






1、df
df 查看硬盘空间的使用情况
查看本机硬盘空间的使用情况:
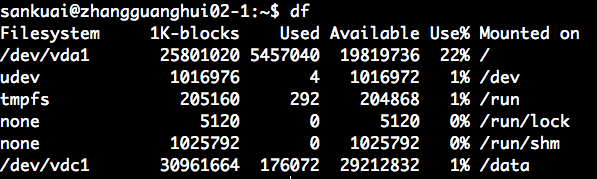
硬盘空间使用情况
2、du
du 查看 目录 和 文件 所占磁盘空间大小
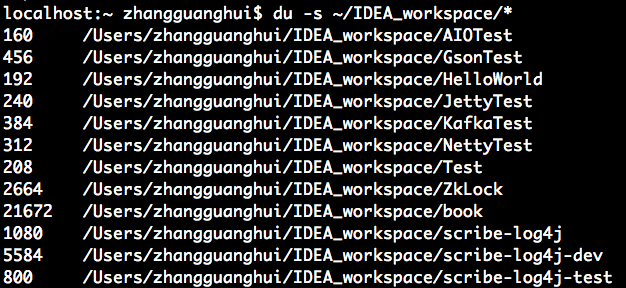
du -s 目录/文件
查看目录 IDEA_workspace 目录下 所有目录和文件 占用空间大小:
IDEA_workspace 目录下各目录占用磁盘空间大小
3、df du
当遇到
“No space left on device”
时,应该如何利用上述两个命令来找到将磁盘空间占满的目录 或 文件。
执行 df 命令,整体查看磁盘空间使用情况,发现 /data 目录使用率已经达到 100%。
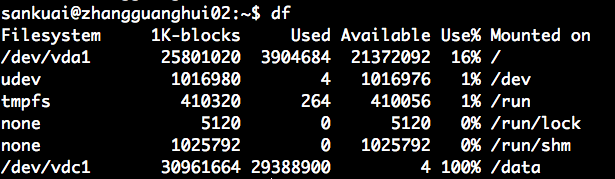
单机磁盘空间使用状态
执行 du 命令,查看 /data 目录下的 目录/文件 占用磁盘空间状态,/data/flume_sink_data 几乎占满整块磁盘。
4、ln
ln 常用来建立软链接
ln -s 源文件 目标文件
当某一工程目录特别深的情况下,可以建立软链接,缩短路径名

建立软链接,缩短目录长度
可以把 软链接 当做一个 变量引用,将其指向一个容易发生变化的量。

通过软链接指向当前日志目录
5、alias
alias 创建命令名别名
alias 别名='命令' 设置别名; unalias 别名 撤销别名
显示已经设置好的别名
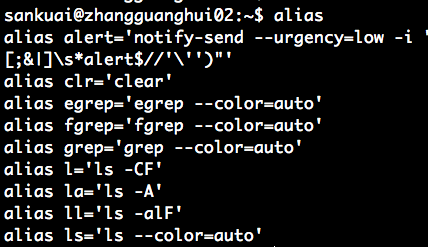
显示已有别名
设置 mkdir 别名为 mk

创建 a/b/c 目录
6、history
history 显示历史执行命令
history n 显示最近 n 条执行命令
显示最近 5 条执行命令
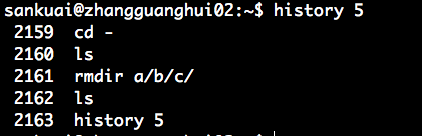
最近 5 条执行命令
7、source
source 让配置文件生效
在 5 中设置别名 mk 之后,在其他 shell 对话框中并不生效,如何使其永久生效。
在 ~/.bashrc 文件中,添加 alias mk="mkdir -p" ,此时并不会生效;source ~/.bashrc 才会生效。
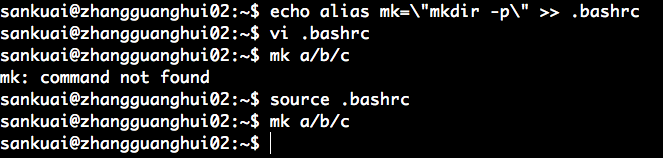
在 .bashrc 中添加 alias
8、通配符
* 代表 0 个到无穷多个任意字符
? 代表 1 个任意字符
[] 代表在中括号内的一个任意字符,例如:[abcd] 代表 a,b,c,d 中任何一个字符
[^] 同上一个刚好相反,不在 中括号 内的任意字符,例如:[^abcd] 代表不是 a,b,c,d 中的任一字符
[-] 代表一个包含在某一范围内的一个任意字符,例如:[0-9] 代表在 0-9 范围内的任一字符
使用通配符来选择符合条件的文件集合:

