







redis底层数据结构之跳跃表
redis 的zset有序连表为啥选择用跳跃表?
我们要思考一问题,首先多问问自己为什么,才容易理解它,ps:这是个人观点。首先我们选择的数据结构和算法原因有以下几种:
-
是否能满足redis的当前需求?
redis的zset是一个有序链表,而跳跃表很明显满足这个需求。 -
是否实现起来比较难?
对于其他有序链表的实现,跳跃表的算法相对简单(对于也是有序结构二叉树而然) -
算法的效率可接受?
跳越表的插入,查询,删除效率都是log(n) -
对比一下其他可以替代方案,跳跃表的优点的是啥?
我们看看百度百科的分析,跳表是一个随机化的数据结构,可以被看做二叉树的一个变种,它在性能上和红黑树,AVL树不相上下,但是跳表的原理非常简单。而且跳跃是一种随机平衡操作,不需要像平衡二叉树那样大量的左旋和右旋保持二叉树的平衡计算,这样插入和删除相对二叉树较高。但是相对平衡二叉树而然,如何随机话算法不好,算法时间复杂直接退化为0(n)
redis的实现:
我们下面具体分析一下zset提供的操作,再根据操作反向推理出其大概数据结构和实现原理(个人认为这样相对容易理解)。
zset支持的操作命令分析:
新增命令
zadd key score member [score member…]
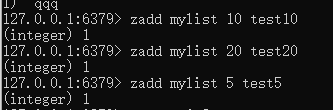
key:链表的名字
score:分数,排序的权重值,redis按照这个值来排序的
member:成员,相当于value
查询命令
zrange key start stop [WITHSCORES]
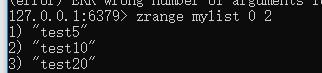
redis的zrange命令可以按照下标查询,可以看到返回的结果按照 score的大小顺序排序。可推理:
-
有属性存放score,redis会使用score排序。
-
有属性存放value(“test5”,“test10”,“test20”)
-
使用范围查询必须要要找到开始位置,这个位置查询需要遍历链表?
我们看看redis的c的结构体,在<server.h>中,如下

如上图是redis的真实源码的结构,在结构体zskiplistNode中,包含属性score。很显然,推理是正确的。我们先不要关心redis的其他属性,后面会分析。
首先我们先简单了解一下什么是跳表。
假如我们有以下排序数字:
3,7,9,20,26,30,41,52,60.
如果是用链表存放的话,我们查找一个数字30,就需要遍历整个链表逐个比较,总共需要6次。但是人是比较聪明,不可能一个遍历。那么我们可以做什么呢?见建立目录,每间隔一个,以自身的值建立目录。如下就是一个理想目录表,一共建立二级目录。这就是调表的由来。

但是建立调表,我们要找,如上图,我们需要把开始节点3记录起来(不然真没法找),所以可以解释以下结构 zskiplist的header就是开始头节点了。

细心的同学会发现,怎么多出个tail(见名思义,是尾节点)。
我们在看看redis提供的操作
zrevrange key start stop [WITHSCORES]
作用:返回有序集 key 中,指定区间内的成员。
其中成员的位置按 score 值递减(从大到小)来排列
这就不难推理了,逆序排序,我们知道调表是从小到大排序,逆序就是需要发过来从尾开始找。















 8251
8251











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









