- 给
PLAYER_CLEAN_TBL里的match_type_number添加外键
alter table player_clean_tbl
add constraint fk_match_id
foreign key (match_type_number)
references MATCH_DETAIL_CLEAN (match_type_number);
- 检查外键是否添加成功,查看建表语句
select get_ddl('table','PLAYER_CLEAN_TBL')
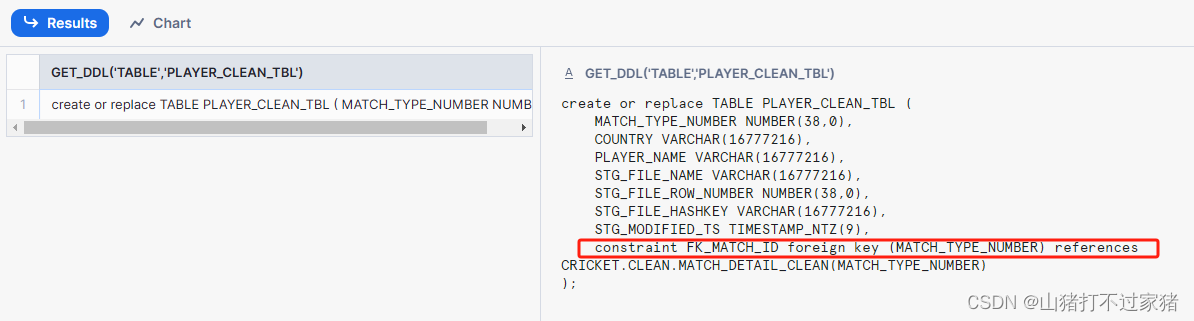
3.对innings字段进行清洗
3.1 Delivery表的数据
- 对
innings字段进行faltten
select
raw.info:match_type_number:: text as match_type_number,
i.value:team :: text as country,
i.*,
from cricket.raw.match_raw_tbl raw,
lateral flatten (input => raw.innings) i,
where match_type_number = 4669

2. 对 innings里的value的overs进行flatten
select
raw.info:match_type_number:: text as match_type_number,
i.value:team :: text as country,
o.*
from cricket.raw.match_raw_tbl raw,
lateral flatten (input => raw.innings) i,
lateral flatten (input => i.value:overs) o,
where match_type_number = 4669
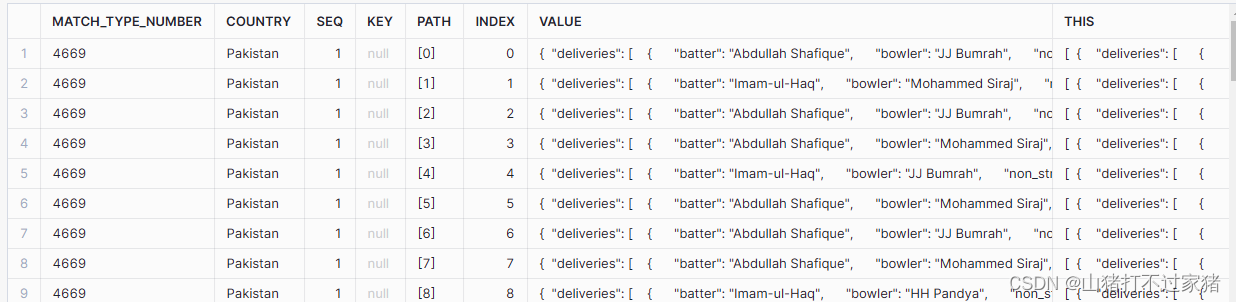
3.对overs的value里的deliveries进行flatten
select
raw.info:match_type_number:: text as match_type_number,
i.value:team :: text as country,
d.*
from cricket.raw.match_raw_tbl raw,
lateral flatten (input => raw.innings) i,
lateral flatten (input => i.value:overs) o,
lateral flatten (input => o.value:deliveries) d,
where match_type_number = 4669
4. 此时,我们需要的deliveries里的信息已经全部显示出来,我们只需要根据最后的结构取数
{
"batter": "Abdullah Shafique",
"bowler": "JJ Bumrah",
"non_striker": "Imam-ul-Haq",
"runs": {
"batter": 4,
"extras": 0,
"total": 4
}
}
select
raw.info:match_type_number:: text as match_type_number,
i.value:team::text as country,
o.value:over::int as over,
d.value:bowler::text as bowler,
d.value:batter::text as batter,
d.value:non_striker::text as non_striker,
d.value:runs.batter::text as runs,
d.value:runs.extras::text as extras,
d.value:runs.total::text as total,
from cricket.raw.match_raw_tbl raw,
lateral flatten (input => raw.innings) i,
lateral flatten (input => i.value:overs) o,
lateral flatten (input => o.value:deliveries) d,
where match_type_number = 4669
- 添加deliveries的foreign key与delivery_clean_tbl相关联
-- fk relationship
alter table cricket.clean.delivery_clean_tbl
add constraint fk_delivery_match_id
foreign key (match_type_number)
references cricket.clean.match_detail_clean (match_type_number);
五、Consumption层,生成Fact Table和Dimention Table
- 该层是根据上面我们生成的clean后的table,生成实际项目所需要的dimention table 和 fact table
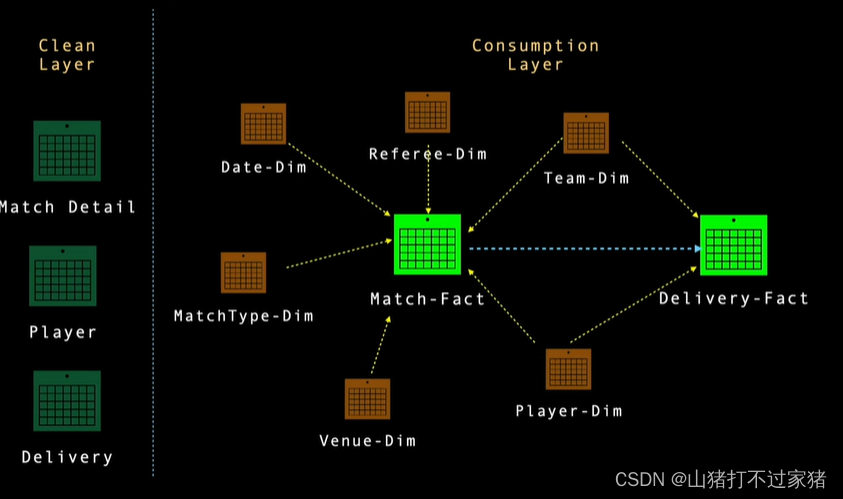
1. 创建Date Deimension
- 一般情况下,项目都会有一个date表,该表里存放的是年月日,季度,周,周末,公众假期,以及是否是周末的标志,这样也方便之后的数据分析使用,不需要每次计算,增加计算时间
create or replace table date_dim (
date_id int primary key autoincrement,
full_dt date,
day int,
month int,
year int,
quarter int,
dayofweek int,
dayofmonth int,
dayofyear int,
dayofweekname varchar(3), -- to store day names (e.g., "Mon")
