







本文先是解决循环依赖思路的分析,之后才是Spring源码的解析。文章中很多都是我自己的语言描述,会有不准确或者不严谨的地方,欢迎指正。
什么是循环依赖?

很简单,就是A对象依赖了B对象,B对象依赖了A对象。
比如:
// A依赖了B
class A{
public B b;
}
// B依赖了A
class B{
public A a;
}
那么循环依赖是个问题吗?
如果不考虑Spring,循环依赖并不是问题,因为对象之间相互依赖是很正常的事情。
比如
A a = new A();
B b = new B();
a.b = b;
b.a = a;
这样,A,B就依赖上了。
但是,在Spring中循环依赖就是一个问题了,为什么? 因为,在Spring中,一个对象并不是简单new出来了,而是会经过一系列的Bean的生命周期,就是因为Bean的生命周期所以才会出现循环依赖问题。当然,在Spring中,出现循环依赖的场景很多,有的场景Spring自动帮我们解决了,而有的场景则需要程序员来解决,下文详细来说。
要明白Spring中的循环依赖,得先明白Spring中Bean的生命周期。
Bean的生命周期
这里不会对Bean的生命周期进行详细的描述,只描述一下大概的过程。
Bean的生命周期指的就是:在Spring中,Bean是如何生成的?
被Spring管理的对象叫做Bean。Bean的生成步骤如下:
- Spring扫描class得到BeanDefinition
- 根据得到的BeanDefinition去生成bean
- 首先根据class推断构造方法
- 根据推断出来的构造方法,反射,得到一个对象(暂时叫做原始对象)
- 填充原始对象中的属性(依赖注入)
- 如果原始对象中的某个方法被AOP了,那么则需要根据原始对象生成一个代理对象
- 把最终生成的代理对象放入单例池(源码中叫做singletonObjects)中,下次getBean时就直接从单例池拿即可
可以看到,对于Spring中的Bean的生成过程,步骤还是很多的,并且不仅仅只有上面的7步,还有很多很多,比如Aware回调、初始化等等,这里不详细讨论。
可以发现,在Spring中,构造一个Bean,包括了new这个步骤(第4步构造方法反射)。
得到一个原始对象后,Spring需要给对象中的属性进行依赖注入,那么这个注入过程是怎样的?
比如上文说的A类,A类中存在一个B类的b属性,所以,当A类生成了一个原始对象之后,就会去给b属性去赋值,此时就会根据b属性的类型和属性名去BeanFactory中去获取B类所对应的单例bean。如果此时BeanFactory中存在B对应的Bean,那么直接拿来赋值给b属性;如果此时BeanFactory中不存在B对应的Bean,则需要生成一个B对应的Bean,然后赋值给b属性。
问题就出现在第二种情况,如果此时B类在BeanFactory中还没有生成对应的Bean,那么就需要去生成,就会经过B的Bean的生命周期。
那么在创建B类的Bean的过程中,如果B类中存在一个A类的a属性,那么在创建B的Bean的过程中就需要A类对应的Bean,但是,触发B类Bean的创建的条件是A类Bean在创建过程中的依赖注入,所以这里就出现了循环依赖:
ABean创建-->依赖了B属性-->触发BBean创建--->B依赖了A属性--->需要ABean(但ABean还在创建过程中)
从而导致ABean创建不出来,BBean也创建不出来。
这是循环依赖的场景,但是上文说了,在Spring中,通过某些机制帮开发者解决了部分循环依赖的问题,这个机制就是三级缓存。
三级缓存
三级缓存是通用的叫法。 一级缓存为:singletonObjects 二级缓存为:earlySingletonObjects 三级缓存为**:singletonFactories**
先稍微解释一下这三个缓存的作用,后面详细分析:
- singletonObjects中缓存的是已经经历了完整生命周期的bean对象。
- earlySingletonObjects比singletonObjects多了一个early,表示缓存的是早期的bean对象。早期是什么意思?表示Bean的生命周期还没走完就把这个Bean放入了earlySingletonObjects。
- singletonFactories中缓存的是ObjectFactory,表示对象工厂,表示用来创建早期bean对象的工厂。
解决循环依赖思路分析
先来分析为什么缓存能解决循环依赖。
上文分析得到,之所以产生循环依赖的问题,主要是:
A创建时--->需要B---->B去创建--->需要A,从而产生了循环
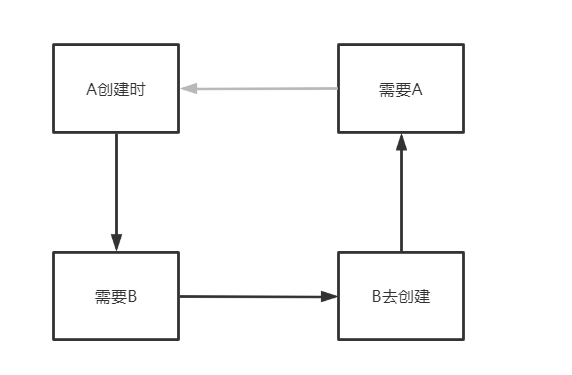
那么如何打破这个循环,加个中间人(缓存)

