







设计ー个算法,求ー元二次方程 a x 2 + b x + c = 0 ax^2+bx+c=0 ax2+bx+c=0的根。(P17 例1-5)
- 解:该算法的输入为a、b和c,输出为根的个数和两个根,将a、b和c作为输人型形参,采用函数的返回值表示根的个数,用两个引用型形参x1和x2表示两个根。
//【例1.5】的算法:求一元二次方程的根
#include <stdio.h>
#include <math.h>
int solution(double a,double b,double c,double &x1,double &x2)
{
double d;
d=b*b-4*a*c;
if (d>0)
{ x1=(-b+sqrt(d))/(2*a);
x2=(-b-sqrt(d))/(2*a);
return 2; //2个实根
}
else if (d==0)
{ x1=(-b)/(2*a);
return 1;//1个实根
}
else return 0; //d<0的情况,不存在实根
}
int main()
{
double a=2,b=-6,c=3;
double x1,x2;
int s=solution(a,b,c,x1,x2);
if (s==1) printf("一个根:x=%lf\n",x1);
else if (s==2) printf("两个根:x1=%lf,x2=%lf\n",x1,x2);
else printf("没有根\n");
return 1;
}
P22 例1-9
//【例1.9】的算法:分析递归算法的时间复杂度
#include <stdio.h>
void fun(int a[],int n,int k) //数组a共有n个元素,执行时间为T1(n,k)
{
int i;
if (k==n-1) for (i=0;i<n;i++) printf("%d\n",a[i]); //该语句执行次数为n
else
{
for (i=k;i<n;i++) a[i]=a[i]+i*i; //该语句执行次数为n-k
fun(a,n,k+1); //执行时间为T1(n,k+1)
}
}
int main()
{
int a[10]={0};
fun(a,10,0);
return 1;
}
《数据结构》上机实验(第九章) —查找
线性表中各结点的检索概率不等时,可用如下策略提高顺序检索的效率:若找到指定的结点,则将该结点和其前驱结点(若存在)交换,使得经常被检索的结点尽量位于表的前端。试设计在顺序结构和链式结构的线性表上实现上述策略的顺序检索算法。
使用顺序结构
int SeqSrch(RecType R[], int n, KeyType k)
{
int i = 0, temp;
while(i<n)
{
if (R[i].key == k)
{
temp = R[i].key;
R[i].key = R[i - 1].key;
R[i - 1].key = temp;
return i;
}
else i++;
}
return 0;
}
运行结果
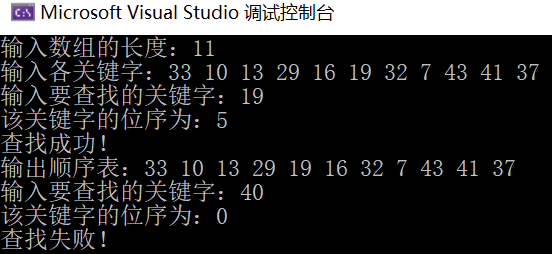
使用链式结构
int SeqSrch(LinkList& L, int n, KeyType k)
{
int i = 1;
LNode* p = L->next, * q, * r;
if (p->data == k) return i; //第一个元素与关键值相等
else if (p->next->data == k) //第二个元素与关键值相等
{
q = p->next;
L->next = q;
p->next = q->next;
q->next = p;
return i;
}
else //其他情况
{
i = 3; //位序从3开始
r = p; //当前结点的前驱结点的前驱结点(初始指向单链表中第一个结点)
q = p->next; //当前结点的前驱结点(初始指向单链表中第二个结点)
p = p->next->next; //当前结点(初始指向单链表中第三个结点)
while (p != NULL)
{
if (p->data != k) //当前结点的数据域与关键值不匹配
{
i++; //位序增加
p = p->next; //三个指针同步后移
q = q->next;
r = r->next;
}
else //找到与关键值相等的数据域结点
{
r->next = p; //将当前结点与其前驱结点进行交换
q->next = p->next;
p->next = q;
return i - 1; //返回交换后的位序
}
}
return 0; //查找失败,返回0
}
}
运行结果















 465
465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









