







本系列接caffe学习系列
这篇博客是我自己瞎倒腾的,有误,没有实现起来,转1h-8学习(2):1h-8适配之int8直接量化+转.cambricon格式
我尝试量化的模型是我自己训练的VGG_gtsdb_voc_SSD_300x300_iter_60000.caffemodel
网络结构文件对比
网络结构文件有五个:train.prototxt(训练时网络结构)、test.prototxt(测试评估时网络结构)、deploy.prototxt(实际图片检测网络结构)、ssd_float32_dense.prototxt(适配1-h8的全精度网络结构)、ssd_float32_dense.fix8.prototxt(量化完成后的网络结构)。因为Convolution、ReLU、Pooling层是所有网络结构文件共有的,我之后统称为conv层组。
train.prototxt
数据层:训练时需要lmdb格式的数据,数据层是AnnotatedData层。
conv层组:参数是浮点数。
拥有的Permute、Flatten、PriorBox、Concat层。
MultiBoxLoss计算损失函数。
test.prototxt
数据层:评估时也是用到lmdb格式的数据,数据层是AnnotatedData层。
conv层组:参数是浮点数。
拥有的Permute、Flatten、PriorBox、Concat层。
拥有Reshape、Softmax层。
检测层:DetectionOutput。
评估层:DetectionEvaluate。
deploy.prototxt
数据层:data层,即输入是图片。
conv层组:参数是浮点数。
拥有的Permute、Flatten、PriorBox、Concat层。
拥有Reshape、Softmax层。
检测层:DetectionOutput。
ssd_float32_dense.prototxt
数据层:data层,即输入是图片。
conv层组:参数是整型数。
没有Permute、Flatten、PriorBox、Concat层。
没有拥有Reshape、Softmax层。
检测层:SsdDetection。这一层包含PriorBox层的参数,相当于原来独立的PriorBox层的操作,合并进这层操作。
ssd_float32_dense.fix8.prototxt
数据层:data层,即输入是图片。
conv层组:参数是整型数。所有conv层组统一加了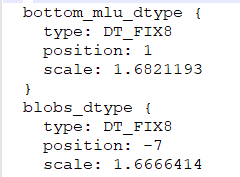
特别的conv1_1层加了参数std: 1。conv4_3_norm加了俩bottom_mlu_dtype,如图
没有Permute、Flatten、PriorBox、Concat层。
没有拥有Reshape、Softmax层。
检测层:SsdDetection。这一层包含PriorBox层的参数,相当于原来独立的PriorBox层的操作,合并进这层操作。
这边给出ssd_float32_dense.fix8.prototxt,仅作参考。
layer {
name: "data"
type: "Input"
top: "data"
input_param {
shape {
dim: 1
dim: 3
dim: 300
dim: 300
}
}
}
layer {
name: "conv1_1"
type: "Convolution"
bottom: "data"
top: "conv1_1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
mean_value: 104
mean_value: 117
mean_value: 123
std: 1
}
bottom_mlu_dtype {
type: DT_FIX8
position: 1
scale: 1.6821193
}
blobs_dtype {
type: DT_FIX8
position: -7
scale: 1.6666414
}
}
layer {
name: "relu1_1"
type: "ReLU"
bottom: "conv1_1"
top: "conv1_1"
}
layer {
name: "conv1_2"
type: "Convolution"
bottom: "conv1_1"
top: "conv1_2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: 3
scale: 1.9628743
}
blobs_dtype {
type: DT_FIX8
position: -8
scale: 1.7478662
}
}
layer {
name: "relu1_2"
type: "ReLU"
bottom: "conv1_2"
top: "conv1_2"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1_2"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2_1"
type: "Convolution"
bottom: "pool1"
top: "conv2_1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: 4
scale: 1.1986842
}
blobs_dtype {
type: DT_FIX8
position: -8
scale: 1.2195039
}
}
layer {
name: "relu2_1"
type: "ReLU"
bottom: "conv2_1"
top: "conv2_1"
}
layer {
name: "conv2_2"
type: "Convolution"
bottom: "conv2_1"
top: "conv2_2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: 5
scale: 1.4908361
}
blobs_dtype {
type: DT_FIX8
position: -8
scale: 1.9700658
}
}
layer {
name: "relu2_2"
type: "ReLU"
bottom: "conv2_2"
top: "conv2_2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2_2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv3_1"
type: "Convolution"
bottom: "pool2"
top: "conv3_1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: 5
scale: 1.3416708
}
blobs_dtype {
type: DT_FIX8
position: -8
scale: 1.087052
}
}
layer {
name: "relu3_1"
type: "ReLU"
bottom: "conv3_1"
top: "conv3_1"
}
layer {
name: "conv3_2"
type: "Convolution"
bottom: "conv3_1"
top: "conv3_2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: 5
scale: 1.4190377
}
blobs_dtype {
type: DT_FIX8
position: -8
scale: 1.2495775
}
}
layer {
name: "relu3_2"
type: "ReLU"
bottom: "conv3_2"
