







数据结构-数组和广义表(第六章)的整理笔记,若有错误,欢迎指正。
特殊矩阵的压缩存储
共用体类型
- 当一个阶数较大的矩阵中的非零元素个数s相对于矩阵元素的总个数t非常小时,即s ≪ \ll ≪t时,称该矩阵为稀疏矩阵(sparse matrix)。
- 稀疏矩阵和特殊矩阵相比有一个明显的差异:特殊矩阵中特殊元素的分布具有某种规律,而稀疏矩阵中特殊元素(非零元素)的分布没有规律,即具有随机性。稀疏矩阵抽象数据类型与d(d=2)维数组抽象数据类型的描述相似。
稀疏矩阵的三元组表示
- 稀疏矩阵的压缩存储方法是只存储非零元素。由于稀疏矩阵中非零元素的分布没有任何规律,所以在存储非零元素时必须同时存储该非零元素对应的行下标、列下标和元素值。这样稀疏矩阵中的每一个非零元素由一个三元组 ( i , j , a i , j ) (i,j,a_{i,j}) (i,j,ai,j)唯一确定,稀疏矩阵中的所有非零元素构成三元组线性表。
例: 假设有一个6×7阶稀疏矩阵A:
A
6
×
7
=
[
0
0
1
0
0
0
0
0
2
0
0
0
0
0
3
0
0
0
0
0
0
0
0
0
5
0
0
0
0
0
0
0
6
0
0
0
0
0
0
0
7
4
]
A_{6×7}=\begin{bmatrix} 0 & 0 & 1 & 0 & 0 & 0 & 0\\ 0 & 2 & 0 & 0 & 0 & 0 & 0\\ 3 & 0 & 0 & 0 & 0 & 0 & 0\\ 0 & 0 & 0 & 5 & 0 & 0 & 0\\ 0 & 0 & 0 & 0 & 6 & 0 & 0\\ 0 & 0 & 0 & 0 & 0 & 7 & 4\\ \end{bmatrix}
A6×7=
003000020000100000000500000060000007000004
则稀疏矩阵A对应的三元组可表示为:
| 以行为主序: | i i i | j j j | a i , j a_{i,j} ai,j | 以列为主序: | i i i | j j j | a i , j a_{i,j} ai,j |
|---|---|---|---|---|---|---|---|
| (0,2,1) | 0 | 2 | 1 | (2,0,3) | 2 | 0 | 3 |
| (1,1,2) | 1 | 1 | 2 | (1,1,2) | 1 | 1 | 2 |
| (2,0,3) | 2 | 0 | 3 | (0,2,1) | 0 | 2 | 1 |
| (3,3,5) | 3 | 3 | 5 | (3,3,5) | 3 | 3 | 5 |
| (4,4,6) | 4 | 4 | 6 | (4,4,6) | 4 | 4 | 6 |
| (5,5,7) | 5 | 5 | 7 | (5,5,7) | 5 | 5 | 7 |
| (5,6,4) | 5 | 6 | 4 | (5,6,4) | 5 | 6 | 4 |
- 若把稀疏矩阵的三元组线性表按顺序存储结构存储,则称为稀疏矩阵的三元组顺序表,简称为三元组表(list of 3-tuples)。三元组顺序表的数据类型声明如下:
#include<stdio.h>
#define M <稀疏矩阵行数>
#define N <稀疏矩阵列数>
#define MaxSize <稀疏矩阵中非零元素最多的个数>
typedef int ElemType;
typedef struct
{
int r; //行号
int c; //列号
ElemType d; //元素值
}TupNode; //三元组类型
typedef struct
{
int rows; //行号
int cols; //列号
int nums; //非零元素个数
TupNode data[MaxSize];
}TSMatrix; //三元组顺序表的类型
