







走过路过,不要错过。久违的论文阅读笔记,我又来了~~~~
DeepCT全称Deep Contextualized Term Weighting framework,即深度上下文词权重框架,是一种为搜索提供词权重的一种方式。
词的频率是评估查询问题或文档中某个词重要性的常用方法。但是在长问题或者短文档中,它通常分布很平坦,是一个微弱信号。该篇论文提出了将BERT的上下文的文本表示映射到句子和段落的上下文的词语权重,通过学习的方式,赋予不用文本中的相同词语以不同的权重。(思路很正,个人较喜欢,不喜勿喷~~~)
论文全名:Context-Aware Sentence/Passage Term Importance Estimation For First Stage Retrieval
论文地址:paper
论文代码:github
INTRODUCTION(引言)
目前,搜索一般都使用pipeline形式,第一步从海量的文档集合(set)中排序初筛相关文档集合(sub-set),第二部使用一种或多种重排序的方式提高检索精度。
第一阶段排序通常是一个通过反向索引获取信息的布尔型、概率型或向量空间的词袋检索模型。而如何量化每个查询问题或文档中的词语贡献程度是该阶段的核心。大多数检索方法是使用基于频率的信号,例如:文档或者问题的词频表示一个词语上下文中的重要性,逆文档频率表示该词语在文档库全局的重要性。
基于频率的词权重已经取得了巨大的成功,但它是一个粗糙的工具。词的频率不一定表明某个词语是否重要或更加贴近文本的表达,如表1所示。

