







第八章 并行模式:卷积 ----- 介绍常数存储器和高速缓存
8-10 章 介绍重要的并行计算模式,是很多并行算法的基础。本章是介绍卷积,以及从存储器的优化思路去优化卷积代码。
1. 卷积:
1.1 卷积并行特点:
a. 每个输出元素的计算都是相互独立的,可并行。
b. 输入元素之间具有相当程度的共享,比如核参数。
挖坑1:幽灵元素,卷积的边界缺失元素;对分块算法的复杂度和效率影响很大。
1.2 初级的卷积核函数(一维卷积):
__global__ void convolution_1D_basic_kernel(float* N, float* M, float* P, int Mask_Width, int Width){
// 参数,输入数组N,掩码数组M,结果数组P,掩码大小,输入数组大小
// 计算输入元素索引,一位卷积,网格设计为一维大小
int i = blockIdx.x * blockDim.x + threadIdx.x;
// 中间加权和变量放在 寄存器 中缓存,而不是全局变量的P中,访问速度快。
float Pvalue = 0;
// 卷积计算开始位置
int N_start_point = i - (Mask_Width / 2);
// 开始计算一次加权和
for(int j = 0; j < Mask_Width; j++){
// 边界判断,核函数内控制流产生分支,性能影响
if(N_start_point + j >= 0 && N_start_point + j < Width){
Pvalue += N[N_start_point + j] * M[j]; // **************
}
}
P[i] = Pvalue;
}问题:1. 由于幽灵元素产生if 控制流的多样性,会影响性能。但是如果大数组,小掩码,影响有限。2. 存储器带宽,可以计算 CGMA值(浮点运算和全局存储器访问的比值) = (加法和乘法两次浮点运算)/(对N 和 M的两次数据访问) = 1,非常低,下文先主要解决这个问题。
2. 常数存储器和高速缓存
观察核参数的特点:a. 尺寸小(比如常用3*3 7*7等);b. 核参数计算时数值不变;c. 所有线程都要访问,而且是以相同的顺序访问。
由上特性,优化方案为,通过将核参数M放入 常数存储器 ,利用高速缓存。先介绍常数存储器和高速缓存的特点。
2.1 常数存储器:
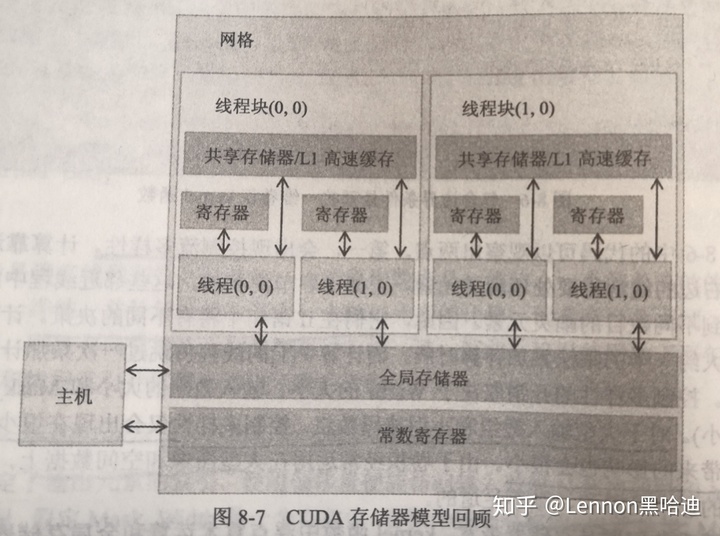
2.1.1 常数存储器特点:
与全局存储器相同都为DRAM (挖坑2);对所有线程块可见;
但在核函数执行期间,值不能被修改;
2.1.2 常数存储器容量查询方法:
cudaDeviceProp prop; // 结构体
if (cuda 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 302
302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