- 其中,data域中表示的非零元素通常以行序为主序排列,即为一种下标按行有序的存储结构。
从一个二维稀疏矩阵创建其三元组表示
- 采用以行序为主序的方式扫描二维稀疏矩阵A,将其中非零的元素依次插人到三元组顺序表中。
void CreateMat(TSMatrix& t, ElemType A[M][N])
{
t.rows = M;
t.cols = N;
t.nums = 0;
for (int i = 0; i < M; i++)
{
for (int j = 0; j < N; j++)
if (A[i][j] != 0) //只存储非零元素
{
t.data[t.nums].r = i;
t.data[t.nums].c = j;
t.data[t.nums].d = A[i][j];
t.nums++;
}
}
}
三元组元素的赋值
- 该运算就是对于稀疏矩阵A执行A[i][j]=x(x通常是一个非零值)。先在三元组顺序表t中找到适当的位置k,如果该位置对应一个非零元素,将其d数据域修改为x;否则需要插入一个非零元素,将k~t.nums-1的元素均后移一个位置,再将非零元素x插入到
t.data[k]处。
bool Value(TSMatrix& t, ElemType x, int i, int j)
{
int k, k1;
if (i >= t.rows || j >= t.cols) return false; //i、j参数超界,返回假
while (k < t.nums && t.data[k].r < i) k++; //查找第i行的第一个非0元素
while (k < t.nums && t.data[k].r == i && t.data[k].c < j) k++; //在第i行的非0元素中查找第j列
if (t.data[k].r == i && t.data[k].c == j) t.data[k].d = x; //若存在这样的非0元素,修改非0元素的值
else //若不存在这样的非0元素,若干元素均后移一个位置
{
for (k1 = t.nums - 1; k1 >= k; k1--)
{
t.data[k1 + 1].r = t.data[k1].r;
t.data[k1 + 1].c = t.data[k1].c;
t.data[k1 + 1].d= t.data[k1].d;
}
t.data[k].r = i; //插入非零元素x
t.data[k].c = j;
t.data[k].d = x;
t.nums++; //非0元素个数增1
}
return true; //操作成功后返回真
}
将指定位置的元素值赋给变量
- 该运算就是对于稀疏矩阵A执行x=A[i][j],即提取A中指定下标的元素值。先在三元组顺序表中查找指定的位置,若找到了,说明是一个非零元素,将其值赋给x;否则说明是零元素,置x=0。
bool Assign(TSMatrix& t, ElemType& x, int i, int j)
{
int k = 0;
if (i >= t.cols && j >= t.rows) return false;
while (k < t.nums && t.data[k].r < i) k++;
while (k < t.nums && t.data[k].r == i && t.data[k].c < j) k++;
if (t.data[k].r == i && t.data[k].c == j) x = t.data[k].d;
else x=0;
return true;
}
输出三元组
- 该运算从头到尾扫描三元组顺序表t,依次输出元素值。
void DispMat(TSMatrix t)
{
if (t.nums <= 0) return; //没有非零元素时直接返回
printf("\t%d\t%d\t%d\n", t.rows, t.cols, t.nums);