top: "conv3_2"
}
layer {
name: "conv3_3"
type: "Convolution"
bottom: "conv3_2"
top: "conv3_3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: 5
scale: 1.4766674
}
blobs_dtype {
type: DT_FIX8
position: -8
scale: 1.4848723
}
}
layer {
name: "relu3_3"
type: "ReLU"
bottom: "conv3_3"
top: "conv3_3"
}
layer {
name: "pool3"
type: "Pooling"
bottom: "conv3_3"
top: "pool3"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv4_1"
type: "Convolution"
bottom: "pool3"
top: "conv4_1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: 4
scale: 1.3106487
}
blobs_dtype {
type: DT_FIX8
position: -8
scale: 1.940845
}
}
layer {
name: "relu4_1"
type: "ReLU"
bottom: "conv4_1"
top: "conv4_1"
}
layer {
name: "conv4_2"
type: "Convolution"
bottom: "conv4_1"
top: "conv4_2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: 3
scale: 1.2383621
}
blobs_dtype {
type: DT_FIX8
position: -9
scale: 1.4110417
}
}
layer {
name: "relu4_2"
type: "ReLU"
bottom: "conv4_2"
top: "conv4_2"
}
layer {
name: "conv4_3"
type: "Convolution"
bottom: "conv4_2"
top: "conv4_3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: 1
scale: 1.2024717
}
blobs_dtype {
type: DT_FIX8
position: -9
scale: 1.386004
}
}
layer {
name: "relu4_3"
type: "ReLU"
bottom: "conv4_3"
top: "conv4_3"
}
layer {
name: "pool4"
type: "Pooling"
bottom: "conv4_3"
top: "pool4"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv5_1"
type: "Convolution"
bottom: "pool4"
top: "conv5_1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
dilation: 1
}
bottom_mlu_dtype {
type: DT_FIX8
position: 0
scale: 1.559556
}
blobs_dtype {
type: DT_FIX8
position: -9
scale: 1.8768628
}
}
layer {
name: "relu5_1"
type: "ReLU"
bottom: "conv5_1"
top: "conv5_1"
}
layer {
name: "conv5_2"
type: "Convolution"
bottom: "conv5_1"
top: "conv5_2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
dilation: 1
}
bottom_mlu_dtype {
type: DT_FIX8
position: -1
scale: 1.4878281
}
blobs_dtype {
type: DT_FIX8
position: -9
scale: 1.6403632
}
}
layer {
name: "relu5_2"
type: "ReLU"
bottom: "conv5_2"
top: "conv5_2"
}
layer {
name: "conv5_3"
type: "Convolution"
bottom: "conv5_2"
top: "conv5_3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
dilation: 1
}
bottom_mlu_dtype {
type: DT_FIX8
position: -2
scale: 1.4428637
}
blobs_dtype {
type: DT_FIX8
position: -9
scale: 1.2724378
}
}
layer {
name: "relu5_3"
type: "ReLU"
bottom: "conv5_3"
top: "conv5_3"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5_3"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 3
stride: 1
pad: 1
}
}
layer {
name: "fc6"
type: "Convolution"
bottom: "pool5"
top: "fc6"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 1024
pad: 6
kernel_size: 3
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
dilation: 6
}
bottom_mlu_dtype {
type: DT_FIX8
position: -2
scale: 1.5620732
}
blobs_dtype {
type: DT_FIX8
position: -9
scale: 1.1169271
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
layer {
name: "fc7"
type: "Convolution"
bottom: "fc6"
top: "fc7"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 1024
kernel_size: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: -3
scale: 1.9049852
}
blobs_dtype {
type: DT_FIX8
position: -10
scale: 1.0440384
}
}
layer {
name: "relu7"
type: "ReLU"
bottom: "fc7"
top: "fc7"
}
layer {
name: "conv6_1"
type: "Convolution"
bottom: "fc7"
top: "conv6_1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 0
kernel_size: 1
