







在Python爬虫下一代网络请求库httpx和parsel解析库测评一文中我们对比了requests的同步爬虫和httpx的异步协程爬虫爬取链家二手房信息所花的时间(如下所示:一共580条记录),结果httpx同步爬虫花了16.1秒,而httpx异步爬虫仅花了2.5秒。

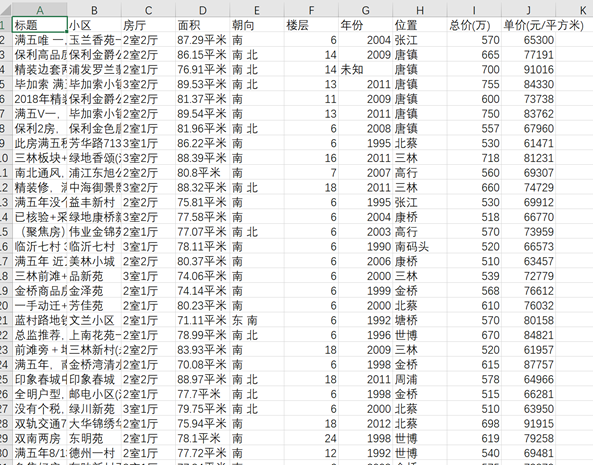
那么问题来了。实现爬虫的高并发不仅仅只有协程异步这一种手段,传统的同步爬虫结合多进程和多线程也能大大提升爬虫工作效率,那么多进程, 多线程和异步协程爬虫到底谁更快呢? 当然对于现实中的爬虫,爬得越快,被封的可能性也越高。本次测评使用httpx爬取同样链家网数据,不考虑反爬因素,测评结果可能因个人电脑和爬取网站对象而异。
在我们正式开始前,你能预测下哪种爬虫更快吗?可能结果会颠覆你的观点。
传统爬虫 vs 协程异步爬虫
传统Python爬虫程序都是运行在单进程和单线程上的,包括httpx异步协程爬虫。如果你不清楚进程和线程的区别,以及Python如何实现多进程和多线程编程,请阅读下面这篇知乎上收藏过1000的文章。
一个传统的web爬虫代码可能如下所示,先用爬虫获取目标页面中显示的最大页数,然后循环爬取每个单页数据并解析。单进程、单线程同步爬虫的请求是阻塞的,在一个请求处理完全结束前不会发送一个新的请求,中间浪费了很多等待时间。
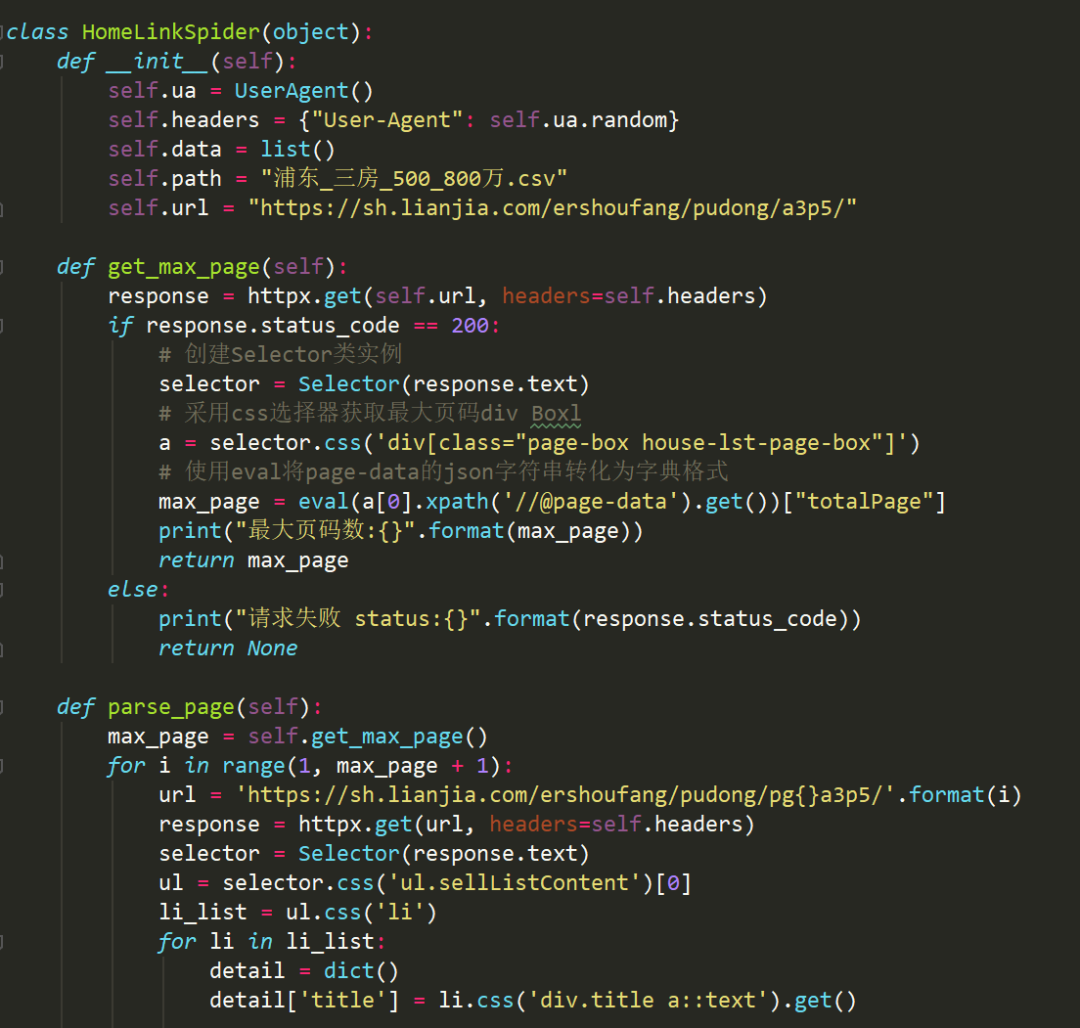
httpx异步协程爬虫虽然也是运行在单进程单线程上的,但是所有异步任务都会加到事件循环(loop)中运行,可以一次有上百或上千个活跃的任务,一旦某个任务需要等待,loop会快速切换到下面一个任务,所以协程异步要快很多。
要把上面的同步爬虫变为异步协程爬虫,我们首先要使用async将单个页面的爬取和解析过程包装成异步任务,使用httpx提供的AsyncClient发送异步请求。
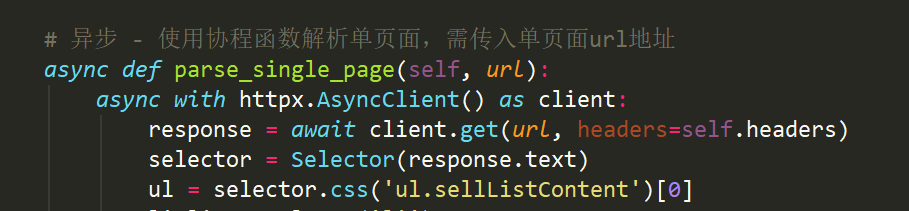
接着我们使用asyncio在主函数parse_page里获取事件循环(loop), 并将爬取单个页面的异步任务清单加入loop并运行。

