







0.文章思想
目前的目标检测算法大多采用了FPN思想并且也使用anchors机制,其实FPN中各个层的anchors主要区别是size的大小,高分辨率特征图的anchors的size小,低分辨率的特征图的anchors的size大。那么目前的目标检测网络是如何将ground-truth (真实目标框)分配到不同层特征图去检测呢?一般的思想就是通过计算ground-truth 和anchors的IoU,筛选出IoU比较大的用于预测ground-truth也就是将对应的anchors设置为正样本 。但是FPN层与层之间的anchors唯一区别是size的不同,长宽比是一样的。那么通过IoU的大小来决定ground-truth 给哪个anchors去预测其中隐含的意思是:anchors的size(不同层的anchors的size是不一样的)与ground-truth 的size非常接近的情况下IoU就会比较大,那么间接的含义是ground-truth 的size决定自己将会被分配到哪个特征层去预测这个目标。(个人理解).。那么这种做法就是启发式的,但是这种做法是否合理呢?
如图1,三个目标的尺寸是60*60,50*50,40*40,。如果按照启发式的思想,60*60和50*50目标会被分配到不同的特征层去预测,而50*50,40*40,目标会分配到同一个特征层去预测。但是这样是否合理呢?FSAF认为是不合理的,所以提出Feature Selective Anchor-Free Module去解决-----在不使用anchors情况下ground-truth到底应该分到哪个特征层去预测比较合适。

图1
1.提出问题
FSAF是在RetinaNet基础上改进的(FSAF还可以集成到其他single-stage模型中,比如SSD、DSSD等)
第一:如何在原有网络的基础上创建一个 anchor-free branches?
第二:如何为 anchor-free branches产生一个监督信号(标签)?
第三:如何动态的选择FPN中哪个特征层去预测某个目标(Instance)?
第四:在训练和测试时,如何将anchors-free brances和anchors-base brances结合?
2.如何在原有网络的基础上创建一个 anchor-free branches?
FSAF模块让每个instance自动的选择FPN中最合适的特征层,在这个模块中,anchors的size不再决定选择哪些特征层进行预测,也就是说anchor (instance) size成为了一个无关的变量,这也就是anchor-free的由来。因此,feature 选择的依据由原来的instance size变成了instance content,实现了模型自动化学习选择FPN中最合适的特征层。
FSAF以RetinaNet为基础结构,添加一个FSAF分支和原来的classification subnet、regression subnet并行,可以不改变原有结构的基础上实现完全的end-to-end training。FSAF同样包含classification(使用的是sigmoid函数)和box regression两个分支,用于预测目标所属的类别和坐标值,如图2所示。

图2
3.如何为 anchor-free branches产生一个监督信号(标签)?
第一:一个目标(Instance),假设它的类别是lable = c,并且边界框坐标是,(x,y)是目标的中心坐标,
(w,h)是目标的宽和高。
第二:此目标在FPN中的第特征层投影的坐标是
,其中
。
第三:定义投影的有效目标框坐标是,也就是图3中的"car"class的白色区域,其中
,式中的
。
第四:定义投影的忽略目标框坐标是,也就是图3中的"car"class的灰色区域,其中
,式中的
。

图3
细看图3
class output:class output是和anchor-base brances并行结构,它的维度是W×H×K,K是总的类别数(应该包含背景类别), class output总共有K个feature maps,在上面我们假设此目标的类别是c(图中的车类别),那么class output 的标签维度是W×H×K的张量,在K个feature maps中的第c个feature map的定义是图3中的“car”class。其中白 色区域就是正的目标区域定义值是1,灰色是忽略区域
也就是不进行梯度反向传播,黑色是负的目标 区域定义值是0. 采用的损失函数是Focal Loss。
box output:box output是和anchor-base brances并行结构,它的维度是W×H×4,4代表偏移量。举例说明偏移量的含义:box output的标签是对于有效区域中像素点
,4个维度的值是
,其中
,
是像素位置
分别相对于
的 top, left, bottom, right,如图4,此外S=4.0。采用的损失函数 是IoU Loss。
在像素点,如果预测的偏移量是
,那么
到
的距离是
,预 测
的左上角和右下角的坐标分别是
和
,则预测的边界框坐标就是将
和
分别乘上
。
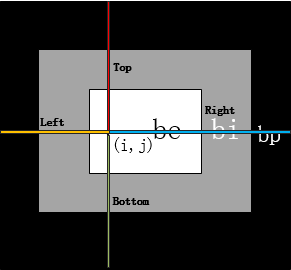
图4
4.如何动态的选择FPN中哪个特征层去预测某个目标(Instance)?
在anchor-based算法中,通常是基于目标的size分配到指定的特征层,而FSAF模块是基于目标的内容选择最优特征层。记目标分配到第
个特征层的分类损失和定位损失分别如下:
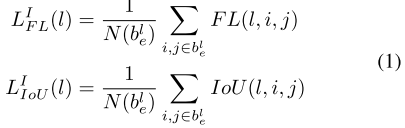
其中是有效区域
像素点的个数。
那么预测目标最优的特征层
是由下式得到,也就是联合损失函数最小。
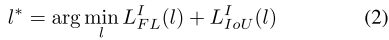
5.在训练和测试时,如何将anchors-free brances和anchors-base brances结合?
在inference中,FSAF可以单独作为一个分支输出预测结果,也可以和原来的anchor-based分支同时输出预测结果。两者都存在时,两个分支的输出结果结合然后使用NMS得到最后预测结果。在training中,采用multi-task loss,即公式如下。
![]()
权重系数为0.5.
实验结果可以看论文。
文章中难免会有理解错误的地方,欢迎交流讨论。
,
















 248
248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











