







操作系统有自己的字符集,下面linux为例:
[oracle@ycnode1 ~]$ locale
这是因为我们在安装 Linux 时选择的是英文安装,所以默认的主语系变量是"en_US.UTF-8"。
LANG=en_US.UTF-8
LC_CTYPE="en_US.UTF-8"
LC_NUMERIC="en_US.UTF-8"
LC_TIME="en_US.UTF-8"
LC_COLLATE="en_US.UTF-8"
LC_MONETARY="en_US.UTF-8"
LC_MESSAGES="en_US.UTF-8"
LC_PAPER="en_US.UTF-8"
LC_NAME="en_US.UTF-8"
LC_ADDRESS="en_US.UTF-8"
LC_TELEPHONE="en_US.UTF-8"
LC_MEASUREMENT="en_US.UTF-8"
LC_IDENTIFICATION="en_US.UTF-8"
LC_ALL=
操作系统上查看支持所有的字符集:
linux:
[oracle@ycnode1 ~]$ locale -a
windows:
C:\Users\Administrator>chcp
活动代码页: 936
ORACLE
字符集
(1)用来存储char,varchar2,clob,long等数据类型
(2)用来标识诸如表名、列名以及PL/SQL等变量
(3)用来存储SQL和PL/SQL程序单元等。
国际字符集
(1)用以存储NCHAR、NVARCHAR2、NCLOB等数据类型。
如果一个表的类型是char,varchar2 clob long类型那么使用数据库字符集
如果表的数据类型是NCHAR、NVARCHAR2、NCLOB那么使用国家字符集
PARAMETER VALUE
---------------------------------------- --------------------------------------------------
NLS_LANGUAGE AMERICAN
NLS_TERRITORY AMERICA
NLS_CURRENCY $
NLS_ISO_CURRENCY AMERICA
NLS_NUMERIC_CHARACTERS .,
NLS_CHARACTERSET AL32UTF8
NLS_CALENDAR GREGORIAN
NLS_DATE_FORMAT DD-MON-RR
NLS_DATE_LANGUAGE AMERICAN
NLS_SORT BINARY
NLS_TIME_FORMAT HH.MI.SSXFF AM
PARAMETER VALUE
---------------------------------------- --------------------------------------------------
NLS_TIMESTAMP_FORMAT DD-MON-RR HH.MI.SSXFF AM
NLS_TIME_TZ_FORMAT HH.MI.SSXFF AM TZR
NLS_TIMESTAMP_TZ_FORMAT DD-MON-RR HH.MI.SSXFF AM TZR
NLS_DUAL_CURRENCY $
NLS_COMP BINARY
NLS_LENGTH_SEMANTICS BYTE
NLS_NCHAR_CONV_EXCP FALSE
NLS_NCHAR_CHARACTERSET AL16UTF16 #国家字符集
NLS_RDBMS_VERSION 11.2.0.4.0
国家字符集使用的比较少,一般使用的都是数据库字符集。国际字符集只是对数据库字符集的补充。
Oracle
的字符集命名遵循以下命名规则:
<
语言
><
比特位数
><
编码
>
比如:
ZHS16GBK
表示采用
GBK
编码格式、
16
位(两个字节)简体中文字符集
US7ASCII
只能存储美国人使用的字符,不超过
128
个
Zhs16cgb231280
中文字符集比较老,并没有存储所有的
ZHS16GBK
最新的中文字符集,超集(
GBK
国标)
Utf8 unicode
字符集,比如外企需求存储各国人的名字,就用
UTF8
繁体字符集,香港大五码,台湾
AL32UTF8
最全的字符集,数据库字符集用它,这个比
Utf8
多的多(跨国企业用这个,效率低)
ZHS16GBK
最新的中文字符集,超集(只存中文就用这个)
AF16UTF16
(国家字符集用它)
数据库支持这么多字符集。
SQL> select * from v$nls_valid_values where value like '%UTF%';
PARAMETER VALUE ISDEP
---------------------------------------- -------------------------------------------------- -----
CHARACTERSET AL24UTFFSS TRUE
CHARACTERSET UTF8 FALSE
CHARACTERSET UTFE FALSE
CHARACTERSET AL32UTF8 FALSE
CHARACTERSET AL16UTF16 FALSE
如果软件有字符集,那么数据库字符集就不用了,sqlplus没有字符集,那么sqlplus使用操作系统字符集。
我们研究客户端操作系统和数据库的字符集。
sqlplus
客户端登陆服务器结构:
所有字符集的转换都在
oracle
端进行的。
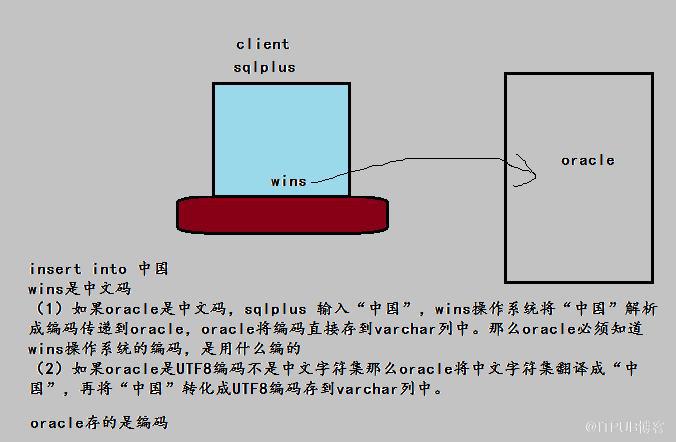
你把客户端设置成16gbk ORACLE就认为客户端是16gbk,客户端真正的字符集不是这个,他的作用只是传话,使得oracle认为客户端就是16gbk
客户端字符集通常中文字符集、utf8
NLS_LANG的设置就是将其设置成客户端操作系统的字符集。
平时用的时候发现没有问题,客户端操作系统将”其“转换成A4,然后A4传到数据库,数据库问客户端你用什么编码编的,客户端说我用UTF8 然后oracle将A4直接存到数据库中。使用的时候不报错。
不论oracle存储还是读取都经过NLS_LANG
[oracle@linux6 ~]$ export NLS_LANG=american_america.utf8
[oracle@VM-0-3-centos ~]$ export NLS_LANG=american_america.utf8
[oracle@VM-0-3-centos ~]$ sqlplus / as sysdba
SQL*Plus: Release 11.2.0.4.0 Production on Thu Mar 25 10:39:05 2021
Copyright (c) 1982, 2013, Oracle. All rights reserved.
Connected to:
Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
SQL> select dump('姚崇',1016) from dual;
DUMP('姚崇',1016)
--------------------------------------------------------------------------------
Typ=96 Len=6 CharacterSet=AL32UTF8: e5,a7,9a,e5,b4,87
sqlplus本身没有字符集,他参考客户端操作系统的字符集。如果软件有字符集,那么软件就不参考数据库的字符集。
所有的字符集转换都是在oracle端发生的。
当我们在sqlplus中输入中文“中国”的时候,被操作系统编码,编码出几个数字,编码从客户端传到oracle,oracle拿到编码,转化成字符集,oracle必须知道这个编码是由什么编的。
结论:如果客户端字符集和数据库字符集一样,那么数据库直接存储传过来的编码;如果客户端是zhs16gbk,数据库是utf-8,那么传过来的是zhs16gbk编码,在数据库端转化成zhs16gbk的字符,然后这些字符再转化成utf-8的编码,存储到表中。(数据库存储时,存储的是编码)
NLS_LANG 这个参数在客户端设的。oracle想要知道操作系统的字符集,这个参数设置成16gbk,那么oracle就认为你的客户端操作系统的字符集就是zhs16gbk。
NLS_LANG的参数设置的和客户端一样。

