






当我们谈到矩阵乘时, 计算机是怎么理解的呢?
Today, 我们用图推理解矩阵乘基础实现, 并测试不同数据布局下的单核性能差别~
C = A X B
行主存储实现
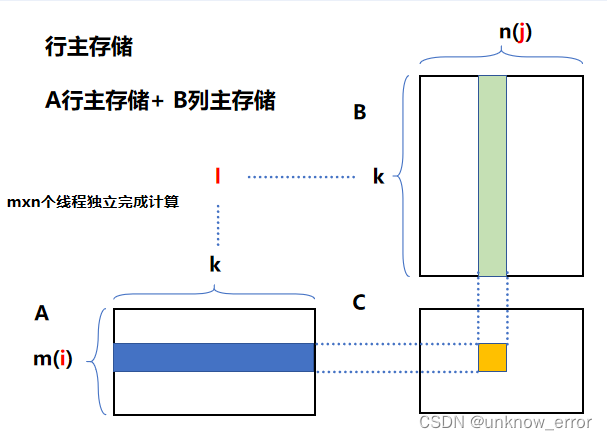
以C矩阵的结果索引计算:
C[n * i + j] = A[i * k + l] + B[l*n+j];
将该索引公式采用循环计算实现:
for (i = 0; i < m; i++) {
for (j = 0; j < n; j++) {
for (l = 0; l < k; l++) {
C[n * i + j] = A[i * k + l] + B[l*n+j];
}
}
}
可以看出, 行主存储的方式对A矩阵来说数据局部性更好, 而对B矩阵则存在访存不连续问题, 若是将B矩阵改为列主存储, 重新计算索引:
C[n * i + j] = A[i * k + l] + B[j*k+l];
//行主 + 列主
for (i = 0; i < m; i++) {
for (j = 0; j < n; j++) {
for (l = 0; l < k; l++) {
C[n * i + j] = A[i * k + l] + B[j*k+l];
}
}
}
分别给出A \B矩阵大小分别给1024x1024 的shape ,测试不同实现:
----------[1024 x 1024]----------
cpu matmul : [ Test count : 1 ; CPU Avg Time : 10294.806000 ms ; Wall Avg Time : 10296.592412 ms ]
cpu matmul with transpose: [ Test count : 1 ; CPU Avg Time : 4750.649000 ms ; Wall Avg Time : 4751.303317 ms ]
速度提升了2.x倍, 说明对CPU来说数据布局的重要程度非常高 .
当然, 第二种实现没有加上transpose的时间, 我们继续编写case进行测试:
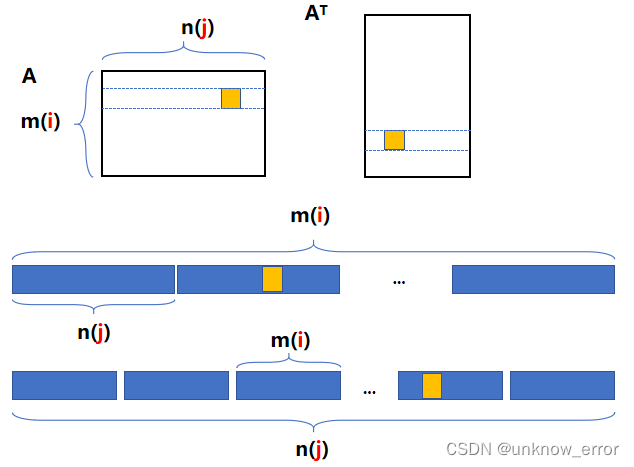
分别单独统计转置加矩阵乘时间:
EVALUATE(cpu_transpose(B_T, B, k, n), 1, "seprate transpose");
EVALUATE(cpu_gemm_with_transpose(A, B_T, C1, m, n, k), 1, "seperate matmul");
cpu matmul: [ Test count : 1 ; CPU Avg Time : 10290.696000 ms ; Wall Avg Time : 10291.367832 ms ]
seprate transpose [ Test count : 1 ; CPU Avg Time : 20.587000 ms ; Wall Avg Time : 20.585797 ms ]
seperate matmul [ Test count : 1 ; CPU Avg Time : 4752.434000 ms ; Wall Avg Time : 4752.665653 ms ]
match
Conclusion
对于大规模矩阵计算, 数据布局对于计算有着非常深刻的影响
CPU上是这种情况, 那么GPU呢, 有什么区别 以及如何优化呢? 明天再写吧
Finish!















 500
500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