A的Bean在创建过程中,在进行依赖注入之前,先把A的原始Bean放入缓存(提早暴露,只要放到缓存了,其他Bean需要时就可以从缓存中拿了),放入缓存后,再进行依赖注入,此时A的Bean依赖了B的Bean,如果B的Bean不存在,则需要创建B的Bean,而创建B的Bean的过程和A一样,也是先创建一个B的原始对象,然后把B的原始对象提早暴露出来放入缓存中,然后在对B的原始对象进行依赖注入A,此时能从缓存中拿到A的原始对象(虽然是A的原始对象,还不是最终的Bean),B的原始对象依赖注入完了之后,B的生命周期结束,那么A的生命周期也能结束。
因为整个过程中,都只有一个A原始对象,所以对于B而言,就算在属性注入时,注入的是A原始对象,也没有关系,因为A原始对象在后续的生命周期中在堆中没有发生变化。
从上面这个分析过程中可以得出,只需要一个缓存就能解决循环依赖了,那么为什么Spring中还需要singletonFactories三级缓存呢?
这是难点,基于上面的场景想一个问题:如果A的原始对象注入给B的属性之后,A的原始对象进行了AOP产生了一个代理对象,此时就会出现,对于A而言,它的Bean对象其实应该是AOP之后的代理对象,而B的a属性对应的并不是AOP之后的代理对象,这就产生了冲突。
B依赖的A和最终的A不是同一个对象。
AOP就是通过一个BeanPostProcessor来实现的,这个BeanPostProcessor就是AnnotationAwareAspectJAutoProxyCreator,它的父类是AbstractAutoProxyCreator,而在Spring中AOP利用的要么是JDK动态代理,要么CGLib的动态代理,所以如果给一个类中的某个方法设置了切面,那么这个类最终就需要生成一个代理对象。
一般过程就是:A类--->生成一个普通对象-->属性注入-->基于切面生成一个代理对象-->把代理对象放入singletonObjects单例池中。
那出现AOP的循环依赖,要怎么办呢?我们这样想一下,A实例化完成之后得到了AService原始对象,放入缓存map中,那我们在实例化后,放入缓存map之前,提前进行AOP得到一个AService的代理对象,然后把这个代理对象放入缓存,这样在创建BService时注入就是AService的代理对象了

这么一看好像还是不需要三级缓存,二级缓存也能满足,但是这样违背了Spring设计的原则,Spring在设计之初就是通过AnnotationAwareAspectJAutoProxyCreator这个后置处理器来在Bean生命周期的最后一步(初始化后)来完成AOP代理,而不是在实例化后就立马进行AOP代理。
要考虑到AOP,只能提前AOP,这样BService注入的才是AService的代理对象,那怎么办呢,那就特殊处理嘛:只有AService(当前创建的Bean)出现了循环依赖的情况下,才需要提前进行AOP
在AService实例化后进行判断,AService是否出现了循环依赖,如果出现循环依赖,就提前进行AOP

那问题来了,AService实例化后,还没有进行属性注入,如何判断AService是否出现循环依赖,难道要把AService所有注入的属性都循环一遍去看这些属性有没有依赖AService?而且还会出现
A-->B--C--D--A这种情况,在AService实例化后去判断AService有没有循环依赖很麻烦。
循环依赖什么时候会出现,创建A的时候需要创建B,创建B-->属性注入的时候需要注入A,而此时A还在创建中,那我们是不是可以在创建B-->属性注入的时候,判断B需要注入的A是不是还在创建中,如果是,那就说明A出现了循环依赖