使用通配符来筛选出符合条件的文件集合
9、特殊字符
# 注释
\ 转义字符,将“特殊字符 和 通配符” 还原成一般字符
| 管道
; 多个命令连续执行分隔符
~ 用户的主文件夹
$ 变量的前导符
>, >> 数据流重定向,> 替换, >> 追加
'' 包含字符串的单引号,不具有变量置换功能
“” 包含字符串的双引号,具有变量置换功能
`` 包含命令,代表可以提前执行的命令,与 $() 相同。
() 为子 shell 的开始与结束
{} 为命令块的组合
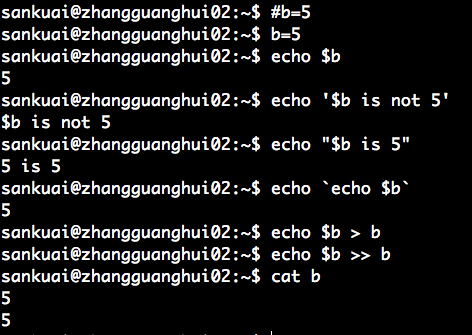
上述特殊字符的使用
10、grep
grep 以行为单位,通过一些过滤条件,将所需要的行信息过滤过来。
grep [-invc] '查找字符串' filename
-i 不区分大小写字符
-n 显示行号
-v 不包含查找字符串
-c 显示符合需求的字符串总行数
从某一个数据文件中取得你想要的数据:
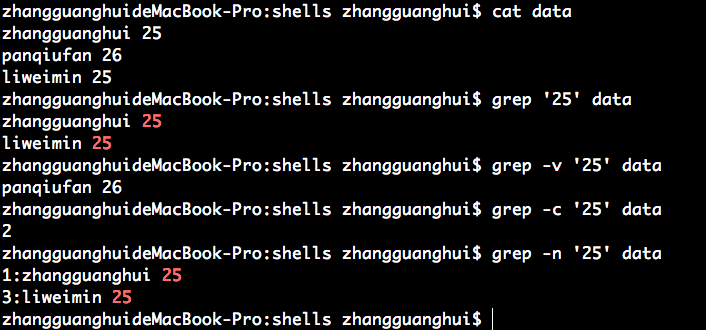
熟悉 grep 的各个参数
16、sort
sort 将数据内容进行排序,默认是按字符串类型进行排序
sort [-nrtku] filename
-n 使用 "纯数字" 进行排序
-r 反向排序
-u uniq,当相同的数据出现时,仅显示一行作为代表
-t 分隔符(默认按 Tab 键进行分隔) -k 指定以哪个分区来进行排序
使用 sort 对文件内的数据进行排序:
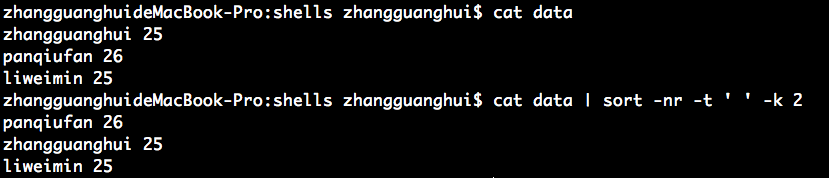
排序
17、uniq
uniq 以"行"为单位,将具有相同内容的相邻行仅保留一行。
uniq [-ic] filename
-i 忽略大小写
-c 对具有相同内容的相邻行进行统计计数
对 data 内的数据进行排序,并进行统计计数:
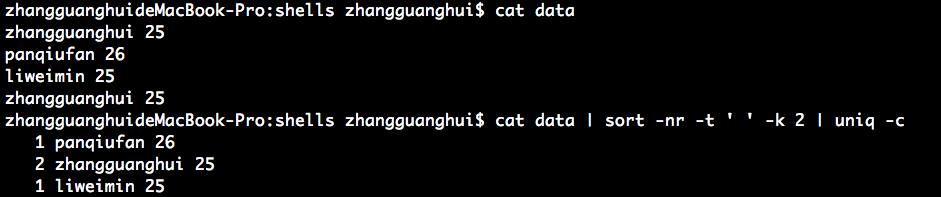
统计 data 内数据进行排序,并统计条数
18、wc
wc 统计一个文件中包含多少字,字符,行。
wc [-cl] filename
-c 计算 file name 中的字符个数
-l 计算 file name 中的行数
统计 data 文件中 zhangguanghui 25 的行数

