







代码1:
def fibRate(n):
if n <= 0:
return -1
elif n == 1:
return -1
elif n == 2:
return 1
else:
L = [1,5]
for i in range(2,n):
L.append(L[-1] + L[-2])
return L[-2] % L[-1]
print(fibRate(7))
n = 7
L = [1,5]
i = 2 , 3 , 4 , 5 , 6
i = 2 -> L[-1] + L[-2] = 5 + 1 = 6 -> L = [1,5,6]
i = 3 -> L[-1] + L[-2] = 6 + 5 = 11 -> L = [1,5,6,11]
i = 4 -> L[-1] + L[-2] = 11 + 6 = 17 -> L = [1,5,6,11,17]
i = 5 -> L[-1] + L[-2] = 17 + 11 = 28 -> L = [1,5,6,11,17,28]
i = 6 -> L[-1] + L[-2] = 28 + 17 = 45 -> L = [1,5,6,11,17,28,45]
L[-2] % L[-1] = 28 % 45
代码2:
d = {}
for i in range(26):
d[chr(i + ord("A"))] = chr((i + 13) % 26 + ord("A"))
for c in "Python":
print(d.get(c,c),end = "")
i = 0 ~ 25
i = 0 -> d[A] = N
…
i = 12 -> d[M] = Z
i = 13 -> d[N] = A
代码3:
list1 = [[0,1,2],"123.0","Python"]
a = all(list1[0])
b = list1[1].split(".")
c = ascii(list1[2])
print(a,b,c)
all(x)函数当组合类型变量x中所有元素为真时返回True,否则返回False,元素除了是0、None、False外都算True。所以a的值为False;
b中split 是字符串分隔函数,返回分隔后的值应为[‘123’,‘0’];
c中ascii()的参数是字符串’python’,所以返回’python’。
代码4:
f = (lambda a = "hello",b = "python",c = "world":a+b.split("o")[1]+c)
print(f("hi"))
f(“hi”) -> a=“hi”,b=“python”,c=“world”
b.split(“o”)=[“pyth”,“n”]
a+b.split(“o”)[1]+c=“hi”+“n”+“world”=“hinworld”
代码5:
getstring = "TTBEGCCCENDGGGBEGENTTCEND"
i = 0
while i <len(getstring) - 2:
start = gestring.find("BEG", i)
if start == -1:
break
else:
end = gestring.find("END", i)
if end == -1:
break
else:
print(gestring[start + 3 : end])
i = end + 3
i的取值范围:0~22
i=0
start=2(第一个“BEG”出现的下标,下标从0开始)
end=8(第一个“END”出现的下标,下标从0开始)
gestring[5,8]=CCC
i=11
start=14(第一个“BEG”出现的下标,下标从11开始)
end=22(第一个“END”出现的下标,下标从11开始)
gestring[17,22]=ENTTC
i=25(不满足while条件,退出循环)
代码7:
x = [90,87,93]
y = ("Aele","Bob","lala")
z = {}
for i in range(len(x)):
z[i] = list(zip(x,y))
print(z)
#输出结果:{0: [(90,'Aele'), (87,'Bob'), (93, 'lala')], 1: [(90, 'Aele'), (87, 'Bob'), (93, 'lala')], 2: [(90, 'Aele'), (87, 'Bob').(93,'lala')]}
代码8:
tb = {'yingyu':20,'shuxue':30,'yuwen':40}
stb = {}
for it in tb.items():
print(it)
stb[it[1]] = it[0]
print(stb)
#输出结果:{40:'yuwen',20:'yingyu',30:'shuxue'}
