







这段时间在维护产品的搜索功能,每次在管理台看到 Elasticsearch 这么高效的查询效率我都很好奇他是如何做到的。

这甚至比在我本地使用 MySQL 通过主键的查询速度还快。
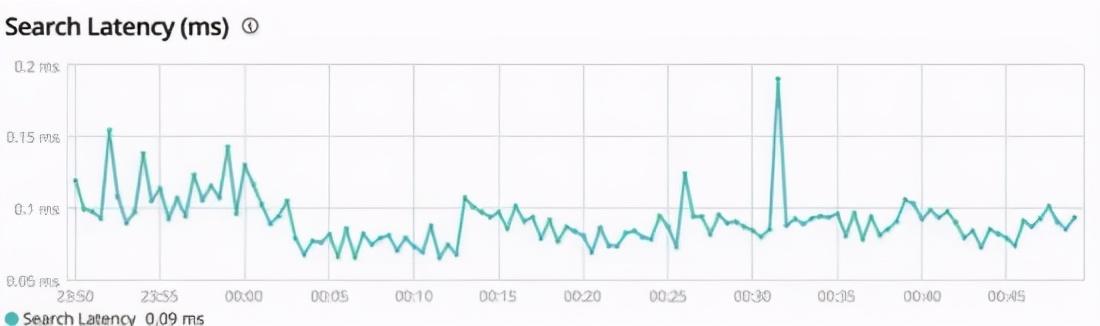

为此我搜索了相关资料:

这类问题网上很多答案,大概意思呢如下:ES 是基于 Lucene 的全文检索引擎,它会对数据进行分词后保存索引,擅长管理大量的索引数据,相对于 MySQL 来说不擅长经常更新数据及关联查询。
说的不是很透彻,没有解析相关的原理;不过既然反复提到了索引,那我们就从索引的角度来对比下两者的差异。
MySQL 索引
先从 MySQL 说起,索引这个词想必大家也是烂熟于心,通常存在于一些查询的场景,是典型的空间换时间的案例。以下内容以 InnoDB 引擎为例。
常见的数据结构
假设由我们自己来设计 MySQL 的索引,大概会有哪些选择呢?
①散列表
首先我们应当想到的是散列表,这是一个非常常见且高效的查询、写入的数据结构,对应到 Java 中就是 HashMap。
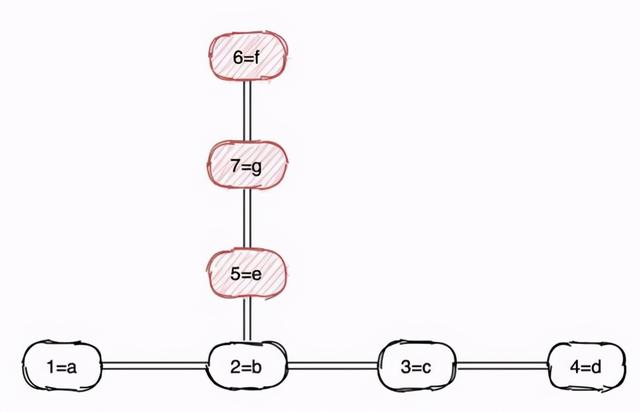
这个数据结构应该不需要过多介绍了,它的写入效率很高 O(1),比如我们要查询 id=3 的数据时,需要将 3 进行哈希运算,然后再这个数组中找到对应的位置即可。
但如果我们想查询 1≤id≤6 这样的区间数据时,散列表就不能很好的满足了,由于它是无序的,所以得将所有数据遍历一遍才能知道哪些数据属于这个区间。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2292
2292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









