







本篇目录:
目的
技术选构
日志生成
目的:
模拟真实业务数据,贴近实战项目
技术选构:
flume+hive
日志生成:
数据库数据准备
-
准备一个mysql服务器(注意,是在你的虚拟机的机器上,不是本地mysql),并创建一个库:realtimedw

2. 将realtimedw.sql这个脚本,导入到你的realtimedw库
3. 将t_md_areas.sql这个脚本,导入到你的realtimedw库
脚本执行完成后,建立了如下表结构
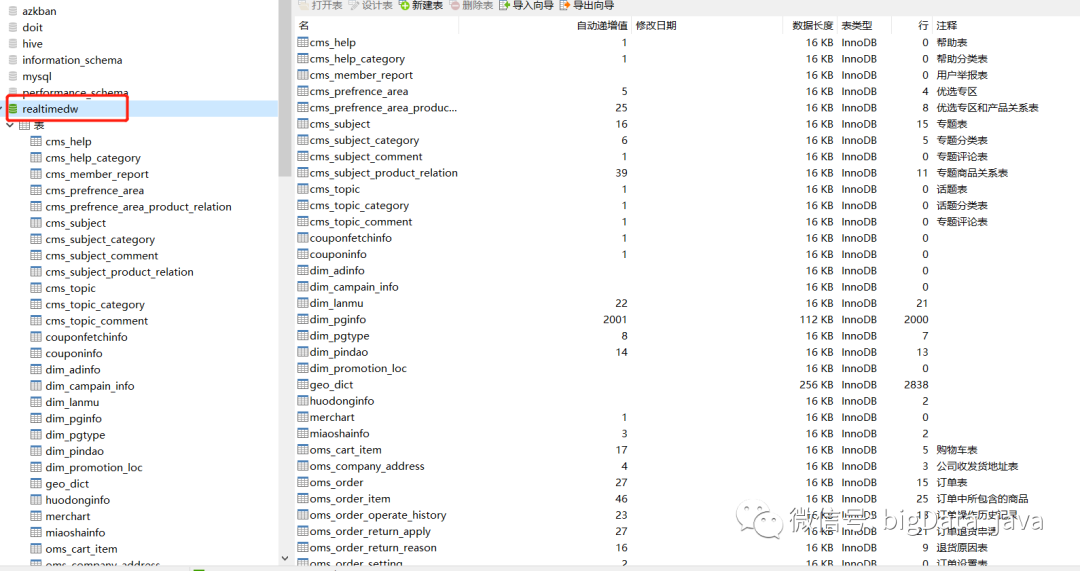
4.其他数据准备
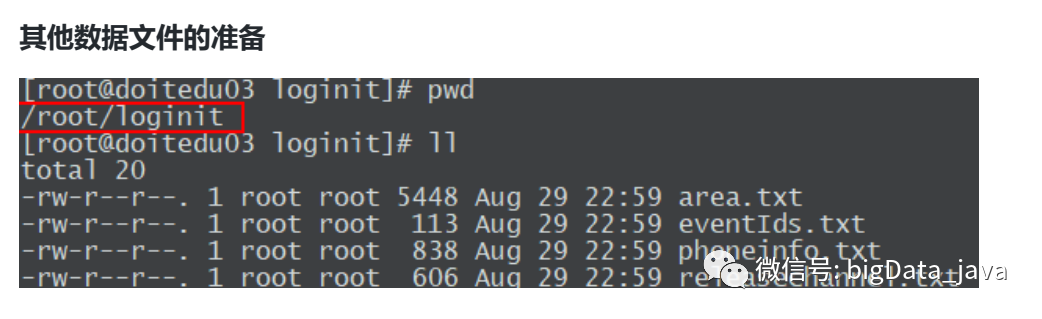
5.修改配置文件(此两个配置文件在jar包【jar包在后面】中,可在本地windows环境下解压出来,修改完再丢回去)
other.properties
将相关位置、及账号密码改为自己对应的
# logger,kafkasink.type=logger#roll console dayrolllogger.type=dayrollinitdata.releasechannel=/root/loginit/releasechannel.txtinitdata.phoneinfo=/root/loginit/phoneinfo.txtinitdata.eventIds=/root/loginit/eventIds.txtinit.user.area=/root/loginit/area.txtdb.url=jdbc:mysql://127.0.0.1:3306/realtimedw?useUnicode=true&characterEncoding=utf8&useSSL=falsedb.user=rootdb.password=ABC123abc.123# max concurrent accessor amountonline.max.num=100
log4j.properties
# log4j.logger.roll = INFO,rollingFile# log4j.additivity.roll=false# log4j.appender.rollingFile=org.apache.log4j.RollingFileAppender# log4j.appender.rollingFile.Threshold=DEBUG# log4j.appender.rollingFile.ImmediateFlush=true# log4j.appender.rollingFile.Append=true# log4j.appender.rollingFile.File=/loggen/logdata/wx/event.log# log4j.appender.rollingFile.MaxFileSize=120MB# log4j.appender.rollingFile.MaxBackupIndex=50# log4j.appender.rollingFile.layout=org.apache.log4j.PatternLayout# log4j.appender.rollingFile.layout.ConversionPattern=%m%nlog4j.logger.dayroll = INFO,DailyRollinglog4j.additivity.dayroll=falselog4j.appender.DailyRolling=org.apache.log4j.DailyRollingFileAppenderlog4j.appender.DailyRolling.File=/loggen/logdata/wx/event_log_log4j.appender.DailyRolling.DatePattern=yyyy‐MM‐dd'.log'log4j.appender.DailyRolling.layout=org.apache.log4j.PatternLayoutlog4j.appender.DailyRolling.layout.ConversionPattern=%m%n
6、启动模拟器,生成数据
-
上传jar包,执行
-
执行命令
app端日志 执行此命令
java -cp log_gen_app.jar cn.doitedu.loggen.entry.GenAppLog![]()
每天执行一次,执行之后,不用管它,大概1小时就ok;
每天执行的,即当天的数据,我生成好了三天的数据,如下图:
![]()
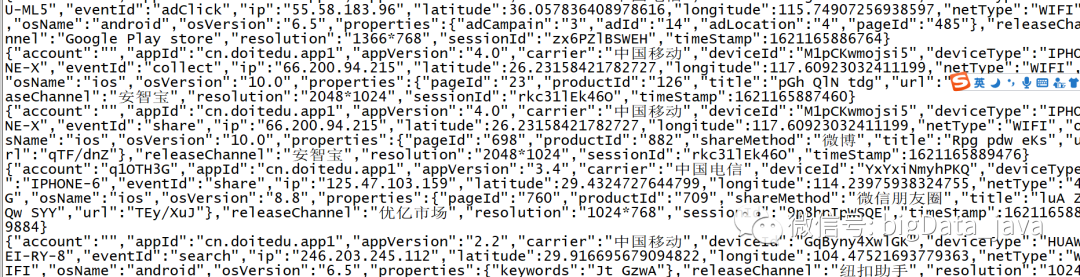
这就是我们日志埋点生成的的用户的行为日志数据,存储格式为json,存储地点在日志服务器。
更多学习、面试资料尽在微信公众号:Hadoop大数据开发
大数据学习/离线项目/实时项目/面试/内推 交流QQ群:139809179















 1102
1102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