printf("\t-------------------------\n");
for (int k = 0; k < t.nums; k++) //输出所有非0元素
printf("\t%d\t%d\t%d\n", t.data[k].r, t.data[k].c, t.data[k].d);
}
稀疏矩阵转置后的三元组
- 该运算对于一个m×n的稀疏矩阵 A m × n A_{m×n} Am×n,求其转置矩阵 A n × m A_{n×m} An×m,即 b i , j = a j , i b_{i,j}=a_{j,i} bi,j=aj,i,其中 0 ≤ i ≤ m − 1 , 0 ≤ j ≤ n − 1 0≤i≤m-1,0≤j≤n-1 0≤i≤m−1,0≤j≤n−1。采用的算法思路是A对应的三元组顺序表为t,其转置矩阵B对应的三元组顺序表为tb。按v=0,1,…,t.cols在t中找列号为v的元素,每找到一个这样的元素,将行、列交换后添加到tb中。
void TranTup(TSMatrix& t, TSMatrix& tb)
{
int k1 = 0; //k1记录tb中的元素个数
tb.rows = t.rows;
tb.cols = t.cols;
tb.nums = t.nums;
if (t.nums <= 0) return; //没有非零元素时直接返回
for (int v = 0; v < t.cols; v++) //当存在非零元素时执行转置,按v=0、1、...、t.cols循环
{
for (int k = 0; k < t.nums; k++) //k用于扫描t.data的所有元素
if (t.data[k].c == v) //找到一个列号为v的元素
{
tb.data[k1].r = t.data[k].c; //将行、列交换后添加到tb中
tb.data[k1].c = t.data[k].r;
tb.data[k1].d = t.data[k].d;
k1++; //tb中元素的个数增1
}
}
}
- 该算法中含有两重for循环,其时间复杂度为O(t.cols×t.nums)。最坏的情况是当稀疏矩阵中的非零元素个数t.nums和m×n同数量级时,时间复杂度为 O ( m × n 2 ) O(m×n^2) O(m×n2),所以这不是一种高效的算法。
完整代码
#include<stdio.h>
#define M 6
#define N 7
#define MaxSize 42
int A[M][N] = { {0,0,1,0,0,0,0},{0,2,0,0,0,0,0},{3,0,0,0,0,0,0,},
{0,0,0,5,0,0,0},{0,0,0,0,6,0,0},{0,0,0,0,0,7,4} };
typedef int ElemType;
typedef struct
{
int r; //行号
int c; //列号
ElemType d; //元素值
}TupNode; //三元组类型
typedef struct
{
int rows; //行号
int cols; //列号
int nums; //非零元素个数
TupNode data[MaxSize];
}TSMatrix; //三元组顺序表的类型
//--------三元组的操作---------
void CreateMat(TSMatrix& t, ElemType A[M][N]) //从一个二维稀疏矩阵创建其三元组表示
{
t.rows = M;
t.cols = N;
t.nums = 0;
for (int i = 0; i < M; i++)
{
for (int j = 0; j < N; j++)
if (A[i][j] != 0) //只存储非零元素
{
t.data[t.nums].r = i;
