







本篇内容
- 5个sql题目
- 连续性sql题目思路
5个sql题目
T1、题目描述
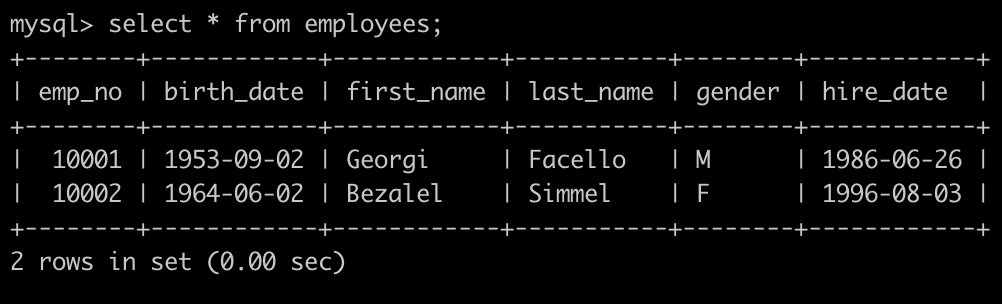
有一个员工表employees简况如下:
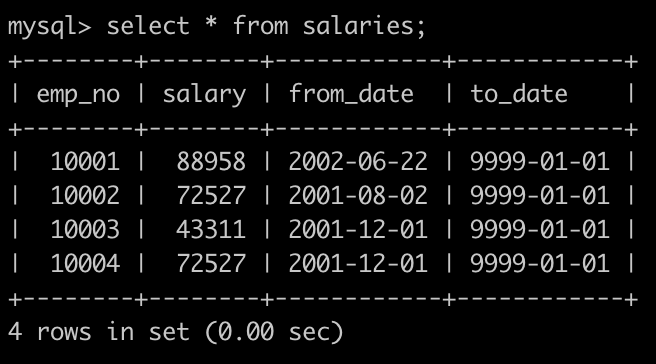
有一个薪水表salaries简况如下:
请你查找薪水排名第二多的员工编号emp_no、薪水salary、last_name以及first_name,不能使用order by完成,以上例子输出为:
由题意:不得使用order by 那么我们可以先求出最大的,把这个最大的薪水的人给排除掉之后,再从里面求出最大的即为薪水排名第二多的
with tmp as
(
select
max(s.salary) as salary
from
employees e join
salaries s on
e.emp_no = s.emp_no
and s.salary <(select max(salary) from salaries where salaries.to_date = '9999-01-01') and s.to_date='9999-01-01')
select
e.emp_no,
s.salary,
e.last_name,
e.first_name
from
employees e join
salaries s on
e.emp_no = s.emp_no
where s.salary = (select salary from tmp)T2、题目描述
有一个部门表departments简况如下:
有一个,部门员工关系表dept_emp简况如下:
有一个职称表titles简况如下:
汇总各个部门当前员工的title类型的分配数目,即结果给出部门编号dept_no、dept_name、其部门下所有的员工的title以及该类型title对应的数目count,结果按照dept_no升序排序
select
d.dept_no,
d.dept_name,
t.title,
count(t.title) as count
from
departments d
join dept_emp dm on
d.dept_no = dm.dept_no
join titles t on
t.emp_no = dm.emp_no
group by d.dept_no,t.title
order by d.dept_no asc题解:对部门分组同时再对title进行分组 求count
T3、题目描述
有一个,部门关系表dept_emp简况如下:
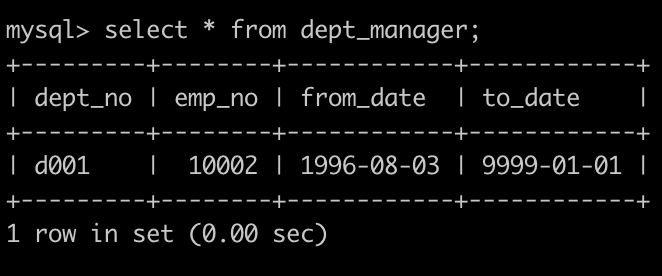
有一个部门经理表dept_manager简况如下:
有一个薪水表salaries简况如下:
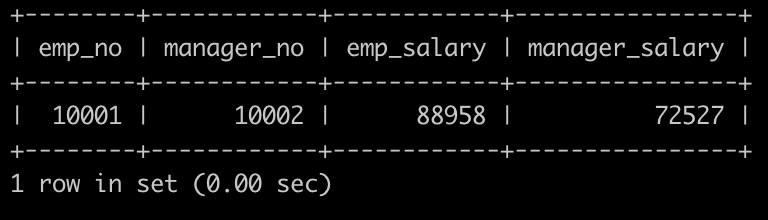
获取员工其当前的薪水比其manager当前薪水还高的相关信息,
第一列给出员工的emp_no,
第二列给出其manager的manager_no,
第三列给出该员工当前的薪水emp_salary,
第四列给该员工对应的manager当前的薪水manager_salary以上例子输出如下:
select
d.emp_no,
dm.emp_no as manager_no,
s1.salary as emp_salary,
s2.salary as manager_salary
from
dept_emp d
join salaries s1 on d.emp_no = s1.emp_no
join dept_manager dm on dm.dept_no=d.dept_no
join salaries s2 on s2.emp_no=dm.emp_no
where s1.salary>s2.salaryT4、题目描述
有一个员工表employees简况如下:
有一个,部门员工关系表dept_emp简况如下:
有一个部门经理表dept_manager简况如下:
T5、题目描述
有一个薪水表salaries简况如下:
获取所有非manager员工薪水情况,给出dept_no、emp_no以及salary,以上例子输出:
select
de.dept_no,
e.emp_no,
s.salary
from
employees e
join dept_emp de on e.emp_no=de.emp_no and de.emp_no not in (
select emp_no from dept_manager
)
join salaries s on s.emp_no=de.emp_no有一个薪水表salaries简况如下:
对所有员工的薪水按照salary进行按照1-N的排名,相同salary并列且按照emp_no升序排列:
题解:该题使用窗口函数贼简单
涉及到编号 ,使用编号函数
row_number 无重复编号 并列数据行号不一致 1 2 3 4 5 6 ...
rank 有重复编号 并列数据 行号一致 但下一行数据编号会跳出 1 2 2 4 5 6 ...
dense_rank 有重复编号 并列数据 行号一致 但下一行数据编号不会跳出 1 2 2 3 4 5 6 ...
如题目要求 即使用dense_rank
select
emp_no,
salary,
dense_rank() over(order by salary desc) as t_rank
from salaries














连续性sql题目思路
- 求连续活跃用户、连续活跃店铺
- 求连续三个月销售额增长的店铺
连续活跃问题
数据
sid,dt
s001,2021-02-21
s002,2021-02-21
s001,2021-02-22
s001,2021-02-23
s003,2021-02-21
s003,2021-02-22
思路:
1)编号函数 row_number() over(partition by sid order by dt asc) num
2) 求差 datediff(dt,num) diff
3)分组 group by sid,diff
4)count(1) as rc
5) 求连续活跃天数大于等于3天的店铺id
rc>=3 并且需要对sid进行去重
连续增长问题
例:求销售额连续增长超过3个月的店铺id
样例数据:
sid,sale_money,mth
s001,8972,2020-02
s001,9000,2020-03
s001,9023,2020-04
s001,7889,2020-05
s001,12000,2020-06
s002,2000,2020-02
s002,1500,2020-03
思路:
1)其实跟上题求连续活跃店铺差不多,但在之前需要过滤出所有增长的记录
2)下压一行 数据 lag(sale_money,1,null) over(partition by sid order by mth) as next_money
3)过滤求出下个月比上个月销售额多的那条记录数据 where next_money>sale_money
4)使用编号函数 row_number(partition by sid order by mth) as rn
5)求差 cast(substr(mth,6) as int) -rn as dif
6)分组 group by sid,dif count (1) cnts having count(1) >=3
注意 这里使用cast转换而不使用month函数是因为 month需要timestamp类型或者date类型的参数 而这里2020-09字符串不能自动转化为date类型 除非是2020-09-21格式的
substr(str,index) 这里的index 是从第几位开始截取,一直到最后 index取值从1 开始
更多学习、面试资料尽在微信公众号:Hadoop大数据开发
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