isweekend boolean -- to indicate if it's a weekend (True/False Sat/Sun both falls under weekend)
);
2. 创建 裁判referee/球队team/球员player 的Dimention Table
- 创建
referee_dim表
create or replace table referee_dim (
referee_id int primary key autoincrement,
referee_name text not null,
referee_type text not null
);
- 创建
team_dim和player_dim表,并且添加两者直接的关系team_id
create or replace table team_dim (
team_id int primary key autoincrement,
team_name text not null
);
-- player..
create or replace table player_dim (
player_id int primary key autoincrement,
team_id int not null,
player_name text not null
);
alter table cricket.consumption.player_dim
add constraint fk_team_player_id
foreign key (team_id)
references cricket.consumption.team_dim (team_id);
3. 创建 场地venue/比赛match 的Dimention Table,Fact Table
- 创建
venue_dim表
create or replace table venue_dim (
venue_id int primary key autoincrement,
venue_name text not null,
city text not null,
state text,
country text,
continent text,
end_Names text,
capacity number,
pitch text,
flood_light boolean,
established_dt date,
playing_area text,
other_sports text,
curator text,
lattitude number(10,6),
longitude number(10,6)
);
match_type_dim表
create or replace table match_type_dim (
match_type_id int primary key autoincrement,
match_type text not null
);
match_fact表
CREATE or replace TABLE match_fact (
match_id INT PRIMARY KEY,
date_id INT NOT NULL,
referee_id INT NOT NULL,
team_a_id INT NOT NULL,
team_b_id INT NOT NULL,
match_type_id INT NOT NULL,
venue_id INT NOT NULL,
total_overs number(3),
balls_per_over number(1),
overs_played_by_team_a number(2),
bowls_played_by_team_a number(3),
extra_bowls_played_by_team_a number(3),
extra_runs_scored_by_team_a number(3),
fours_by_team_a number(3),
sixes_by_team_a number(3),
total_score_by_team_a number(3),
wicket_lost_by_team_a number(2),
overs_played_by_team_b number(2),
bowls_played_by_team_b number(3),
extra_bowls_played_by_team_b number(3),
extra_runs_scored_by_team_b number(3),
fours_by_team_b number(3),
sixes_by_team_b number(3),
total_score_by_team_b number(3),
wicket_lost_by_team_b number(2),
toss_winner_team_id int not null,
toss_decision text not null,
match_result text not null,
winner_team_id int not null,
CONSTRAINT fk_date FOREIGN KEY (date_id) REFERENCES date_dim (date_id),
CONSTRAINT fk_referee FOREIGN KEY (referee_id) REFERENCES referee_dim (referee_id),
CONSTRAINT fk_team1 FOREIGN KEY (team_a_id) REFERENCES team_dim (team_id),
CONSTRAINT fk_team2 FOREIGN KEY (team_b_id) REFERENCES team_dim (team_id),
CONSTRAINT fk_match_type FOREIGN KEY (match_type_id) REFERENCES match_type_dim (match_type_id),
CONSTRAINT fk_venue FOREIGN KEY (venue_id) REFERENCES venue_dim (venue_id),
CONSTRAINT fk_toss_winner_team FOREIGN KEY (toss_winner_team_id) REFERENCES team_dim (team_id),
