







跳表
定义:
跳跃表(英文名:Skip List),于 1990 年 William Pugh 发明,是一个可以在有序元素中实现快速查询的数据结构,其插入,查找,删除操作的平均效率都为 O(logn)。
跳跃表的整体性能可以和二叉查找树(AVL 树,红黑树等)相媲美,其在 Redis 和 LevelDB 中都有广泛的应用。
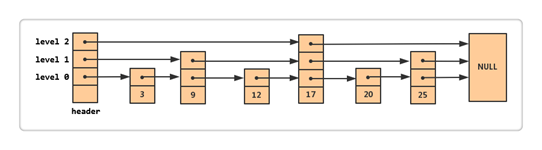
每个结点除了数据域,还有若干个指针指向下一个结点。
整体上看,Skip List 就是带有层级结构的链表(结点都是排好序的),最下面一层(level 0)是所有结点组成的一个链表,依次往上,每一层也都是一个链表。不同的是,它们只包含一部分结点,并且越往上结点越少。仔细观察你会发现,通过增加层数,从当前结点可以直接访问更远的结点(这也就是 Skip List 的精髓所在),就像跳过去一样,所以取名叫 Skip List(跳跃表)。
根据上诉的描述,我们可以写出如下的定义:
struct Node //定义结点
{
int key; //关键值
Node ** forward; //保存了指向若干结点的指针,用二维数组保存。
Node(int key = 0, int level = MAX_LEVEL) //初始化一个新的结点
{
this->key = key;
forward = new Node*[level];
memset(forward, 0, level * sizeof(Node*));
}
};
class SkipList
{
private:
Node * header; //头结点
int level; //层高
private:
int random_level(); //随机值函数
public:
SkipList();
~SkipList();
bool insert(int key); //添加
bool find(int key); //查找
bool erase(int key); //删除
void print(); //打印
};查找:
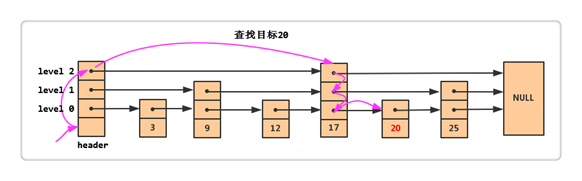
例如上图,我们需要在这个跳表中去查找20.
1.我们从头结点(header)的最上层开始,第一个是17<20,我们就继续往右走,右一个是NULL,
2.我们就从17往下走一步,右一个是25>20,就从17那往下走一步,
3.来到了最后一层,17的右边是20,正好是我们查询的数据,返回。
代码如下:
bool SkipList::find(int key)
{
Node * node = header;
for (int i = level - 1; i >= 0; i--)
{
while (node->forward[i] && node->forward[i]->key <= key)
node = node->forward[i];
if (node->key == key)
return true;
}
return false;
}插入:
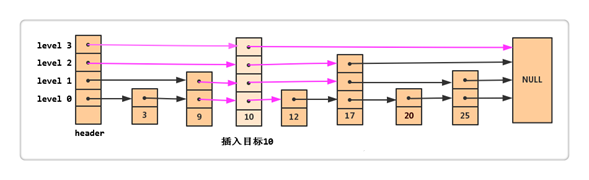
例如上图:我们要插入20.
1.首先我们要查找到每一层在20前面的数据,
2.构造数据为20的这个节点,
3.连接20前后的节点。
补充:
在跳跃表中,有一个理想的跳表,就是说,在底层是数据的全部节点,每往上一层就是 下一层的结点。简而言之就是,如果我们在第0层右12个结点,那么第1层就是6个结点,第2层就是3个结点,以此类推,并且这些结点必须是均匀分布的,这时候整个表的层数就是logn。