多进程爬虫
对于多线程爬虫,我们首先定义一个爬取并解析单个页面的同步任务。

接下来我们在主函数parse_page里用multiprocessing库提供的进程池Pool来管理多进程任务。池子里进程的数量,一般建议为CPU的核数,这是因为一个进程需要一个核,你设多了也没用。我们使用map方法创建了多进程任务,你还可以使用apply_async方法添加多进程任务。任务创建好后,任务的开始和结束都由进程池来管理,你不需要进行任何操作。这样我们一次就有4个进程同时在运行了,一次可以同时处理4个请求。
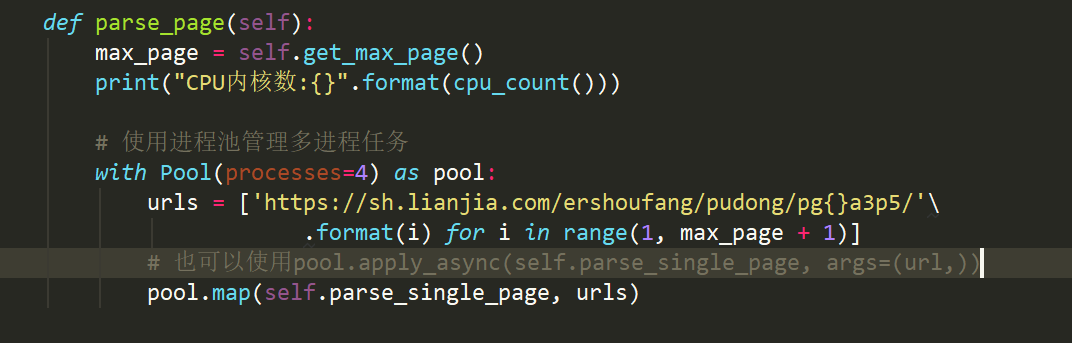
那用这个多进程爬虫爬取链家580条数据花了多长时间呢? 答案是7.6秒,比单进程单线程的httpx同步爬虫16.1秒还是要快不少的。
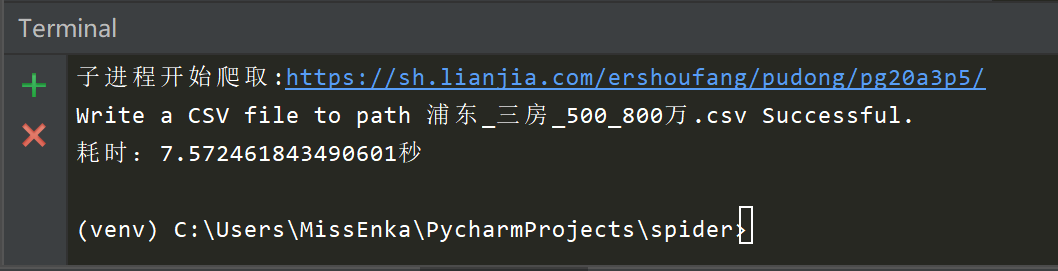
项目完整代码如下所示:
from fake_useragent import UserAgent
import csv
import re
import time
from parsel import Selector
import httpx
from multiprocessing import Pool, cpu_count, Queue, Manager
class HomeLinkSpider(object):
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 750
750











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