代码9:
str1 ='||北京大学||'
print(str1.strip('|').replace('北京','南京'))
#输出:南京大学
strip()方法是去除字符串首尾两端与参数相同的字符,无论数量
代码10:
ss = [2, 3, 6, 9, 7, 1]
for i in ss:
ss.remove(min(ss))
print(min(ss), end=",")
#输出:2,3,6,
- 第一次循环:
移除最小值1,剩余列表为 [2, 3, 6, 9, 7]
输出当前最小值 2,打印:2,- 第二次循环:
移除最小值2,剩余列表为 [3, 6, 9, 7]
输出当前最小值 3,打印:2,3,
第三次循环:- 移除最小值3,剩余列表为 [6, 9, 7]
输出当前最小值 6,打印:2,3,6,
(在这个点上,迭代已经结束,因为列表ss不再包含索引2。)
在 Python 中,for循环是通过迭代器(iterator)来实现的。迭代器是一个对象,它提供了一个 next() 方法,用于逐个返回容器中的元素。
for i in ss:迭代语句使用了ss列表的迭代器。迭代器在迭代的过程中会记录当前位置,在第三次循环结束之后,循环并没有继续执行。这是因为在迭代列表的同时修改了列表,使之列表的索引下标也改变了。
代码11:
letter = ['A','B','C','D','D','D']
for i in letter:
if i == 'D':
letter.remove(i)
print(letter)
#输出:['A','B','C','D']
- 第一次循环(索引为0):i == ‘A’ ≠ ‘D’
- 第二次循环(索引为1):i == ‘B’ ≠ ‘D’
- 第三次循环(索引为2):i == ‘A’ ≠ ‘D’
- 第三次循环(索引为3):i == ‘D’ 移除第一个D
剩余列表为 [‘A’,‘B’,‘C’,‘D’,‘D’]- 第四次循环(索引为4):i == ‘D’ 移除第二个D
剩余列表为 [‘A’,‘B’,‘C’,‘D’]
(在这个点上,迭代已经结束,因为列表letter不再包含索引4。)
列表中的最后一个D未删除
代码12:
文件a.txt的内容如下:[1,2,3,4]
f = open('a.txt','r')
print(f.read().split(','))
f.close()
#输出:['['1','2','3','4']']
代码13:
fo = open("a.txt","w")
x = ['天','地','人']
#fo.writelines()的写入结果是天地人
fo.writelines(','.join(x))
fo.close()
首先打开文件,然后使用文件的writelines()方法写入数据,数据是列表x通过逗号连接内部所有元素,所以写入文件的字符串为“天,地,人”,因为写入文件不会含有引号,所以文件的内容为:天,地,人
代码14:
ls = [1,2,3.7,4,5]
s = ls[3:4]
print(s) #输出:[4]
print(type(s)) #输出:<class 'list'>
t = ls[3]
print(t) #输出:4
print(type(t)) #输出:<class 'int'>
代码15:
print(list({"a":1,"b":2}))
#输出:['a', 'b']
list()函数的参数需要是多元素数据类型,比如元组,字符串,字典等当直接转换字典的时候,是对字典的键进行操作,等于舍弃字典的值
代码16:
animal = "cat","dog","tiger","rabbit"
print(animal)
#输出:('cat', 'dog', 'tiger', 'rabbit')
直接将多个元素通过逗号赋值给一个变量,会自动将数据加上括号形成元组进行赋值
范式:
- 1NF(第一范式):
1NF要求表中的每一列都必须包含原子(不可分割)的值,且不应存在重复的分组或数组。
例:
考虑一个表示学生信息的表:
| 学生ID | 学生姓名 | 课程 |
|---|---|---|
| 1 | 约翰·多伊 | 数学,物理 |
| 2 | 简·史密斯 | 化学,生物 |
| 3 | 鲍勃·约翰逊 | 数学 |
这个表不符合1NF,因为“课程”列包含由逗号分隔的多个值。
- 2NF(第二范式):
2NF建立在1NF的基础上,此外要求非关键属性在功能上完全依赖于主键。
例:
考虑一个表示订单和订单项的表:
| 订单ID | 商品ID | 商品名称 | 数量 |
|---|---|---|---|
| 1 | 101 | 笔记本 | 2 |
| 1 | 102 | 鼠标 | 1 |
| 2 | 101 | 笔记本 | 1 |
| 2 | 103 | 键盘 | 1 |
