






资源参考
https://github.com/weiliu89/caffe/tree/ssd

下载caffe-ssd根目录压缩包,并传到ubuntu上解压。
编译
编译很多东西要参考caffe学习(2):ubuntu18.04安装caffe环境并编译—GPU环境
但其实我caffe环境已经搭成一遍,这次很简单。
make all -j12 # 我的电脑核比较多
make py -j12 #注意,官方提供的源码是不需要这步的,ssd中要用到
make test -j12
make runtest -j12
下载数据
- 准备VGGNet模型
放在CAFFE_ROOT/models/VGGNet/ - 下载VOC数据集
数据格式转换
- 创建LMDB file
cd $CAFFE_ROOT
# Create the trainval.txt, test.txt, and test_name_size.txt in data/VOC0712/
./data/VOC0712/create_list.sh
# You can modify the parameters in create_data.sh if needed.
# It will create lmdb files for trainval and test with encoded original image:
# - $HOME/data/VOCdevkit/VOC0712/lmdb/VOC0712_trainval_lmdb
# - $HOME/data/VOCdevkit/VOC0712/lmdb/VOC0712_test_lmdb
# and make soft links at examples/VOC0712/
./data/VOC0712/create_data.sh
create_data.sh用这个时报错,发现create_data.sh文件中
python改为python2,因为我配的环境是基于python2.7的。
训练/评估
训练
# It will create model definition files and save snapshot models in:
# - $CAFFE_ROOT/models/VGGNet/VOC0712/SSD_300x300/
# and job file, log file, and the python script in:
# - $CAFFE_ROOT/jobs/VGGNet/VOC0712/SSD_300x300/
# and save temporary evaluation results in:
# - $HOME/data/VOCdevkit/results/VOC2007/SSD_300x300/
# It should reach 77.* mAP at 120k iterations.
python examples/ssd/ssd_pascal.py
这个例子用的模型是CAFFE_ROOT/models/VGGNet/VGG_ILSVRC_16_layers_fc_reduced.caffemodel
报错1Check failed: error == cudaSuccess (10 vs. 0) invalid device ordinal
这是由于GPU数量不对导致的,打开ssd_pascal.py文件,找到第332行,gpus = "0,1,2,3"改为gpus = "0",0表示1个GPU,1表示2个GPU。
报错2math_functions.cpp:250] Check failed: a <= b <0 vs -1.19209e-007>,我还不知道为什么,但打开/caffe/src/caffe/util/math_functions.cpp注释第250行。此报错2结合报错4看。

报错3Caffe: Data layer prefetch queue empty这是因为CPU读取lmdb数据的速度远低于GPU速度。还在读取数据,GPU等待中。
打开create_data.sh文件,SSD模型要求输入图片为300*300。修改重新生成lmdb格式文件。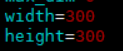
报错4 注释掉了报错2中//CHECK_LE(a,b);导致后边训练会报错Data layer prefetch queue empty。把//CHECK_LE(a,b);注释取消。然后找到/caffe/src/caffe/util/sampler.cpp,作如下改动,加上红色框出来的内容。

然后训练:python examples/ssd/ssd_pascal.py成功开始训练。

报错5 结果训练到1000次迭代,显存不够了。
 因为我设置了每1000次迭代进行一次测试,测试的时候也需要给测试分配显存,故显存不够了。我有两块显卡,一块显卡大概10G显存。训练需要10G显存,测试需要2.5G显存。(显存和GPU的使用和batch_size设置的大小有关)故我用上两块显卡就成功解决问题。
因为我设置了每1000次迭代进行一次测试,测试的时候也需要给测试分配显存,故显存不够了。我有两块显卡,一块显卡大概10G显存。训练需要10G显存,测试需要2.5G显存。(显存和GPU的使用和batch_size设置的大小有关)故我用上两块显卡就成功解决问题。
评估
# If you would like to test a model you trained, you can do:
python examples/ssd/score_ssd_pascal.py
score_ssd_pascal.py代码内容ssd_pascal.py差不多。只是这份里面截取了test的部分。运行一下得到

detection_eval即是mPA,平均准确率。由于我是拿了这个数据集的前1000个图片,训20类,才1000次迭代。准确率非常低。这里只是跑通这个过程。
使用网络摄像头测试模型
python examples/ssd/ssd_pascal_webcam.py
SSD算法过程查看
查看examples/ssd_detect.ipynb或examples/ssd/ssd_detect.cpp了解如何使用SSD模型检测对象。查看examples/ssd/plot_detections.py如何绘制ssd_detect.cpp输出的检测结果。















 1706
1706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