t.data[t.nums].c = j;
t.data[t.nums].d = A[i][j];
t.nums++;
}
}
}
bool Value(TSMatrix& t, ElemType x, int i, int j) //三元组元素的赋值
{
int k=0, k1;
if (i >= t.rows || j >= t.cols) return false; //i、j参数超界,返回假
while (k < t.nums && t.data[k].r < i) k++; //查找第i行的第一个非0元素
while (k < t.nums && t.data[k].r == i && t.data[k].c < j) k++; //在第i行的非0元素中查找第j列
if (t.data[k].r == i && t.data[k].c == j) t.data[k].d = x; //若存在这样的非0元素,修改非0元素的值
else //若不存在这样的非0元素,若干元素均后移一个位置
{
for (k1 = t.nums - 1; k1 >= k; k1--)
{
t.data[k1 + 1].r = t.data[k1].r;
t.data[k1 + 1].c = t.data[k1].c;
t.data[k1 + 1].d= t.data[k1].d;
}
t.data[k].r = i; //插入非零元素x
t.data[k].c = j;
t.data[k].d = x;
t.nums++; //非0元素个数增1
}
return true; //操作成功后返回真
}
bool Assign(TSMatrix& t, ElemType& x, int i, int j) //将指定位置的元素值赋给变量
{
int k = 0;
if (i >= t.cols && j >= t.rows) return false;
while (k < t.nums && t.data[k].r < i) k++;
while (k < t.nums && t.data[k].r == i && t.data[k].c < j) k++;
if (t.data[k].r == i && t.data[k].c == j) x = t.data[k].d;
else x=0;
return true;
}
void DispTup(TSMatrix t) //输出三元组
{
if (t.nums <= 0) return; //没有非零元素时直接返回
printf("\t%d\t%d\t%d\n", t.rows, t.cols, t.nums);
printf("\t------------------\n");
for (int k = 0; k < t.nums; k++) //输出所有非0元素
printf("\t%d\t%d\t%d\n", t.data[k].r, t.data[k].c, t.data[k].d);
}
void TranTup(TSMatrix& t, TSMatrix& tb) //稀疏矩阵转置后的三元组
{
int k1 = 0; //k1记录tb中的元素个数
tb.rows = t.rows;
tb.cols = t.cols;
tb.nums = t.nums;
if (t.nums <= 0) return; //没有非零元素时直接返回
for (int v = 0; v < t.cols; v++) //当存在非零元素时执行转置,按v=0、1、...、t.cols循环
{
for (int k = 0; k < t.nums; k++) //k用于扫描t.data的所有元素
if (t.data[k].c == v) //找到一个列号为v的元素
{
tb.data[k1].r = t.data[k].c; //将行、列交换后添加到tb中
