







JOIN在Spark Core中的使用
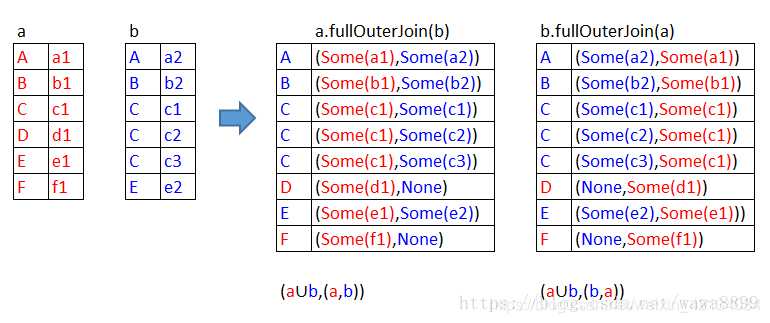
Inner join
inner join,只返回左右都匹配上的
// 启动spark-shell,定义两个rdd,做join操作
[hadoop@hadoop01 ~]$ spark-shell --master local[2]
scala> val a = sc.parallelize(Array(("A","a1"),("B","b1"),("C","c1"),("D","d1"),("E","e1"),("F","f1")))
a: org.apache.spark.rdd.RDD[(String, String)] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> val b = sc.parallelize(Array(("A","a2"),("B","b2"),("C","c1"),("C","c2"),("C","c3"),("E","e2")))
b: org.apache.spark.rdd.RDD[(String, String)] = ParallelCollectionRDD[1] at parallelize at <console>:24
scala> a.join(b).collect // 这里的join是inner join,只返回左右都匹配上的内容
res1: Array[(String, (String, String))] = Array((B,(b1,b2)), (A,(a1,a2)), (C,(c1,c1)), (C,(c1,c2)), (C,(c1,c3)), (E,(e1,e2)))
scala> b.join(a).collect
res2: Array[(String, (String, String))] = Array((B,(b2,b1)), (A,(a2,a1)), (C,(c1,c1)), (C,(c2,c1)), (C,(c3,c1)), (E,(e2,e1)))
scala>
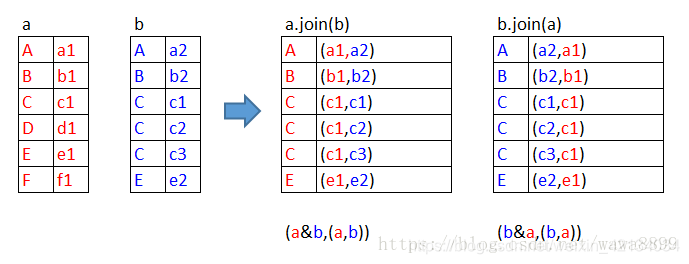
left outer join
left:是以左边为基准,向左靠
scala> a.leftOuterJoin(b).collect
res3: Array[(String, (String, Option[String]))] = Array((B,(b1,Some(b2))), (F,(f1,None)), (D,(d1,None)), (A,(a1,Some(a2))), (C,(c1,Some(c1))), (C,(c1,Some(c2))), (C,(c1,Some(c3))), (E,(e1,Some(e2))))
scala> b.leftOuterJoin(a).collect
res5: Array[(String, (String, Option[String]))] = Array((B,(b2,Some(b1))), (A,(a2,Some(a1))), (C,(c1,Some(c1))), (C,(c2,Some(c1))), (C,(c3,Some(c1))), (E,(e2,Some(e1))))
scala>
左边(a)的记录一定会存在,右边(b)的记录有的返回Some(x),没有的补None。
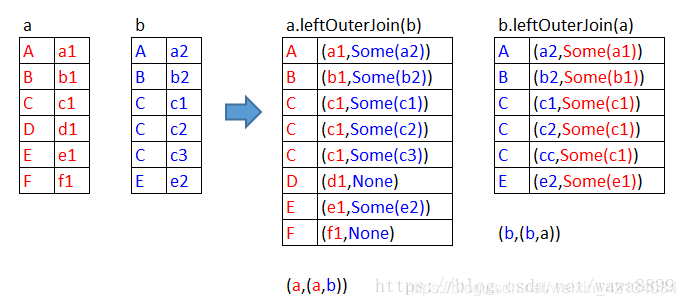
right outer join
right:是以右边为基准,向右靠
scala> a.rightOuterJoin(b).collect
res4: Array[(String, (Option[String], String))] = Array((B,(Some(b1),b2)), (A,(Some(a1),a2)), (C,(Some(c1),c1)), (C,(Some(c1),c2)), (C,(Some(c1),c3)), (E,(Some(e1),e2)))
scala> b.rightOuterJoin(a).collect
res6: Array[(String, (Option[String], String))] = Array((B,(Some(b2),b1)), (F,(None,f1)), (D,(None,d1)), (A,(Some(a2),a1)), (C,(Some(c1),c1)), (C,(Some(c2),c1)), (C,(Some(c3),c1)), (E,(Some(e2),e1)))
scala>
右边(b)的记录一定会存在,左边(a)的记录有的返回Some(x),没有的补None。
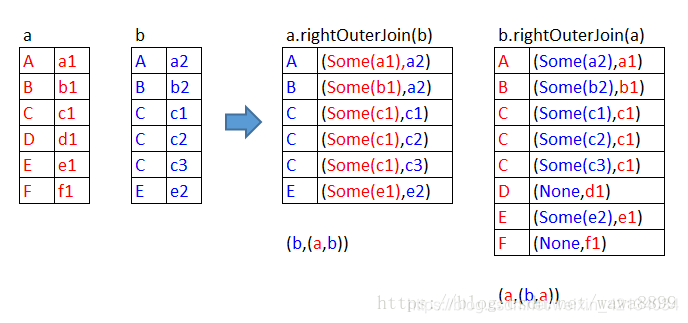
full outer join
scala> val a = sc.parallelize(Array(("A","a1"),("B","b1"),("C","c1"),("D","d1"),("E","e1"),("F","f1")))
a: org.apache.spark.rdd.RDD[(String, String)] = ParallelCollectionRDD[49] at parallelize at <console>:24
scala> val b = sc.parallelize(Array(("A","a2"),("B","b2"),("C","c1"),("C","c2"),("C","c3"),("E","e2")))
b: org.apache.spark.rdd.RDD[(String, String)] = ParallelCollectionRDD[50] at parallelize at <console>:24
scala> a.fullOuterJoin(b).collect
res15: Array[(String, (Option[String], Option[String]))] = Array((B,(Some(b1),Some(b2))), (F,(Some(f1),None)), (D,(Some(d1),None)), (A,(Some(a1),Some(a2))), (C,(Some(c1),Some(c1))), (C,(Some(c1),Some(c2))), (C,(Some(c1),Some(c3))), (E,(Some(e1),Some(e2))))
scala> b.fullOuterJoin(a).collect
res16: Array[(String, (Option[String], Option[String]))] = Array((B,(Some(b2),Some(b1))), (F,(None,Some(f1))), (D,(None,Some(d1))), (A,(Some(a2),Some(a1))), (C,(Some(c1),Some(c1))), (C,(Some(c2),Some(c1))), (C,(Some(c3),Some(c1))), (E,(Some(e2),Some(e1))))
scala>
注意:使用JOIN之前,要知道JOIN之后的数据结构是什么。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