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: -5
scale: 1.2238019
}
blobs_dtype {
type: DT_FIX8
position: -9
scale: 1.6430087
}
}
layer {
name: "conv6_1_relu"
type: "ReLU"
bottom: "conv6_1"
top: "conv6_1"
}
layer {
name: "conv6_2"
type: "Convolution"
bottom: "conv6_1"
top: "conv6_2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
stride: 2
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: -4
scale: 1.2868363
}
blobs_dtype {
type: DT_FIX8
position: -10
scale: 1.674374
}
}
layer {
name: "conv6_2_relu"
type: "ReLU"
bottom: "conv6_2"
top: "conv6_2"
}
layer {
name: "conv7_1"
type: "Convolution"
bottom: "conv6_2"
top: "conv7_1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 0
kernel_size: 1
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: -4
scale: 1.2617356
}
blobs_dtype {
type: DT_FIX8
position: -9
scale: 1.4698944
}
}
layer {
name: "conv7_1_relu"
type: "ReLU"
bottom: "conv7_1"
top: "conv7_1"
}
layer {
name: "conv7_2"
type: "Convolution"
bottom: "conv7_1"
top: "conv7_2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
stride: 2
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: -3
scale: 1.8346827
}
blobs_dtype {
type: DT_FIX8
position: -10
scale: 1.378601
}
}
layer {
name: "conv7_2_relu"
type: "ReLU"
bottom: "conv7_2"
top: "conv7_2"
}
layer {
name: "conv8_1"
type: "Convolution"
bottom: "conv7_2"
top: "conv8_1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 0
kernel_size: 1
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: -3
scale: 1.8314862
}
blobs_dtype {
type: DT_FIX8
position: -9
scale: 1.6415796
}
}
layer {
name: "conv8_1_relu"
type: "ReLU"
bottom: "conv8_1"
top: "conv8_1"
}
layer {
name: "conv8_2"
type: "Convolution"
bottom: "conv8_1"
top: "conv8_2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 0
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: -3
scale: 1.4325968
}
blobs_dtype {
type: DT_FIX8
position: -10
scale: 1.5062493
}
}
layer {
name: "conv8_2_relu"
type: "ReLU"
bottom: "conv8_2"
top: "conv8_2"
}
layer {
name: "conv9_1"
type: "Convolution"
bottom: "conv8_2"
top: "conv9_1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 128
pad: 0
kernel_size: 1
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: -3
scale: 1.267179
}
blobs_dtype {
type: DT_FIX8
position: -9
scale: 1.8298161
}
}
layer {
name: "conv9_1_relu"
type: "ReLU"
bottom: "conv9_1"
top: "conv9_1"
}
layer {
name: "conv9_2"
type: "Convolution"
bottom: "conv9_1"
top: "conv9_2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 0
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: -2
scale: 1.9943918
}
blobs_dtype {
type: DT_FIX8
position: -10
scale: 1.9284432
}
}
layer {
name: "conv9_2_relu"
type: "ReLU"
bottom: "conv9_2"
top: "conv9_2"
}
layer {
name: "conv4_3_norm"
type: "Normalize"
bottom: "conv4_3"
top: "conv4_3_norm"
bottom_mlu_dtype {
type: DT_FIX8
position: 6
scale: 1.2256831
}
bottom_mlu_dtype {
type: DT_FIX8
position: -4
scale: 1.3394954
}
blobs_dtype {
type: DT_FIX8
position: -10
}
norm_param {
across_spatial: false
scale_filler {
type: "constant"
value: 20
}
channel_shared: false
}
}
layer {
name: "conv4_3_norm_mbox_loc"
type: "Convolution"
bottom: "conv4_3_norm"
top: "conv4_3_norm_mbox_loc"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 16
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: -3
scale: 1.9816087
}
blobs_dtype {
type: DT_FIX8
position: -9
scale: 1.1155317
}
}
layer {
name: "conv4_3_norm_mbox_conf1"