tb.data[k1].c = t.data[k].r;
tb.data[k1].d = t.data[k].d;
k1++; //tb中元素的个数增1
}
}
}
//-----------矩阵的操作---------
void DispMat(ElemType A[M][N]) //输出矩阵
{
for (int i = 0; i < M; i++)
{
for (int j = 0; j < N; j++)
printf("\t%d ", A[i][j]);
printf("\n");
}
}
void DispTranMat(ElemType B[N][M]) //输出矩阵的转置
{
for (int i = 0; i < N; i++)
{
for (int j = 0; j < M; j++)
printf("\t%d ", B[i][j]);
printf("\n");
}
}
void TranMat(ElemType B[N][M]) //矩阵转置
{
for (int i = 0; i < N; i++)
for (int j = 0; j < M; j++)
B[i][j] = A[j][i];
}
void ValueMat(ElemType A[M][N], ElemType x, int i, int j) //修改矩阵对应位置的值
{
for (int m = 0; m < N; m++)
for (int n = 0; n < M; n++)
if (m == i && n == j) A[m][n] = x;
}
int main()
{
TSMatrix t, tb;
ElemType B[N][M], x;
int i, j;
CreateMat(t,A);
printf("输出稀疏矩阵A:\n");
DispMat(A);
printf("\n输出稀疏矩阵A的三元组:\n");
DispTup(t);
TranMat(B);
printf("\n输出稀疏矩阵A的转置矩阵B:\n");
DispTranMat(B);
TranTup(t, tb);
printf("\n输出稀疏矩阵A的转置矩阵B的三元组:\n");
DispTup(tb);
x = 8, i = 3, j = 2;
printf("\n三元组元素的赋值(A[%d][%d])=%d:\n", i, j, x);
Value(t, x, i, j);
DispTup(t);
i = 4, j = 4;
Assign(t, x, i, j);
printf("\n矩阵中A[%d][%d]的值为:%d", i, j, x);
return 0;
}
程序分析
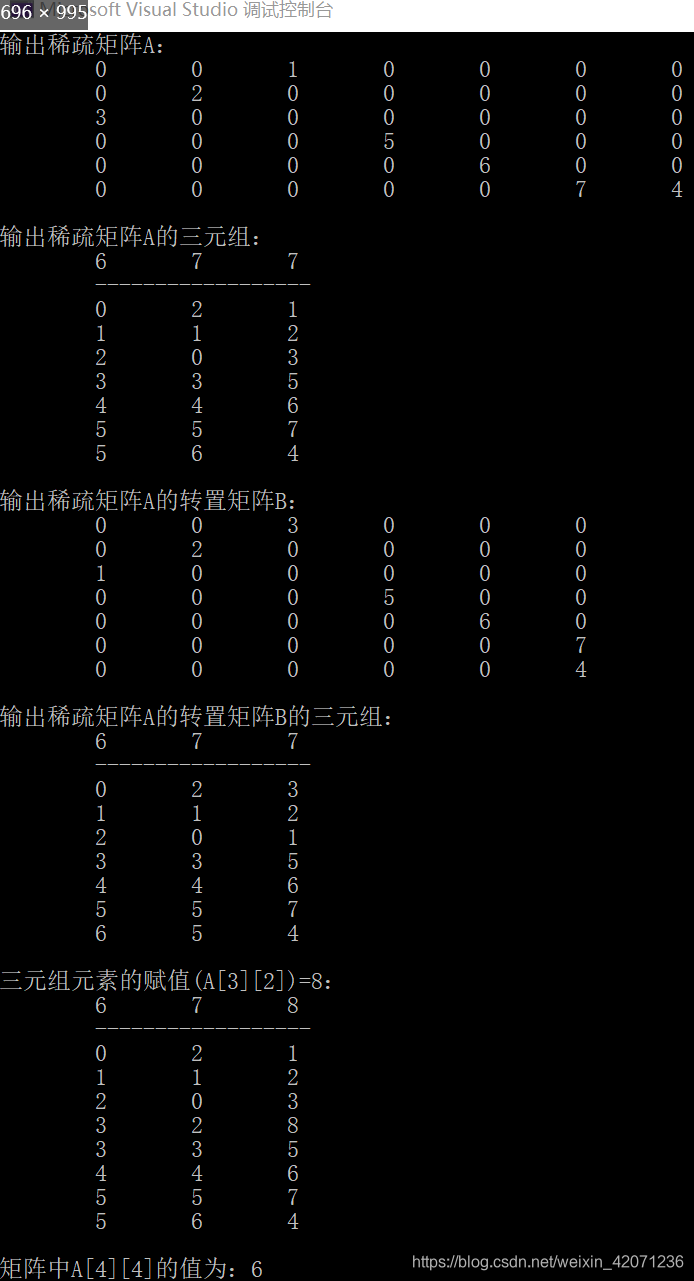
- 从以上可以看出,稀疏矩阵采用三元组顺序表存储后,当非零元素个数较少时会在一定程度上节省存储空间。如果用一个二维数组直接存储稀疏矩阵,此时具有随机存取特性,但采用三元组顺序表存储后会丧失随机存取特性。
稀疏矩阵的十字链表表示
- 十字链表(orthogonal list)是稀疏矩阵的一种链式存储结构(相应的,前面的三元组顺序表是稀疏矩阵的一种顺序存储结构)。
例: 假设有一个3×4阶稀疏矩阵B:
B
3
×
4
=
[
1
0
0
2
0
0
3
0
0
0
0
4
]
B_{3×4}=\begin{bmatrix} 1 & 0 & 0 & 2\\ 0 & 0 & 3 & 0\\ 0 & 0 & 0 & 4\\ \end{bmatrix}
B3×4=
100000030204
- 创建稀疏矩阵B的十字链表的步骤如下:
- 对于稀疏矩阵中每个非零元素创建一个结点存放它,包含元素的行号、列号和元素值。这里有4个非零元素,创建4个数据结点。
- 将同一行的所有结点构成一个带头结点的循环单链表,行号为i的单链表的头结点为hr[i]。这里有3行,对应有3个循环单链表,头结点分别为hr[0]~hr[2]。hr[i](0≤i≤2)头结点的行指针指向行号为i的单链表的首结点。