但是,我们在平时的操作中,并不能作到如此的均匀,这时候我们每插入一个新的结点的时候,我们要尽量让他接近到理想的状态。因此提出了一个根据概率随机为新结点生成一个层数的方法:
- 给定一个概率 p(p 小于 1),产生一个 [0,1) 之间的随机数;
- 如果这个随机数小于 p,则层数加 1;
- 重复以上动作,直到随机数大于概率 p(或层数大于程序给定的最大层数限制)。
随机数的代码如下: 我们设置的概率是0.5,即 这个结点的的层数是1的概率是1/2,层数为2的概率是1/4,,,依次类推,我们设置了一个最大的层数是32,也可以不要这个层数。
#define P 0.25
#define MAX_LEVEL 32
int SkipList::random_level()
{
int level = 1;
while ((rand() & 0xffff) < (P * 0xffff) && level < MAX_LEVEL)
level++;
return level;
}根据这个我们就可以写出了我们的插入函数如下:
bool SkipList::insert(int key)
{
Node * node = header;
Node * update[MAX_LEVEL];
memset(update, 0, MAX_LEVEL * sizeof(Node*));
//先找到每一层中,待插入key的前驱结点,将其保存中update中。
for (int i = level - 1; i >= 0; i--)
{
while (node->forward[i] && node->forward[i]->key < key)
node = node->forward[i];
update[i] = node;
}
//node就是最底层key的前驱结点
node = node->forward[0];
//判断是否存在key
if (node == nullptr || node->key != key)
{
//得到新结点key的层数
int new_level = random_level();
//如果层数大于目前最大的层数,则将头结点,保存到update中,也就是提升了头结点的层数
if (new_level > level)
{
for (int i = level; i < new_level; i++)
update[i] = header;
level = new_level;
}
//产生一个新的结点key。
Node * new_node = new Node(key, new_level);
//将每一层中,key的前驱结点和key的后继结点连接起来,简单的链表中的结点插入。
for (int i = 0; i < new_level; i++)
{
new_node->forward[i] = update[i]->forward[i];
update[i]->forward[i] = new_node;
}
return true;
}
return false;
}删除:
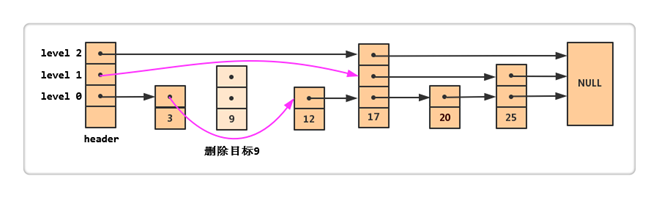
例如上图,我们要删除结点9,
1.查找到每一层9的前驱结点,
2.前驱结点连接到9的后记结点,
3.删除掉9的结点。如果9的结点时最高层,则删除一层。
代码如下:
bool SkipList::erase(int key)
{
Node * node = header;
Node * update[MAX_LEVEL];
fill(update, update + MAX_LEVEL, nullptr);
//查找到目标结点的每一层前驱结点,保存到update中。
for (int i = level - 1; i >= 0; i--)
{
while (node->forward[i] && node->forward[i]->key < key)
node = node->forward[i];
update[i] = node;
}
//node为最下层目标结点
node = node->forward[0];
//如果最底层没有,则表示不存在,有的话,就进行删除
if (node && node->key == key)
{
//将每一层中目标结点的前驱结点和目标结点的后继结点连接起来。
for (int i = 0; i < level; i++)
if (update[i]->forward[i] == node)
update[i]->forward[i] = node->forward[i];
//删除掉目标结点
delete node;
//判断是不是目标结点是不是最高层,删除掉
for (int i = level - 1; i >= 0; i--)
{
if (header->forward[i] == nullptr)
level--;
else
break;
}
return true;
}
return false;
}打印:
直接遍历每一层,打印出全部的结果。
void SkipList::print()
{
Node * node = nullptr;
for (int i = 0; i < level; i++)
{
node = header->forward[i];
cout << "Level " << i << " : ";
while (node)
{
cout << node->key << " ";
node = node->forward[i];
}
cout << endl;
}
cout << endl;
}其他函数:
1.构造函数:
SkipList::SkipList()
{
header = new Node;
level = 0;
}2.析构函数:
SkipList::~SkipList()
{
Node * cur = header;
Node * next = nullptr;
while (cur)
{
next = cur->forward[0];
delete cur;
cur = next;
}
header = nullptr;
}3.测试代码:
int main()
{
SkipList sl;
sl.insert(3);
sl.insert(0);
sl.insert(1); sl.insert(1);
sl.insert(4);
sl.insert(2); sl.insert(2);
sl.insert(5);
sl.insert(6);
sl.print();
cout << sl.find(50) << endl;
cout << sl.find(2) << endl;
cout << sl.find(7) << endl << endl;
sl.erase(1);
sl.print();
sl.erase(4);
sl.print();
return 0;
}结果如下:
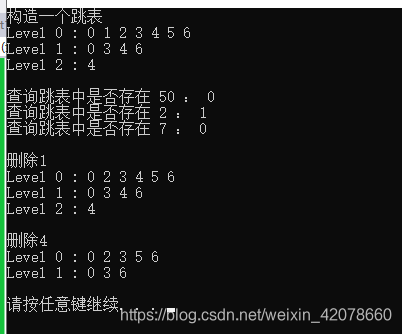
复杂度:
1.时间复杂度: 查找的时间复杂度为O(logn),增加和删除的操作也是查找之后的链表结点的直接操作,因此,跳表的增删查的时间复杂度为O(logn);
2.空间复杂度: 最底层时N,往上依次递减,则结果为 n+n/2+n/4.......+1 因此结果为O(n).














 295
295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