在这个表中,复合键是(订单ID,商品ID),而非关键属性“商品名称”仅依赖于键的一部分(商品ID),而不是整个键。
- 3NF(第二范式):
第三范式 (3NF) 要求表中的非主属性不能依赖于其他非主属性。也就是说,表必须同时满足1NF和2NF,并且没有传递依赖关系。
例:考虑一个表示学生课程的表:
| 学生ID | 学生姓名 | 课程ID | 课程名称 | 教师姓名 |
|---|---|---|---|---|
| 1 | 约翰·多伊 | 101 | 数学 | 张老师 |
| 1 | 约翰·多伊 | 102 | 物理 | 王老师 |
| 2 | 简·史密斯 | 101 | 数学 | 张老师 |
| 2 | 简·史密斯 | 103 | 化学 | 李老师 |
| 3 | 鲍勃·约翰逊 | 102 | 物理 | 王老师 |
这个表没有达到3NF,因为教师姓名(TeacherName)依赖于课程ID(CourseID),而课程ID只是主键的一部分。
例1:
R(C#,Cn,T,Ta)(其中C#为课程号,Cn为课程名,T为教师名,Ta为教师地址)并且假定不同课程号可以有相同的课程名,每门课程只有一位任课教师,但每位教师可以有多门课程。
- 1NF(第一范式):
关系 R 已经满足第一范式,因为每个属性都包含原子值,没有多值属性或重复组。- 2NF(第二范式):
第二范式要求非主属性完全依赖于候选键。在这里,候选键可以是 {C#} 或者 {Cn}。
Cn (课程名) 对于 {C#} 是部分依赖的,因为 Cn 可能相同。
T (教师名) 和 Ta (教师地址) 对于 {C#} 或 {Cn} 都是完全依赖的。- 考虑到 Cn 的部分依赖,我们可以将关系 R 进一步分解,确保非主属性完全依赖于候选键。
拆分关系为两个:
关系 R1(C#, T, Ta)
主键:{C#}
T (教师名) 和 Ta (教师地址) 对于 {C#} 是完全依赖的。
关系 R2(C#, Cn)
主键:{C#}
Cn (课程名) 对于 {C#} 是完全依赖的。
这样,每个关系都满足第二范式。- 3NF(第三范式):
第三范式要求非主属性不传递依赖于候选键。在这里,候选键可以是 {C#} 或者 {Cn}。
T 和 Ta 对于 {C#} 或 {Cn} 不是传递依赖的。
由于 T 和 Ta 只依赖于候选键的一部分,这违反了第三范式的要求。
关系模式R范式最高是第二范式(2NF)
例2:
某图书集团数据库中有关系模式R(书店编号,书籍编号,库存数量,部门编号,部门负责人),其中要求:(1)每个书店的每种书籍只在该书店的一个部门销售;(2)每个书店的每个部门只有一个负责人;(3)每个书店的每种书籍只有一个库存数量。
关系模式R范式最高是第二范式(2NF)
例3:
定义学生、教师和课程的关系模式S(S#,Sn,Sd,Dc,Sa)(其属性分别为学号、姓名、所在系、所在系的系主任、年龄);C(C#,Cn,P#)(其属性分别为课程号、课程名、先修课);SC(S#,C#,G)(其属性分别为学号、课程号和成绩)。包含对非主属性部分依赖的关系是(S(S#,Sn,Sd,Dc,Sa))。包含对主属性传递依赖的是S#→Sd,Sd→Dc。
在关系模式S中,主键为S,但有Sd→Dc,Sd为非主属性,存在对非主属性部依赖。
例4:
学生选修课程的关系模式为SC(S#,Sn,Sd,Sa,C#,G)(其属性分别为学号、姓名、所在系、年龄、课程号和成绩);C(C#,Cn,P#)(其属性分别为课程号、课程名、先选课)。关系模式中包含对主属性部分依赖的是S#→Sd。
例5:
定义学生选修课程的关系模式如下:S(S#,Sn,Sd,Sa)(其属性分别为学号、姓名、所在系、年
龄);C(C#,Cn,P#)(其属性分别为课程号、课程名、先选课);SC(S#,C#,G)(其属性分别学号、课号和成绩)。检索选修了课程号为2且成绩不及格的学生的姓名的表达式是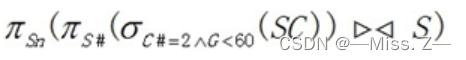
S
| 学号S# | 姓名Sn | 所在系Sd | 年龄Sa |
|---|---|---|---|
| 1 | John Doe | Computer Science | 20 |
| 2 | Jane Smith | Physics | 22 |
| 3 | Bob Johnson | Mathematics | 21 |
C
| 课程号C# | 课程名Cn | 先选课P# |
|---|---|---|
| 1 | Database Systems | NULL |
| 2 | Data Structures | NULL |
| 3 | Physics 101 | 1 |
SC
| 学号S# | 课程号C# | 成绩G |
|---|---|---|
| 1 | 1 | 90 |
| 1 | 2 | 55 |
| 2 | 3 | 65 |
| 3 | 1 | 78 |