type: "Convolution"
bottom: "conv4_3_norm"
top: "conv4_3_norm_mbox_conf1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 20
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: -3
scale: 1.9816087
}
blobs_dtype {
type: DT_FIX8
position: -9
scale: 1.298094
}
}
layer {
name: "fc7_mbox_loc"
type: "Convolution"
bottom: "fc7"
top: "fc7_mbox_loc"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 24
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: -5
scale: 1.2238019
}
blobs_dtype {
type: DT_FIX8
position: -10
scale: 1.833989
}
}
layer {
name: "fc7_mbox_conf1"
type: "Convolution"
bottom: "fc7"
top: "fc7_mbox_conf1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 30
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: -5
scale: 1.2238019
}
blobs_dtype {
type: DT_FIX8
position: -11
scale: 1.3894453
}
}
layer {
name: "conv6_2_mbox_loc"
type: "Convolution"
bottom: "conv6_2"
top: "conv6_2_mbox_loc"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 24
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: -4
scale: 1.2617356
}
blobs_dtype {
type: DT_FIX8
position: -10
scale: 1.424156
}
}
layer {
name: "conv6_2_mbox_conf1"
type: "Convolution"
bottom: "conv6_2"
top: "conv6_2_mbox_conf1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 30
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: -4
scale: 1.2617356
}
blobs_dtype {
type: DT_FIX8
position: -11
scale: 1.3239385
}
}
layer {
name: "conv7_2_mbox_loc"
type: "Convolution"
bottom: "conv7_2"
top: "conv7_2_mbox_loc"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 24
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: -3
scale: 1.8314862
}
blobs_dtype {
type: DT_FIX8
position: -10
scale: 1.117411
}
}
layer {
name: "conv7_2_mbox_conf1"
type: "Convolution"
bottom: "conv7_2"
top: "conv7_2_mbox_conf1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 30
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: -3
scale: 1.8314862
}
blobs_dtype {
type: DT_FIX8
position: -11
scale: 1.4387759
}
}
layer {
name: "conv8_2_mbox_loc"
type: "Convolution"
bottom: "conv8_2"
top: "conv8_2_mbox_loc"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 16
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: -3
scale: 1.267179
}
blobs_dtype {
type: DT_FIX8
position: -10
scale: 1.289064
}
}
layer {
name: "conv8_2_mbox_conf1"
type: "Convolution"
bottom: "conv8_2"
top: "conv8_2_mbox_conf1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 20
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: -3
scale: 1.267179
}
blobs_dtype {
type: DT_FIX8
position: -11
scale: 1.3362272
}
}
layer {
name: "conv9_2_mbox_loc"
type: "Convolution"
bottom: "conv9_2"
top: "conv9_2_mbox_loc"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 16
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: -2
scale: 1.4884329
}
blobs_dtype {
type: DT_FIX8
position: -10
scale: 1.2053334
}
}
layer {
name: "conv9_2_mbox_conf1"
type: "Convolution"
bottom: "conv9_2"
top: "conv9_2_mbox_conf1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 20
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
bottom_mlu_dtype {
type: DT_FIX8
position: -2
scale: 1.4884329
}
blobs_dtype {
type: DT_FIX8
position: -11
scale: 1.302187
}
}
layer {
name: "detection_out"
type: "SsdDetection"
bottom: "conv4_3_norm_mbox_loc"
bottom: "fc7_mbox_loc"
bottom: "conv6_2_mbox_loc"
bottom: "conv7_2_mbox_loc"
bottom: "conv8_2_mbox_loc"