- 将同一列的所有结点构成一个带头结点的循环单链表,列号为j的单链表的头结点为hd[j]。这里有4列,对应有4个循环单链表,头结点分别为hd[0]~hd[3]。hd[j](0≤j≤3)头结点的列指针指向列号为j的单链表的首结点。
- 由此创建了3+4=7个循环单链表,头结点的个数也为7个。实际上,可以将hr[i]和hd[j]合起来变为h[i],即h[i]同时包含有行指针和列指针。h[i](0≤i≤2)头结点的行指针指向行号为i的单链表的首结点,h[i](0≤i≤3)头结点的列指针指向列号为i的单链表的首结点,这样头结点的个数为MAX{3,4}=4个。
- 再将所有头结点h[i](0≤i≤3)连起来构成一个带头结点的循环单链表,这样需要增加一个总头结点hm,总头结点中存放稀疏矩阵的行数和列数等信息。
稀疏矩阵B的十字链表:
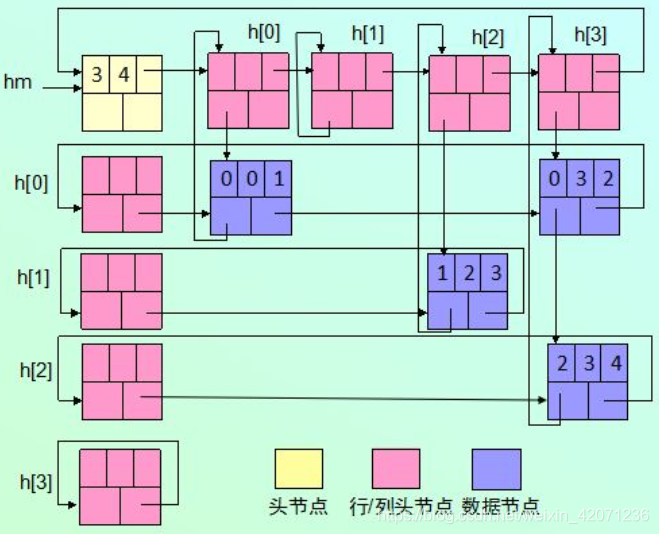
- 每个非零元素就好比在一个十字路口,由此称为十字链表。
- 在稀疏矩阵的十字链表中包含两种类型的结点,一种是存放非零元素的数据结点,另一种是头结点。
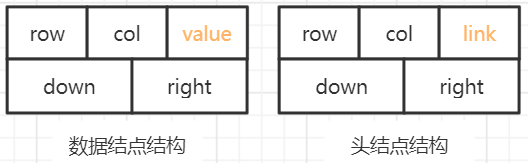
- 为了方便算法设计,将两种类型的结点统一起来,设计稀疏矩阵的十字链表的结点类型MaxNode如下:
#include<stdio.h>
#define M<稀疏矩阵行数>
#define N<稀疏矩阵列数>
#define Max (M>N?M:N) //三目运算符,取矩阵行列的较大者
typedef int ElemType;
typedef struct MatNode
{
int row; //行号或者行数
int col; //列号或者列数
struct MatNode* right, * down; //行、列指针
union //共用体
{
ElemType value; //非零元素值
struct MatNode* link; //指向下一个头结点
}tag;
};
- 从中可以看出,在十字链表中行、列头结点是共享的,而且采用头结点数组存储,通过头结点h[i]的h[i]->right指针可以逐行搜索行下标为i的所有非零元素,h[i]->down指针可以逐列搜索列下标为i的所有非零元素。每一个非零元素同时包含在两个链表中,方便算法中行方向和列方向的搜索,因而大大降低了算法的时间复杂度。
- 对于一个m×n的稀疏矩阵,总的头结点个数为MAX{m,n}+1。
广义表
广义表的定义
- 广义表(generalized table)是线性表的推广,是有限个元素的序列,其逻辑结构采用括号表示法为:GL=(a₁,a₂,…,aᵢ,…,aₙ)。其中,n表示广义表的长度,即广义表中所含元素的个数,n≥0。若n=0,称为空表。aᵢ为广义表的第i个元素,如果aᵢ属于原子类型(原子类型是不可分解的),称为广义表GL的原子(atom);如果aᵢ又是一个广义表,称为广义表GL的子表(subgeneralized table)。
- 广义表具有以下特性:
- 广义表中的数据是有相对次序的
- 广义表的长度定义为最外层包含元素的个数
- 广义表的深度定义为所含括弧的重数,其中原子的深度为0,空表的深度为1
- 广义表可以共享,一个广义表可以被其他广义表共享,这种共享广义表称为再入表
- 广义表可以是一个递归的表,一个广义表可以是自己的子表,这种广义表称为递归表
广义表的表头和表尾
当广义表不是空表时,称第一个数据(原子或子表)为"表头",剩下的数据构成的新广义表为"表尾"。
除非广义表为空表,否则广义表一定具有表头和表尾,且广义表的表尾一定是一个广义表。
例:
A
=
(
(
(
a
,
b
,
(
)
,
c
)
,
d
)
,
e
,
(
(
f