首先我们再创建Bean开始之前把当前正在创建bean的beanname存到set中(singletonsCurrentlyInCreation),之后我们在BService填充AService的时候,先去单例池中找,没找到,再判断AService是否出现循环依赖(singletonsCurrentlyInCreation中是否包含A),
A出现了循环依赖,接着判断A是否需要AOP,需要就提前AOP,将AOP代理对象注入,不需要就注入A的原始对象。
这样解决了循环依赖+AOP但是还是会有问题,我们看一下这种情况:
A依赖B,B依赖A同时A依赖C,C依赖A,并且A需要AOP
根据上面流程图,首先A填充B属性的时候生成了一个A的代理对象,在A填充C的时候又生成了一个A的代理对象,但是A是单例的,怎么办呢,把生成的代理对象或者原始对象存到缓存中:
earlySingletonObjects,也就是我们说的二级缓存

分析到现在好像还是只需要一个缓存就可以了,我们看一下出现循环依赖之后判断AService是否AOP以及提前AOP这块逻辑

判断AService是否AOP以及提前AOP,或者是不需要AOP我们都需要AService的原始对象,那我们在创建BService的时候怎么拿到AService原始对象呢,难道要从AService注入BService的时候就把AService原始对象作为入参一步一步传过来嘛?不太现实,怎么办呢,那就再加一个缓存,实例化得到原始对象后存到缓存singletonFactories中,这也就是三级缓存了
我们再分析,不管AService是否进行AOP,我们需要的都是一个对象,要么是AService代理对象,要么是AService原始对象,那我们是不是可以把这块逻辑放到一个对象工厂中(ObjectFactory),我不关心具体逻辑,你只要返回给我一个可以注入的AService的对象就可以了,这样我们可以在实例化得到AService原始对象之后缓存一个ObjectFactory,重写getObject方法,getObject方法中就是判断AOP及提前AOP,这样我们在BService注入A的是否判断出A是循环依赖之后回调ObjectFactory.getObject方法得到一个A的对象放入二级缓存再注入就好了。

如果AService提前进行了AOP,那我们再AService初始化后还要再进行一次AOP吗?肯定是不会的,所以我们再提前进行AOP的时候把提前AOP的bean缓存起来,到初始化后的时候进行AOP的时候会去判断当前beanName是否在earlyProxyReferences,如果在则表示已经提前进行过AOP了,无需再次进行AOP。
总结
至此,总结一下三级缓存:
- singletonObjects:缓存经过了完整生命周期的bean
- earlySingletonObjects:缓存未经过完整生命周期的bean,如果某个bean出现了循环依赖,就会提前把这个暂时未经过完整生命周期的bean放入earlySingletonObjects中,这个bean如果要经过AOP,那么就会把代理对象放入earlySingletonObjects中,否则就是把原始对象放入earlySingletonObjects,但是不管怎么样,就是是代理对象,代理对象所代理的原始对象也是没有经过完整生命周期的,所以放入earlySingletonObjects我们就可以统一认为是未经过完整生命周期的bean。
