







make_blobs生成各向同性的高斯斑点
sklearn.datasets.make_blobs(n_samples=100, n_features=2, centers=None, cluster_std=1.0, center_box=(-10.0, 10.0), shuffle=True, random_state=None, return_centers=False)
n_samples:int or array-like(默认100)
生成的样本的总数
n_features:int (默认2)
每个样本的特征数
centers:int or array of shape [n_centers, n_features] (默认None)
中心数即类别数
cluster_std:float or sequence of floats, optional (默认1.0)
聚类的标准偏差
center_box:pair of floats (min, max)(默认(-10.0, 10.0))
边界框
return_centers:bool(默认False)
如果为True,则返回每个群集的中心
样例:
from sklearn.datasets import make_blobs
from matplotlib import pyplot as plt
data, target = make_blobs(n_samples=1000, n_features=5, centers=4)
# plt.scatter()函数用于生成一个二维散点图
plt.scatter(data[:, 0], data[:, 1], c=target) # 参数c为颜色序列,令每个样本颜色不同
plt.show()
结果:

随机森林
RandomForestClassifier随机森林分类器
官方代码
https://scikit-learn.org/dev/modules/generated/sklearn.ensemble.RandomForestClassifier.html#sklearn.ensemble.RandomForestClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=1000, n_features=4,
n_informative=2, n_redundant=0,
random_state=0, shuffle=False)
clf = RandomForestClassifier(max_depth=2, random_state=0)
clf.fit(X, y)
print(X)
print(y)
print(clf.predict([[0, 0, 0, 0]]))
基于鸢尾花数据集的RF分类
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
iris = load_iris()
print(iris)
# 共150条原本记录。三个种类,每种50条
# iris的4个属性是:萼片宽度、萼片长度、花瓣宽度、花瓣长度
# 标签是花的种类:setosa、versicolour、virginica
clf = RandomForestClassifier() # 这里使用了默认的参数设置
clf.fit(iris.data[:150], iris.target[:150]) # 进行模型的训练
# 随机挑选两个预测不相同的样本
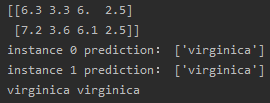
instance = iris.data[[100, 109]]
print(instance)
clf.predict(instance[[0]])
print('instance 0 prediction:', iris.target_names[clf.predict(instance[[0]])])
print('instance 1 prediction:', iris.target_names[clf.predict(instance[[1]])])
print(iris.target_names[iris.target[100]], iris.target_names[iris.target[109]])
结果















 5272
5272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