如果我们搜索‘stomach’这个词语,虽然两篇文档中都出现了,两次‘stomach’。但是很明显可以看出来,‘stomach’在第一篇文档中更能够体现文档内容,而第二篇文档与‘stomach’相关性不大。要确定哪些词语是中心的,需要对该词的意义、整个文本的意义以及该词在文本中所扮演的角色有更深的理解。
由于近期BERT等语言模型的横空出世,使语义理解与语义表达到达了很高的程度;并且已经被证明可以捕捉到一个词的语义和句法特征,不仅如此,它还可以使相同的词在不同的语言语境中具有变化。
因此,该论文提出了深度上下文词语权重框架(DeepCT),通过bert模型表征不同上下文词语提升第一阶段检索模型效果。由于一个词语的表征取决于它的具体语境,因此对同一词语的估计重要性也会随着语境的不同而变化。
DEEP CONTEXTUALIZED DOCUMENT AND QUERY TERM WEIGHTING(深度上下文文档和问题的术语权重)
DeepCT Framework(DeepCT框架)
DeepCT包括两个主要部分:(1)通过BERT生成上下文化的词embedding;(2)通过线性回归预测词汇权重。
上下文词embedding生成。要估计一个词语在特定文本中的重要性,最关键的问题是生成能够描述一个词语与文本上下文之间关系的特征。DeepCT使用当前最火的而且效果最好的BERT模型来提取词语的上下文特征。
映射到目标权重。上下文词embedding是一个包含了词语在特定语境中的句法和语义信息的特征向量。DeepCT将这些特征向量线性地变化成一个词语的重要性得分:
其中,
DeepCT训练了一个针对于每个词语的回归任务。给定文档
在预测过程中,预测的词权重的范围一个为
由于BERT在处理unseen词汇的时候,会将其生成子词(例如:“DeepCT”被标记为“deep”和“##ct”)。该篇论文用第一个子词的权重作为整个词的权重;在计算MSE loss时,其他子词会被mask掉。
Index Passages with DeepCT(DeepCT的文档索引)
构建训练DeepCT的词语真实权重。适当的目标词权重应反映该词语是否对文章起到至关重要的作用。该论文提出query term recall(查询词召回权重,QTR)作为文档真实词语权重重要性的估计:
其中,
训练时的输入为查询问题-文档对(query-passage pair)。在预测阶段,模型的输入只有文档(passage)。
从词语的预测权重到词语索引。由于预测出的词语权重都是0到1之间的值,而索引建立过程需要的词语频率要求时整数。该篇论文定义了一个词频为
其中,
这样在第一段检索的过程中,就可以将
效率。由于第一步建立索引的过程,是在线下,也就是离线状态下进行的,所以不会影响线上搜索的速度。
Query Term Weighting with DeepCT(DeepCT的查询问题的词语权重)
构建训练DeepCT的目标词语权重。DeepCT-Query 模型使用term recall(词语召回权重,TR):
其中,其中,
训练时的输入为查询问题-文档对(query-passage pair)。在预测阶段,模型的输入只有查询问题(query)。
使用预测的词语权重重新赋予查询问题的词语权重。简单地讲,就是通过重复查询问题中的词语来赋予不同的权重。例如,“Liu Cong is an NLP algorithm engineer”,其中词权重分别为[1,1,0,0,3,2,3],那面最终查询的句子变成“Liu Cong NLP NLP NLP algorithm algorithm engineer engineer engineer”。
EXPERIMENTAL METHODOLOGY And RESULTS FOR DeepCT-Index(DeepCT-Index的实验方法及结果)
DeepCT参数:使用预先训练好的BERT参数对DeepCT-Index的BERT部分进行初始化。对于MS MARCO数据集,论文使用官方预训练BERT模型(uncased, base model)。对于TREC-CAR数据集,不能使用官方模型,因为它的测试文档与BERT的官方预训练所使用的文档有重叠。因此,论文使用了Nogueira和Cho的BERT模型,将重叠的文档从预训练的文档集合中去除。在初始化之后,DeepCT模型在训练集上训练3个epoch,使用2e−5的学习率和最大字符长度为128。
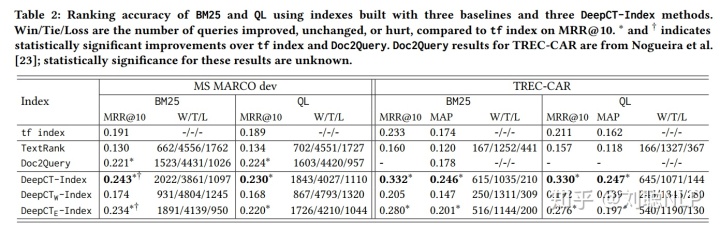
结果如表2所示,DeepCT 构建索引方法均好于原始BM25方法及Doc2query方法。
EXPERIMENTAL METHODOLOGY And RESULTS FOR DeepCT-Query (DeepCT-Query的实验方法与结果)
DeepCT参数:使用官方预先训练好的BERT参数对DeepCT-Query的BERT部分进行初始化。该模型在训练集上训练了10个epoch。使用2e−5的学习率和最大字符长度分别为30、50和100,对应着查询问题标题、描述和叙述。
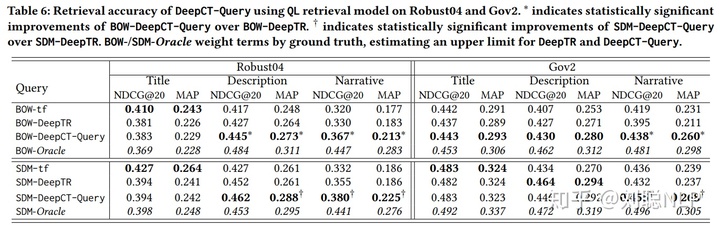
结果如表6所示,短标题查询没有受益于词语加权方法。原因可能是标题查询通常由几个关键字组成,这些关键字都是必不可少的,所以重新权重就不那么重要了。
总结
个人认为,该篇论文的思路很正,给了我一些启发。但是论文描述与代码实现有一些区别,论文中提到训练使用的时query-passage pair,而code中,其实并没有,仅使用了Query或Passage。还有在构建某一query的文档集合或者某一文档的问题集合时,并没有提到查询的数量。有理解的小伙伴,可以留言或私聊我呦,可以一起探讨~~~~
以上就是我对该篇论文的理解,如果有不对的地方,请大家见谅并多多指教。如果喜欢的话,希望可以多多点赞关注。
广告时间,哈哈哈哈。推荐几篇本人之前写的一些文章:
刘聪NLP:短文本相似度算法研究
刘聪NLP:阅读笔记:开放域检索问答(ORQA)
刘聪NLP:NEZHA(哪吒)论文阅读笔记
刘聪NLP:UniLM论文阅读笔记
刘聪NLP:UniLM-v2论文阅读笔记
喜欢的同学,可以关注一下专栏,关注一下作者,还请多多点赞~~~~~~















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