| 3 | 2 | 82 |
选择(σ):从行的角度进行的运算
投影(π):从列的角度进行的运算
连接(⋈):自然连接-要求两个关系中进行比较的分量必须是同名的属性组,并且在结果中把重复的属性列去掉。
逻辑与(∧):在数据库查询中,它通常用于指定多个条件的交集,只有同时满足所有条件的元组才会被选取或操作。
π_Sn(π_S#(σ_C# = 2 ∧ G < 60 (SC)) ⨝ S)解析:
σ_C# = 2 ∧ G < 60 (SC):在关系SC表中筛选出 课程号为2(C#)且成绩不及格(G) 的行π_S#(σ_C# = 2 ∧ G < 60 (SC):在第①步的结果基础上,只保留学号(S#)列π_S#(σ_C# = 2 ∧ G < 60 (SC)) ⨝ S:在第②步的结果基础上,与关系表S进行连接操作π_Sn(π_S#(σ_C# = 2 ∧ G < 60 (SC)) ⨝ S):连接完成后,只保留姓名(Sn)列
检索选修课程名为“操作系统”的成绩在90分以上(含90分)的学生姓名的表达式是
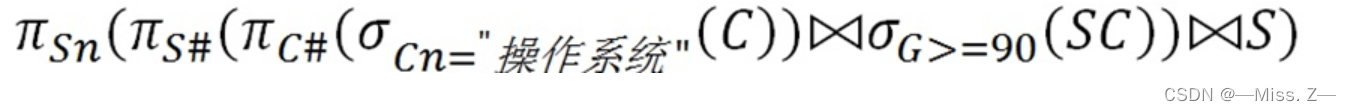
π_Sn(π_S#(π_C#(σ_Cn = "操作系统"(C)) ⨝ σ_G >= 90(SC)))解析:
σ_Cn = "操作系统"(C):在关系C表中筛选出 选修课程名为“操作系统” 的行π_C#(σ_Cn = "操作系统"(C)):在第①步的结果基础上,只保留课程号(C#)列σ_G >= 90(SC):在关系SC表中筛选出 成绩在90分以上(含90分) 的行π_S#(π_C#(σ_Cn = "操作系统"(C)) ⨝ σ_G >= 90(SC)):对第②步和第③步的结果进行连接操作π_Sn(π_S#(π_C#(σ_Cn = "操作系统"(C)) ⨝ σ_G >= 90(SC))):连接完成后,只保留姓名(Sn)列
例6:
学生选课成绩表的关系模式是SC(S#,C#,G),其中S#为学号,C#为课号,G为成绩,学号为20的学生所选课程中成绩及格的全部课号为()
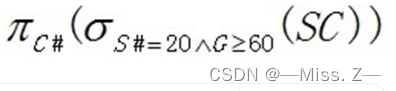
例7:
定义学生选修课程的关系模式如下:SC(S#,Sn,C#,Cn,G,Cr) (其属性分别为学号、姓名、课程号、课程名、成绩、学分)则关系最高是(1NF)
关系模式SC的主键为(S#,C#),但“学号”就可以决定“姓名”,“课程号”就可以决定“课程名”,这里有非主属性对主键的部分依赖,不满足第二范式,关系SC最高是1NF。
例8:
现有表示患者和医疗的关系如下:P(P#,Pn,Pg,By),其中P#为患者编号,Pn为患者姓名,Pg为性别,By为出生日期,Tr(P#,D#,Date,Rt),其中D#为医生编号,Date为就诊日期,Rt为诊断结果检索在1号医生处就诊的男性病人姓名的表达式是()
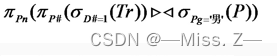
P
| 患者编号P# | 患者姓名Pn | 性别Pg | 出生日期By |
|---|---|---|---|
| 1 | Alice | 女 | 1990-05-15 |
| 2 | Bob | 男 | 1985-11-22 |
| 3 | Charlie | 男 | 1998-03-10 |
Tr
| 患者编号P# | 医生编号D# | 就诊日期Date | 诊断结果Rt |
|---|---|---|---|
| 1 | 1 | 2023-01-10 | Common cold |
| 2 | 1 | 2023-02-05 | Headache |
| 2 | 2 | 2023-02-10 | Sore throat |
| 3 | 1 | 2023-03-20 | Flu |
| 1 | 3 | 2023-04-15 | Allergy |
π_Pn (π_P#(σ_D# = 1(Tr)) ⨝ σ_Pg = '男'(P)))解析:
σ_D# = 1(Tr):在关系Tr表中选取医生编号(D#)为1的行π_P#(σ_D# = 1(Tr):在第①步的结果基础上,只保留患者编号(P#)列σ_Pg = '男'(P):在关系P表中选取性别(Pg)为男的行π_P#(σ_D# = 1(Tr)) ⨝ σ_Pg = '男'(P)):对第②步和第③步的结果进行连接操作π_Pn (π_P#(σ_D# = 1(Tr)) ⨝ σ_Pg = '男'(P))):连接完成后,只保留患者姓名(Pn)列
例9
S(S#,Sn,Sex,Age,D#,Da)(其属性分别为学号、姓名、性别、年龄、所属学院、院长)该关系的范式最高是2NF。

















 1285
1285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









