







1. 反向传播会用到前向传播时计算的值,以及cost的公式;但不会用到cost值,cost值只是用来评估当前网络是否收敛。
2.如何实现从全链接层(n)映射到softmax层(k)?
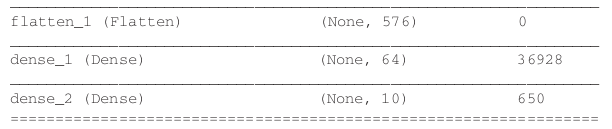
需要在最后将 3D 输出展平为 1D,然后在上面添加几个 Dense 层。
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
![]()

对于单标签、多分类问题,网络的最后一层应该使用 softmax 激活,这样可以输出在 N个输出类别上的概率分布(相加得1)。
这种问题的损失函数几乎总是应该使用分类交叉熵。它将网络输出的概率分布与目标的真实分布之间的距离最小化。
3.用于测试数据标准化的均值和标准差都是在训练数据上计算得到的。在工作流程中,你不能使用在测试数据上计算得到的任何结果,即使是像数据标准化这么简单的事情也不行。
4.K 折交叉验证
为了在调节网络参数的同时对网络进行评估,你可以将数据划分为训练集和验证集,但由于数据点很少,验证集会非常小(比如大约100 个样本)。因此,验证分数可能会有很大波动,这取决于你所选择的验证集和训练集。也就是说,验证集的划分方式可能会造成验证分数上有很大的方差,这样就无法对模型进行可靠的评估。
在这种情况下,最佳做法是使用 K 折交叉验证。这种方法将可用数据划分为 K个分区(K 通常取 4 或 5),实例化 K 个相同的模型,将每个模型在 K - 1 个分区上训练,并在剩下的一个分区上进行评估。模型的验证分数等于 K 个验证分数的平均值。平均分数是比单一分数更可靠的指标——这就是 K 折交叉验证的关键。

5.为什么不是两个集合:一个训练集和一个测试集?在训练集上训练模型,然后在测试集上评估模型。这样不是更简单吗?
原因在于开发模型时总是需要调节模型配置,比如选择层数或每层大小[这叫作模型的超参数(hyperparameter),以便与模型参数(即权重)区分开]。这个调节过程需要使用模型在验证数据上的性能作为反馈信号。这个调节过程本质上就是一种学习:在某个参数空间中寻找良好的模型配置。因此,如果基于模型在验证集上的性能来调节模型配置,会很快导致模型在验证集上过拟合,即使你并没有在验证集上直接训练模型也会如此。
最后,你得到的模型在验证集上的性能非常好(人为造成的),因为这正是你优化的目的。你关心的是模型在全新数据上的性能,而不是在验证数据上的性能,因此你需要使用一个完全不同的、前所未见的数据集来评估模型,它就是测试集。
6.防止神经网络过拟合的常用方法包括:
获取更多的训练数据
减小网络容量
添加权重正则化
添加 dropout
7.为什么需要pooling?
一是减少需要处理的特征图的元素个数,减少参数;二是通过让连续卷积层的观察窗口越来越大(即窗口覆盖原始输入的比例越来越大),从而引入空间过滤器的层级结构。
8.为什么max pooling比mean pooling好?
特征中往往编码了某种模式或概念在特征图的不同位置是否存在,而观察不同特征的最大值而不是平均值能够给出更多的信息。因此,最合理的子采样策略是首先生成密集的特征图(通过无步进的卷积),然后观察特征每个小图块上的最大激活,而不是查看输入的稀疏窗口(通过步进卷积)或对输入图块取平均,因为后两种方法可能导致错过或淡化特征是否存在的信息。
9.预训练网络
使用预训练网络有两种方法:特征提取(feature extraction)和微调模型(fine-tuning)。
10.反卷积
反卷积就是转置卷积,也是一种卷积,可以看到图7,这个就是转置卷积,由小尺寸到大尺寸的过程。也就是说反卷积也可以表示为两个矩阵乘积,很显然转置卷积的反向传播就是也是可进行的。
















 736
736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