- singletonFactories:缓存的是一个ObjectFactory,也就是一个Lambda表达式。在每个Bean的生成过程中,经过实例化得到一个原始对象后,都会提前基于原始对象暴露一个Lambda表达式,并保存到三级缓存中,这个Lambda表达式可能用到,也可能用不到,如果当前Bean没有出现循环依赖,那么这个Lambda表达式没用,当前bean按照自己的生命周期正常执行,执行完后直接把当前bean放入singletonObjects中,如果当前bean在依赖注入时发现出现了循环依赖(当前正在创建的bean被其他bean依赖了),则从三级缓存中拿到Lambda表达式,并执行Lambda表达式得到一个对象,并把得到的对象放入二级缓存((如果当前Bean需要AOP,那么执行lambda表达式,得到就是对应的代理对象,如果无需AOP,则直接得到一个原始对象))。
- 其实还要一个缓存,就是earlyProxyReferences,它用来记录某个原始对象是否进行过AOP了。
反向分析一下singletonFactories
为什么需要singletonFactories?假设没有singletonFactories,只有earlySingletonObjects,earlySingletonObjects是二级缓存,它内部存储的是为经过完整生命周期的bean对象,Spring原有的流程是出现了循环依赖的情况下:
- 先从singletonFactories中拿到lambda表达式,这里肯定是能拿到的,因为每个bean实例化之后,依赖注入之前,就会生成一个lambda表示放入singletonFactories中
- 执行lambda表达式,得到结果,将结果放入earlySingletonObjects中
那如果没有singletonFactories,该如何把原始对象或AOP之后的代理对象放入earlySingletonObjects中呢?何时放入呢?
首先,将原始对象或AOP之后的代理对象放入earlySingletonObjects中的有两种:
- 实例化之后,依赖注入之前:如果是这样,那么对于每个bean而言,都是在依赖注入之前会去进行AOP,这是不符合bean生命周期步骤的设计的。
- 真正发现某个bean出现了循环依赖时:按现在Spring源码的流程来说,就是getSingleton(String beanName, boolean allowEarlyReference)中,是在这个方法中判断出来了当前获取的这个bean在创建中,就表示获取的这个bean出现了循环依赖,那在这个方法中该如何拿到原始对象呢?更加重要的是,该如何拿到AOP之后的代理对象呢?难道在这个方法中去循环调用BeanPostProcessor的初始化后的方法吗?不是做不到,不太合适,代码太丑。**最关键的是在这个方法中该如何拿到原始对象呢?**还是得需要一个Map,预习把这个Bean实例化后的对象存在这个Map中,那这样的话还不如直接用第一种方案,但是第一种又直接打破了Bean生命周期的设计。
所以,我们可以发现,现在Spring所用的singletonFactories,为了调和不同的情况,在singletonFactories中存的是lambda表达式,这样的话,只有在出现了循环依赖的情况,才会执行lambda表达式,才会进行AOP,也就说只有在出现了循环依赖的情况下才会打破Bean生命周期的设计,如果一个Bean没有出现循环依赖,那么它还是遵守了Bean的生命周期的设计的。
源码解析
基于上面的思路,我们开始解读整个循环依赖源码处理的过程,整个流程应该是以A的创建为起点