)
,
g
)
)
A=(((a,b,(),c),d),e,((f),g))
A=(((a,b,(),c),d),e,((f),g))

- 表头是: ( ( a , b , ( ) , c ) , d ) ((a,b,(),c),d) ((a,b,(),c),d),表尾是 ( e , ( ( f ) , g ) ) (e,((f),g)) (e,((f),g))
- 长度(红框的部分)是:3,深度(括弧的重数,蓝色点的地方)是:4
以上广义表可以看成 A = ( B , C , D ) A=(B,C,D) A=(B,C,D),A中含有3个元素:B、C、D;- 其中,B又是一个子表,可以看成 B = ( E , F ) B=(E,F) B=(E,F),E又是一个子表,有三个原子(a,b,c)以及一个空表();F只含有单个原子d
- C是含有单个原子e
- D又是一个子表,可以看成 D = ( G , H ) D=(G,H) D=(G,H),G是一个只有单个原子f的表,H只含单个原子g。
!A = () 和 A = (()) 是不一样的。前者是空表,而后者是包含一个子表的广义表,只不过这个子表是空表。
广义表的存储结构
- 广义表是一种递归的数据结构,因此很难为每个广义表分配固定大小的存储空间,所以其存储结构只好采用链式存储结构。
从上图可以看到,广义表有两类结点,一类为圆圈结点,在这里对应子表;另一类为方形结点,在这里对应原子。
为了使子表和原子两类结点既能在形式上保持一致,又能进行区别,可采用以下结构形式:

- 其中,tag域为标志字段,用于区分两类结点,即由tag决定是使用结点的sublist还是data域:
- 若tag=0,表示该结点为原子结点,则第2个域为data,存放相应原子元素的信息;
- 若tag=1,表示该结点为表/子表结点,则第2个域为sublist,存放相应表/子表中第一个元素对应结点的地址。
- link域存放同一层的下一个元素对应结点(兄弟结点)的地址,当没有兄弟结点时,其link域为NULL。
广义表的结点类型GLNode声明如下:
typedef struct lnode
{
int tag; //结点类型标识
union
{
ElemType data; //存放原子值
struct lnode* sublist; //指向子表的指针
}val;
struct lnode* link; //指向下一个元素
}GLNode; //广义表的结点类型
定义中使用了union共用体,因为同一时间此结点不是原子结点就是子表结点,当表示原子结点时,就使用data变量;反之则使用结构体。
例如,广义表
A
=
(
(
(
a
,
b
,
(
)
,
c
)
,
d
)
,
e
,
(
(
f
)
,
g
)
)
A=(((a,b,(),c),d),e,((f),g))
A=(((a,b,(),c),d),e,((f),g))用该存储结构的存储示意图如下:

由于最顶层(蓝框部分)表示的是此广义表,而第二层(红框部分)表示的才是该广义表中包含的数据元素,因此可以通过计算第二层中包含的结点数量,求得广义表的长度为3。
广义表的复制
广义表的复制思想 : 任意一个非空广义表来说,都是由两部分组成:表头和表尾。反之,只要确定的一个广义表的表头和表尾,那么这个广义表就可以唯一确定下来。因此复制一个广义表,也是不断的复制表头和表尾的过程。如果表头或者表尾同样是一个广义表,依旧复制其表头和表尾。
复制广义表的过程,其实就是不断的递归复制广义表中表头和表尾的过程,递归的出口有两个:
- 如果当前遍历的数据元素为空表,则直接返回空表。
- 如果当前遍历的数据元素为该表的一个原子,那么直接复制,返回即可














 1855
1855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