bottom: "conv9_2_mbox_loc"
bottom: "conv4_3_norm_mbox_conf1"
bottom: "fc7_mbox_conf1"
bottom: "conv6_2_mbox_conf1"
bottom: "conv7_2_mbox_conf1"
bottom: "conv8_2_mbox_conf1"
bottom: "conv9_2_mbox_conf1"
bottom: "conv4_3_norm"
bottom: "fc7"
bottom: "conv6_2"
bottom: "conv7_2"
bottom: "conv8_2"
bottom: "conv9_2"
bottom: "data"
top: "detection_out"
detection_output_param {
num_classes: 44
share_location: true
background_label_id: 0
nms_param {
nms_threshold: 0.45
top_k: 400
}
save_output_param {
}
code_type: CENTER_SIZE
keep_top_k: 200
confidence_threshold: 0.01
}
priorbox_params {
min_size: 30
max_size: 60
aspect_ratio: 2
flip: true
clip: false
variance: 0.1
variance: 0.1
variance: 0.2
variance: 0.2
}
priorbox_params {
min_size: 60
max_size: 111
aspect_ratio: 2
aspect_ratio: 3
flip: true
clip: false
variance: 0.1
variance: 0.1
variance: 0.2
variance: 0.2
}
priorbox_params {
min_size: 111
max_size: 162
aspect_ratio: 2
aspect_ratio: 3
flip: true
clip: false
variance: 0.1
variance: 0.1
variance: 0.2
variance: 0.2
}
priorbox_params {
min_size: 162
max_size: 213
aspect_ratio: 2
aspect_ratio: 3
flip: true
clip: false
variance: 0.1
variance: 0.1
variance: 0.2
variance: 0.2
}
priorbox_params {
min_size: 213
max_size: 264
aspect_ratio: 2
flip: true
clip: false
variance: 0.1
variance: 0.1
variance: 0.2
variance: 0.2
}
priorbox_params {
min_size: 264
max_size: 315
aspect_ratio: 2
flip: true
clip: false
variance: 0.1
variance: 0.1
variance: 0.2
variance: 0.2
}
}
量化具体操作
写ssd_float32_dense.prototxt文件
根据deploy.prototxt改成ssd_float32_dense.prototxt。数据层不改动,conv层组参数改整型,删除Permute、Flatten、PriorBox、Concat层,删除Reshape、Softmax层。
检测层:原来PriorBox的priorbox_params(浮点数改为整型)复制到DetectionOutput层,bottom按照实际改,detection_output_param不用动。具体改动结果上面已经给出。
写float32_convert_fix8.ini文件
我的1h8开发版上提供了直接量化工具,只需要修改float32_convert_fix8.ini内容。
[model]
original_models_path = model/ssd_float32_dense.prototxt # 待量化的原始网络结构文件
save_model_path = model/ssd_float32_dense.fix8.prototxt # 量化后网络结构文件
[data]
# 注意以下图片路径只能用其中一个
images_folder_path = ./file_list # 图片路径,里面写了验证集图片的路径
# images_db_path = /lmdb_path # lmdb数据路径
used_images_num = 32 # 迭代的次数。当网络batchsize为1,该值为8时,共迭代8次,读取8张图片;当网络的batchsize为4,该值为8时,共迭代8次,读取32张图片
[weights]
original_weights_path = model/VGG_gtsdb_voc_SSD_300x300_iter_60000.caffemodel # 待量化的.caffemodel权重文件
[preprocess]
mean = 104,117,123 # 均值
std = 1.0 # 缩小倍数,这个std参数会在生成的fix8网络的第一层卷积处,默认是1。
scale = 300, 300 # 图片路径images_folder_path时图片高和宽,即输入层是ImageData层。
crop = 300, 300 # 图片路径images_db_path时图片高和宽,即输入层是Data层。
[config]
int8_op_list = Conv, FC, LRN # 8bit算子列表
use_firstconv = 1 # 是否使用到第一层卷积
直接量化
这边的操作都是在我的虚拟机上
cd /home/jqy/jqy_nfs_server/HCAI1H_HOST_SDK/expr/e02_detection_ssd # 进入要量化的项目的根目录
export LD_LIBRARY_PATH=/home/jqy/jqy_nfs_server/HCAI1H_HOST_SDK/lib/x86 # 导入需要用到的库
../../tools/generate_fix8_pt -ini_file model/float32_convert_fix8.ini # 运行量化工具
处理量化后的文件ssd_float32_dense.fix8.prototxt
转换成寒武纪.cambricon 模型
cd /home/jqy/jqy_nfs_server/HCAI1H_HOST_SDK/expr/e02_detection_ssd/model
../../../tools/caffe genoff -model /home/jqy/jqy_nfs_server/HCAI1H_HOST_SDK/expr/e02_detection_ssd/model/ssd_float32_dense.fix8.prototxt -weights /home/jqy/jqy_nfs_server/HCAI1H_HOST_SDK/expr/e02_detection_ssd/model/VGG_gtsdb_voc_SSD_300x300_iter_60000.caffemodel -mname gtsdb_ssd -mcore 1H8 2>&1 | tee ./say.log

这一步我失败了,不知道怎么办,惆怅















 7350
7350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