创建A的过程实际上就是调用getBean方法,首先回去单例池中找,找不到才会去创建。
调用getSingleton(beanName)
首先调用getSingleton(AService)方法,这个方法又会调用getSingleton(beanName, true)
org.springframework.beans.factory.support.AbstractBeanFactory#doGetBean

org.springframework.beans.factory.support.DefaultSingletonBeanRegistry#getSingleton
@Override
@Nullable
public Object getSingleton(String beanName) {
return getSingleton(beanName, true);
}getSingleton(beanName, true)这个方法实际上就是到缓存中尝试去获取Bean,整个缓存分为三级
singletonObjects,一级缓存,存储的是所有创建好了的单例Bean
earlySingletonObjects,完成实例化,但是还未进行属性注入及初始化的对象(原始对象或者代理对象)
singletonFactories,提前暴露的一个单例工厂,二级缓存中存储的就是从这个工厂中获取到的对象
因为A是第一次被创建,所以不管哪个缓存中必然都是没有的,(其实这里之后从单例池中找,不会到二级三级缓存找,因为这个时候没有出现循环依赖,正在创建bean的set中没有AService)因此会进入getSingleton的另外一个重载方法getSingleton(beanName, singletonFactory)。
调用getSingleton(beanName, singletonFactory)
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(beanName, "Bean name must not be null");
synchronized (this.singletonObjects) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
// ....
// 省略异常处理及日志
// ....
// 在单例对象创建前先做一个标记
// 将beanName放入到singletonsCurrentlyInCreation这个集合中
// 标志着这个单例Bean正在创建
// 如果同一个单例Bean多次被创建,这里会抛出异常
beforeSingletonCreation(beanName);
boolean newSingleton = false;
boolean recordSuppressedExceptions = (this.suppressedExceptions == null);
if (recordSuppressedExceptions) {
this.suppressedExceptions = new LinkedHashSet<>();
}
try {
// 回调lambda表达式中的代码,调用createBean方法创建一个Bean后返回
singletonObject = singletonFactory.getObject();
newSingleton = true;
}
// ....
// 省略异常处理
// ....
finally {
if (recordSuppressedExceptions) {
this.suppressedExceptions = null;
}
// 创建完成后将对应的beanName从singletonsCurrentlyInCreation移除
afterSingletonCreation(beanName);
}
if (newSingleton) {
// 添加到一级缓存单例池singletonObjects中
addSingleton(beanName, singletonObject);
}
}
return singletonObject;
}
}这个方法代码有点长,我截取了主要循环依赖相关的,我们看几个主要的方法:
beforeSingletonCreation(beanName):在开始创建单例bean之前,将beanName缓存到singletonsCurrentlyInCreation这个集合中,表示该bean正在创建,之后判断是否出现循环依赖就是用这个集合来判断的
singletonObject = singletonFactory.getObject():执行lambda表达式中的代码,执行createBean方法创建一个Bean后返回
afterSingletonCreation(beanName):创建完成后将对应的beanName从singletonsCurrentlyInCreation集合中移除
addSingleton(beanName, singletonObject):将创建完成的单例bean缓存到单例池中
通过createBean方法返回的Bean最终被放到了一级缓存,也就是单例池中。
那么到这里我们可以得出一个结论:一级缓存中存储的是已经完全创建好了的单例Bean
调用addSingletonFactory方法
接下来看createBean方法,createBean方法中会加载beanClass,实例化前,再调用doCreateBean方法,返回创建完成的bean
在doCeateBean方法中,执行完实例化,beanDefinition后置处理,会执行addSingletonFactory方法,添加三级缓存
org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#doCreateBean
// 为了解决循环依赖提前缓存单例创建工厂
// Eagerly cache singletons to be able to resolve circular references
// even when triggered by lifecycle interfaces like BeanFactoryAware.
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
// 循环依赖-添加到三级缓存
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}当前创建的bean是单例的,并且this.allowCircularReferences=true(也就是当前容器支持循环依赖,默认为true,可以自己设置不支持),并且当前bean正在创建中(singletonsCurrentlyInCreation集合中又当前bean),就会添加到三级缓存
前面以及完成了AService的实例化,得到了AService的原始对象

在属性注入之前,将beanName,beanDefinition,bean(实例化得到的原始对象)封装成一个ObjectFactory工厂放到三级缓存中
// 这里传入的参数也是一个lambda表达式,() -> getEarlyBeanReference(beanName, mbd, bean)
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
// 添加到三级缓存中
this.singletonFactories.put(beanName, singletonFactory);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}注意这里只是缓存了ObjectFactory,并不会执行lambda表达式,也就是不会执行getEarlyBeanReference方法,只有在调用singletonFactory.getObject才会去执行

当AService完成了实例化并添加进了三级缓存后,就要开始为AService进行属性注入了,在注入时发现AService依赖了BService,那么这个时候Spring又会去getBean(BService)

因为BService需要注入AService,所以在创建BService的时候,又会去调用getBean(AService),这个时候就又回到之前的流程了,但是不同的是,之前从缓存中没有取到,这次是可以取到的。
getSingleton(AService, true):

