








引言
随机前沿模型的复合扰动项由两部分随机扰动项相减构成,常见的模型设定都会对这两部分随机扰动项的分布作出假设,自然,极大似然估计成为随机前沿分析中最常见的估计方法。
了解极大似然估计的代码实现,对于掌握随机前沿模型非常有用,而且这项技能的外部性非常显著,毕竟它还可以用于其他许多模型的估计。
R语言当中的极大似然估计
R语言中有许多能实现极大似然估计的包,在这里,我推荐使用maxLik,因为其他包我都没有用过。如果老铁们没有用过maxLik包,也没有关系,极大似然估计是很通用的方法,各种实现极大似然估计的包的工作原理应该都是相通的。
下面来看一下maxLik包为我们提供的API:
maxLik(logLik, grad = NULL, hess = NULL, start, method, constraints=NULL, ...)maxLik函数是我们的函数入口,它接受两个必要参数logLik和start(尽管method看上去也是一个必要参数,但其实他有默认值'NR') 。这里的logLik代表我们待估计的对数似然函数,start则是我们需要向maxLik提供的参数初始值。
先来简单解释一下,为什么我们需要提供参数的初始值。因为极大似然估计的背后是一个不断迭代的最优化算法(默认使用的是牛顿法),我们向它提供了一组初始值以后,它每一次迭代都会更新参数值,一直迭代到参数的波动幅度在设定阈值内为止(或达到迭代次数上限)。不提供初始值,就没有迭代的起点了.....
上面是提供初始值的必要性,但是程序可以设计成所有的初始值都为0嘛,为什么非要我们手动提供一组初始值呢?这是因为迭代算法很有可能只能拿到一个局部最优值,一组好的初始值可以在某种程度上规避这个问题,并且离最值比较近的初始值可能只要迭代几次就能给出回归结果,大幅提高估计效率。
是的,我们只要理解了这两个参数的含义,就能实现极大似然估计了,以后做极大似然估计就可以不求人了。我用一个简单的例子来告诉大家具体怎么使用maxLik函数。(具体代码的含义请看代码块中的注释)
library(maxLik)
# 设定随机数生成种子,以便读者能够复现代码结果
set.seed(10086)
# 生成一批实验数据
sample_count <- 1000 # 设定样本容量
x <- rnorm(sample_count) # 生成解释变量
epsilon <- rnorm(sample_count, sd=2) # 生成模型的扰动项
y <- 3 + 2 * x + epsilon # 生成被解释变量
## 显然,我们的总体参数是a=3, b=2, sigma=2(标准正态分布的标准差)
# 设定对数似然函数
logL <- function(params_vector){ # 对数似然函数接受一个参数向量
a <- params_vector[1] # 在参数向量中提取出各个参数的值
b <- params_vector[2]
sigma <- params_vector[3]
# 计算并返回相应的对数似然函数(可以使用外部函数精简式子)
sum(dnorm(y-a-b*x, sd = sigma, log = TRUE))
}
# 设定初始值
# 参数位置需与对数似然函数中的参数向量一一对应
start_params <- c(0, 0, 1)
# 求解极大似然估计值
result <- maxLik(logLik = logL, start = start_params)
# 打印估计值
print(summary(result))相应的代码运行结果如下图所示:
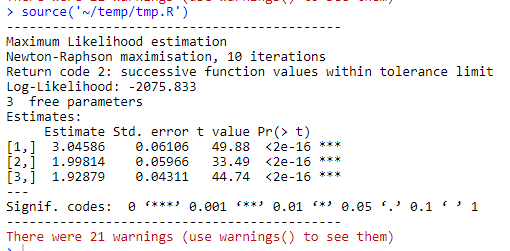
代码估计结果差强人意,估计结果看着和总体参数都比较相近。但是变量没有名字,而且底下报了一些警告。
首先来处理一下变量没有名字这个问题,变量的名字是由初始值参数向量决定的,也就是代码块当中的变量start_params ,这个向量中的各个元素都没有名字,自然最后给出的估计结果就没有名字了。R语言允许给向量元素命名,所以可以将上面的代码修改一下:
logL <- function(params_vector){
# 遍历参数向量,将变量值赋值给变量名
for (index in seq_along(params_vector)){
assign(names(params_vector)[index], params_vector[index])
}
# 照着自己设定的参数名字修改一下内容
sum(dnorm(y-alpha-beta*x, sd = sigma, log = TRUE))
}
# 设定初始值
# 故意打乱了顺序,并不影响脚本的估计结果
start_params <- c(alpha=0, sigma=1, beta=0) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4761
4761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