CONSTRAINT fk_winner_team FOREIGN KEY (winner_team_id) REFERENCES team_dim (team_id)
);
- 写入数据
insert into cricket.consumption.match_fact
select
m.match_type_number as match_id,
dd.date_id as date_id,
0 as referee_id,
ftd.team_id as first_team_id,
std.team_id as second_team_id,
mtd.match_type_id as match_type_id,
vd.venue_id as venue_id,
50 as total_overs,
6 as balls_per_overs,
max(case when d.team_name = m.first_team then d.over else 0 end ) as OVERS_PLAYED_BY_TEAM_A,
sum(case when d.team_name = m.first_team then 1 else 0 end ) as balls_PLAYED_BY_TEAM_A,
sum(case when d.team_name = m.first_team then d.extras else 0 end ) as extra_balls_PLAYED_BY_TEAM_A,
sum(case when d.team_name = m.first_team then d.extra_runs else 0 end ) as extra_runs_scored_BY_TEAM_A,
0 fours_by_team_a,
0 sixes_by_team_a,
(sum(case when d.team_name = m.first_team then d.runs else 0 end ) + sum(case when d.team_name = m.first_team then d.extra_runs else 0 end ) ) as total_runs_scored_BY_TEAM_A,
sum(case when d.team_name = m.first_team and player_out is not null then 1 else 0 end ) as wicket_lost_by_team_a,
max(case when d.team_name = m.second_team then d.over else 0 end ) as OVERS_PLAYED_BY_TEAM_B,
sum(case when d.team_name = m.second_team then 1 else 0 end ) as balls_PLAYED_BY_TEAM_B,
sum(case when d.team_name = m.second_team then d.extras else 0 end ) as extra_balls_PLAYED_BY_TEAM_B,
sum(case when d.team_name = m.second_team then d.extra_runs else 0 end ) as extra_runs_scored_BY_TEAM_B,
0 fours_by_team_b,
0 sixes_by_team_b,
(sum(case when d.team_name = m.second_team then d.runs else 0 end ) + sum(case when d.team_name = m.second_team then d.extra_runs else 0 end ) ) as total_runs_scored_BY_TEAM_B,
sum(case when d.team_name = m.second_team and player_out is not null then 1 else 0 end ) as wicket_lost_by_team_b,
tw.team_id as toss_winner_team_id,
m.toss_decision as toss_decision,
m.matach_result as matach_result,
mw.team_id as winner_team_id
from
cricket.clean.match_detail_clean m
join date_dim dd on m.event_date = dd.full_dt
join team_dim ftd on m.first_team = ftd.team_name
join team_dim std on m.second_team = std.team_name
join match_type_dim mtd on m.match_type = mtd.match_type
join venue_dim vd on m.venue = vd.venue_name and m.city = vd.city
join cricket.clean.delivery_clean_tbl d on d.match_type_number = m.match_type_number
join team_dim tw on m.toss_winner = tw.team_name
join team_dim mw on m.winner= mw.team_name
--where m.match_type_number = 4686
group by
m.match_type_number,
date_id,
referee_id,
first_team_id,
second_team_id,
match_type_id,
venue_id,
total_overs,
toss_winner_team_id,
toss_decision,
matach_result,
winner_team_id
;
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