首先从单例池取AService,没有取到,并且AService在singletonsCurrentlyInCreation(正在创建)集合中(出现循环依赖),接着到二级缓存中获取,这个时候二级缓存中也是没有的,最后到三级缓存中获取到了工厂singletonFactory,执行getObject方法也就是 上文说到的lambda表达式中的getEarlyBeanReference方法
从这里我们可以看出,注入到BService中的AService是通过getEarlyBeanReference方法提前暴露出去的一个对象,还不是一个完整的Bean,(还没有进行属性赋值,初始化)那么getEarlyBeanReference到底干了啥了,我们看下它的源码
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
它实际上就是调用了后置处理器的getEarlyBeanReference,而真正实现了这个方法的后置处理器只有一个,就是通过@EnableAspectJAutoProxy注解导入的AnnotationAwareAspectJAutoProxyCreator。该方法在他的父类org.springframework.aop.framework.autoproxy.AbstractAutoProxyCreator中:
@Override
public Object getEarlyBeanReference(Object bean, String beanName) {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
//将提前AOP的bean缓存到earlyProxyReferences中
this.earlyProxyReferences.put(cacheKey, bean);
// 如果需要代理,返回一个代理对象,不需要代理,直接返回当前传入的这个bean对象
return wrapIfNecessary(bean, beanName, cacheKey);
}如果AService需要AOP那么返回的就是AService代理对象,否则就是实例化得到的原始对象,不管是哪中情况,得到的对象都是不完整的。
这样我们通过三级缓存中的singletonFactory得到了一个AService对象,并且缓存到二级缓存中,返回给BService完成注入,这样BService就顺利创建完成返回给AService完成注入。
假如AService在填充完BService之后,又要填充一个CService并且CService也依赖了AService,那么在CService注入AService时就可以到二级缓存中取提前暴露的AService对象了,这样可以保证AService代理对象也会时单例的。
注意前提:Spring在创建Bean时默认会根据自然排序进行创建,所以A会先于B进行创建
看完这个过程有几个问题:
1.我们注入到BService中的是提前AOP得到的AService代理对象,而初始化的时候是对AService对象本身进行初始化,这样不会有问题吗?
答:不会,这是因为不管是cglib代理还是jdk动态代理生成的代理类,内部都持有一个目标类的引用,当调用代理对象的方法时,实际会去调用目标对象的方法,A完成初始化相当于代理对象自身也完成了初始化
2.AService相当于是在属性注入的时候提前进行了AOP生成了代理对象,当AService初始化完成,在初始化后的时候执行AnnotationAwareAspectJAutoProxyCreator这个后置处理器的postProcessAfterInitialization(初始化后)方法中会对AService再一次进行AOP代理吗?
上面getEarlyBeanReference方法中,把当前bean,缓存到了this.earlyProxyReferences中
当执行AnnotationAwareAspectJAutoProxyCreator.postProcessAfterInitialization会进行判断,如果已经完成了AOP,就不再处理,直接返回原始对象。

3.属性注入,初始化都是实例化得到的原始对象,而且AService因为出现了循环依赖所以提前进行了AOP,而上面说到在初始化后处理AOP时,因为已经提进行了AOP所以这里不会再处理,会直接返回AService原始对象,那么Spring是在哪里将代理对象放入到容器中的呢?


在完成初始化后,Spring又调用了一次getSingleton方法,这一次传入的参数又不一样了,false可以理解为禁用三级缓存,前面图中已经提到过了,在为B中注入A时已经将三级缓存中的工厂取出,并从工厂中获取到了一个对象放入到了二级缓存中,所以这里的这个getSingleton方法做的时间就是从二级缓存中获取到这个代理后的A对象。
如果AService没有出现循环依赖,那么也就不会进行提前AOP,二级缓存中是不会有AService代理对象的,而且初始化后得到的也就是AService的代理对象,所以是不会走这块代码的。
exposedObject == bean可以认为是必定成立的,除非你非要在初始化后阶段的后置处理器中替换掉正常流程中的Bean,例如增加一个后置处理器:
@Component
public class MyPostProcessor implements BeanPostProcessor {
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
if (beanName.equals("a")) {
return new A();
}
return bean;
}
}
@Asyn情况下的依赖注入
//配置类中要开启事务:@EnableAsync
@Component
public class AService {
@Autowired
private BService bService;
@Asyn
public void test(){
System.out.println(bService);
}
}
@Component
public class BService {
@Autowired
private AService aService;
}当只开启了AOP(@EnableAspectJAutoProxy),执行初始化后的时候,beanpostprocessor是有八个