统计 data 中包含 zhangguanghui 的行数
19、awk
awk '条件类型1{动作1} 条件类型2{动作2}...' filename
awk 以行为单位,将每行数据按照 某个字符(默认空格符) 进行切割,并依次赋值给 $1, $2, $3...$n (n 为切割出来的段数);然后计算条件类型1,如果符合条件的话,就执行动作1;然后计算条件类型2,如果符合条件的话,就执行动作2;....;然后依次按上述步骤处理每一行数据。
其中还有一些特殊字符:$0 代表整行数据;NF 每一行数据被切割成的字段总数;NR 表示 awk 当前处理的哪一行数据; FS 指定分隔符,默认是空格符。
BEGIN{动作1;动作2} 表示在开始执行 awk 命令前执行的一些准备工作。例如:假如我们想指定分隔符的话,则需要在 BEGIN 内提前指定。
END{动作1;动作2} 表示在 awk 处理完每一行数据之后,执行的一些结束工作。
计算 data2 中所有用户的年龄和:

计算 data2 中所有用户的年龄和
20、|
| 表示管道,代表数据通道
cmd1 | cmd2 | cmd3 cmd1 的输出作为 cmd2 的输入;cmd2 的输出作为 cmd3 的输入。
从 data 中取出包含 "zhangguanghui" 字符串的行
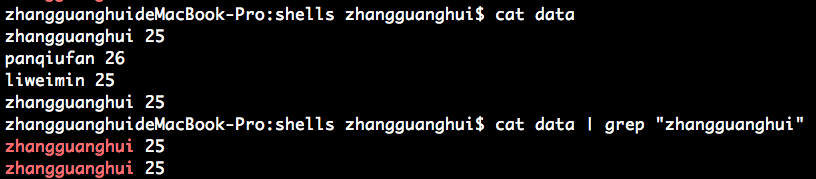
统计 data 中包含 "zhangguanghui" 字符串的行数
21、xargs
xargs 读入 stdin 中的数据,并且以 空格符 或 断行字符 进行分段,将 stdin 的数据分割成 arguments,并将 arguments 赋值给接下来要执行的 命令。
xargs [-pn0] command
-p 在执行每个命令时都要询问用户
-n 后面接数字,表示每次执行 command 命令时,使用几个参数。
-0 如果输入 stdin 的数据中含有特殊字符,例如 `, \, 等,这个参数将其还原成普通字符。
上面介绍的 grep, sort, uniq, awk 等命令都支持管道命令,但是有些命令却不支持管道,例如 chmod。例如:我们想将某目录下的文件修改成可执行的:
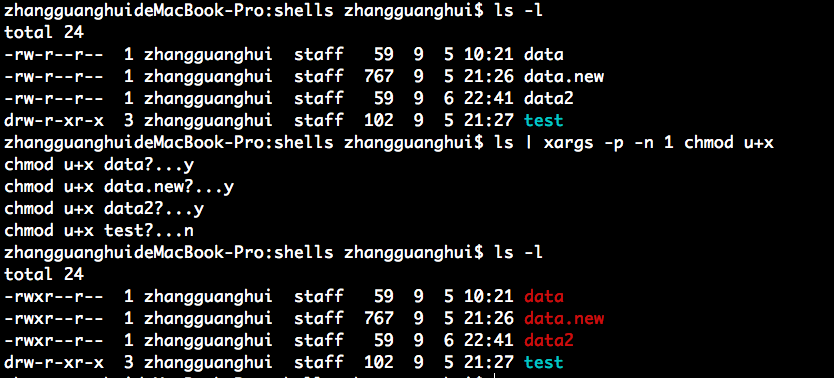
将某目录下的某些文件修改成可执行的
22、find
find [PATH] [option] [command]
option:
(1) 与时间相关,-mtime, -atime, -ctime
(2) 与用户相关,-uid, -gid, -user, -group, -nouser, -nogroup
(3) 与文件权限 和 名称相关的参数,-name, -size, -type, -perm
command
(1) -exec command,举例: -exec ls -l {}\;
其中 {} 代表由 find 找到的内容,\; 代表 -exec 执行的命令结束。
从日志文件中,将 2 天前的日志删除:
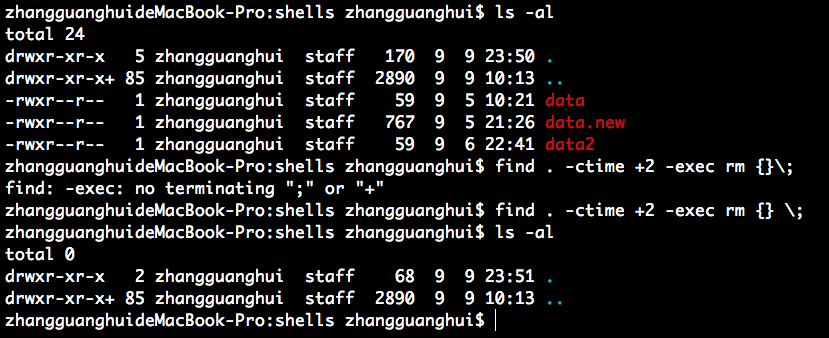















 988
988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