这是最隐蔽的一个错误。
SQL> select ename,job,dump(ename,1016) from emp;
ENAME JOB DUMP(ENAME,1016)
---------- --------- --------------------------------------------------------------------------------
姚崇 CLERK Typ=1 Len=4 CharacterSet=ZHS16GBK: d2,a6,b3,e7
姚崇 SALESMAN Typ=1 Len=4 CharacterSet=ZHS16GBK: d2,a6,b3,e7
16进制显示。
当存储的时候发生转换时错误的,那么这个是非常危险的!!!
SQL> select dump('姚崇',1016) from dual;
DUMP('姚崇',1016)
-----------------------------------------------
Typ=96 Len=4 CharacterSet=ZHS16GBK: d2,a6,b3,e7
windows:
set
NLS_LANG=AMERICAN_AMERICA.ZHS16GBK
AMERICAN
的意思是oracle反馈信息,比如登录报错的提示信息是用什么语言提示的。
AMERICA 货币符号,日期格式用美国的格式,货币等等。
NLS_DATE_LANGUAGE指定用于拼写日期和月份名称以及由to_date和to_char函数返回的日期缩写(a.m.,p.m.,AD,BC)的语言。默认值来源NLS_LANGUAGE
SQL> show parameter NLS_LANGUAGE
NAME TYPE VALUE
------------------------------------ --------------------------------- ------------------------------
nls_language string AMERICAN
此初始化参数NLS_DATE_LANGUAGE的值用于初始化此参数的会话值,该值是SQL查询处理引用的实际值。如果客户端使用oracle jdbc驱动程序,或者客户端基于OCI并且定义了NLS_LANG client设置(环境变量),则此初始值将被客户端值覆盖。因此,初始化参数值通常被忽略。
SQL> show parameter nls_language
NAME TYPE VALUE
------------------------------------ --------------------------------- ------------------------------
nls_language string AMERICAN
SQL> show parameter nls_date_language
NAME TYPE VALUE
------------------------------------ --------------------------------- ------------------------------
nls_date_language string AMERICAN
SQL> select next_day ( to_date ('2006-10-10','yyyy-mm-dd'),'TUESDAY') NEXT_DAY FROM DUAL;
NEXT_DAY
---------------
17-OCT-06
SQL> select next_day ( to_date ('2006-10-10','yyyy-mm-dd'),'星期二') NEXT_DAY FROM DUAL;
select next_day ( to_date ('2006-10-10','yyyy-mm-dd'),'星期二') NEXT_DAY FROM DUAL
*
ERROR at line 1:
ORA-01846: not a valid day of the week
将nls_date_language 改成中文
SQL> alter session set nls_date_language='simplified chinese';
Session altered.
SQL> select next_day ( to_date ('2006-10-10','yyyy-mm-dd'),'星期二') NEXT_DAY FROM DUAL;
NEXT_DAY
------------
17-10月-06
SQL> select next_day ( to_date ('2006-10-10','yyyy-mm-dd'),'TUESDAY') NEXT_DAY FROM DUAL;
select next_day ( to_date ('2006-10-10','yyyy-mm-dd'),'TUESDAY') NEXT_DAY FROM DUAL
*
ERROR at line 1:
ORA-01846: not a valid day of the week















 1100
1100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