当我们在开启异步(@EnableAsync)之后,beanPostProcessor变成了九个,新增了一个处理@Asyn

假如我们开启@EnableAsync并且在AService中的某个方法上加上@Asyn,而AService又出现循环依赖就会报错,原因就是@Asyn处理就是在初始化后调用后置处理器的初始化后方法中又新生成了一个代理对象就会导致初始化后得到的对象exposedObject == bean 不成立了。这种情况其实我们只要在AService的BService属性上加上@Lazy注解就可以了,上篇文章分析依赖注入源码的时候如果注入点被@Lazy注解标记,那么就会生成一个BService的代理对象返回,并不会去getBean(BService),这样就不会出现循环依赖了,AService也会正常创建。当我们创建BService的时候AService已经完成创建了,只不过AService注入的BService是一个代理对象,只有当我们在AService中使用BService时才会去getBean(BService)而这个时候spring其已经启动完成,BService也完成创建了。(可能我描述的不够严谨)
总结
Spring是如何解决的循环依赖?
答:Spring通过三级缓存解决了循环依赖,其中一级缓存为单例池(singletonObjects),二级缓存为早期曝光对象earlySingletonObjects,三级缓存为早期曝光对象工厂(singletonFactories)。当A、B两个类发生循环引用时,在A完成实例化后,就使用实例化后的对象去创建一个对象工厂,并添加到三级缓存中,如果A被AOP代理,那么通过这个工厂获取到的就是A代理后的对象,如果A没有被AOP代理,那么这个工厂获取到的就是A实例化的对象。当A进行属性注入时,会去创建B,同时B又依赖了A,所以创建B的同时又会去调用getBean(a)来获取需要的依赖,此时的getBean(a)会从缓存中获取,第一步,先获取到三级缓存中的工厂;第二步,调用对象工工厂的getObject方法来获取到对应的对象,得到这个对象后将其注入到B中。紧接着B会走完它的生命周期流程,包括初始化、后置处理器等。当B创建完后,会将B再注入到A中,此时A再完成它的整个生命周期。至此,循环依赖结束!
为什么要使用三级缓存呢?二级缓存能解决循环依赖吗?
答:如果要使用二级缓存解决循环依赖,意味着所有Bean在实例化后就要完成AOP代理,这样违背了Spring设计的原则,Spring在设计之初就是通过AnnotationAwareAspectJAutoProxyCreator这个后置处理器来在Bean生命周期的最后一步来完成AOP代理,而不是在实例化后就立马进行AOP代理。
原型bean情况下的循环依赖解析
当ASerive和BService都是原型bean的情况下,循环依赖是无法解决的。
Spring启动完成后当我们代码调用context.getBean(ASerive)时会去创建AService,创建AService前会记录当前原型bean--AService正在创建中(prototypesCurrentlyInCreation:缓存正在创建的原型bean)
org.springframework.beans.factory.support.AbstractBeanFactory#doGetBean

当AService注入BService时,会调用getBean(BService),首先也会去单例池查找:getSingleton(BService),由于BService是原型bean,当BService注入AService时会再次调用getBean(AService)--doGetBean(),spring会判断当前bean是不是正在创建的原型bean,是则抛错
org.springframework.beans.factory.support.AbstractBeanFactory#doGetBean

但是AService和BService一个是单例bean,一个是原型bean,是没有问题的,因为当其中一个原型bean注入单例bean时是可以在单例池中拿到的。
构造方法导致的循环依赖解析
@Component
public class AService {
private BService bService;
public AService(BService bService) {
this.bService = bService;
}
}
@Component
public class BService {
private AService aService;
public BService(AService aService) {
this.aService = aService;
}
}默认是不支持的,我们上面分析解决循环依赖都是在属性注入阶段解决的,也就是在实例化后,可以拿到半成品的bean对象,但是现在我们在实例化阶段就会报错,实例化AService时就需要BService对象。
那怎么解决呢?同样使用@Lazy注解,通过在构造器参数中标识@Lazy注解,Spring 生成并返回了一个代理对象是可以解决构造器循环依赖问题的。
@Component
public class AService {
private BService bService;
@Lazy
public AService(BService bService) {
this.bService = bService;
}
}
@Component
public class BService {
private AService aService;
public BService(AService aService) {
this.aService = aService;
}
}Spring构造器注入循环依赖的解决方案是@Lazy,其基本思路是:对于强依赖的对象,一开始并不注入对象本身,而是注入其代理对象,以便顺利完成实例的构造,形成一个完整的对象,
这样与其它应用层对象就不会形成互相依赖的关系;当需要调用真实对象的方法时,通过TargetSource去拿到真实的对象[DefaultListableBeanFactory#doResolveDependency],然后通过反射完成调用。
@Transactional情况下的循环依赖解析
//配置类中要开启事务:@EnableTransactionManagement
@Component
public class AService {
@Autowired
private BService bService;
@Transactional
public void test(){
System.out.println(bService);
}
}
@Component
public class BService {
@Autowired
private AService aService;
}@Transactional这种情况是可以的。
上面说@Asyn注解的时候,当我们开启异步之后,会新增一个beanPostProcessor,AOP一个代理对象,@Asyn一个代理对象,会有问题。
而当我们开启事务(@EnableTransactionManagement)是不会注入一个beanPostProcessor,而是新注入一个Advisor

可以百度图灵学院,嘘!














 1162
1162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









