







为什么要引入内存池算法?
- 我们知道C/C++ 语言中通过 malloc 调用 sbrk 和 mmap 这两个系统调用,向操作系统申请堆内存。但是,sbrk 和 mmap 这两个系统调用分配内存效率比较低,因为,执行系统调用是要进入内核态的,这样内核态又要转向用户态,运行态的切换会耗费不少时间。
- 至于为什么执行系统调用是要进入内核态?,可以参考我的这篇文章:Linux 系统调用的本质
- 为了解决这个问题,人们倾向于使用系统调用来分配大块内存,然后再把这块内存分割成更小的块,以方便程序员使用,这样可以提升分配的效率。在 C 语言的运行时库里,这个工作是由 malloc 函数负责的。但有时候 C 语言的原生malloc 实现还是不能满足特定应用的性能要求,这就需要程序员来实现符合自己应用要求的内存池,以便自己进行内存的分配和释放。
- malloc 实现的基本原理是先向操作系统申请一块比较大的内存,然后再通过各种优化手段让内存分配的效率最大化。在 glibc 的实现里,malloc 函数在向操作系统申请堆内存时,会使用 mmap,以 4K 的整数倍一次申请多个页。这样的话,mmap 的区域就会以页对齐,页与页之间的排列非常整齐,避免了出现内存碎片。
内存池算法逐步演进
空闲链表法
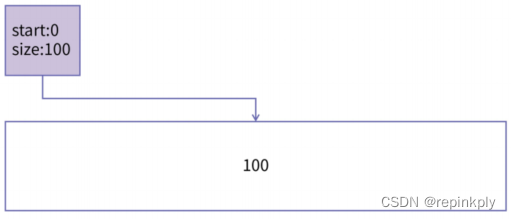
这种算法所使用的数据结构比较简单,算法也很直接,我们把这种算法称为简单算法(Naive Algorithm)。我们举个例子说明简单算法的运行过程,假如在算法开始时,内存的情况如下图所示。
#include <stdio.h>
#include <stdlib.h>
int main(int argc,char* argv[])
{
void* p1 = malloc(16);
void* p2 = malloc(16);
void* p3 = malloc(20);
free(p2);
void* p4 = malloc(16);
void* p5 = malloc(16);
free(p4);
return 0;
}
申请了100字节的内存,执行完 main函数以后,内存的划分就如下所示:
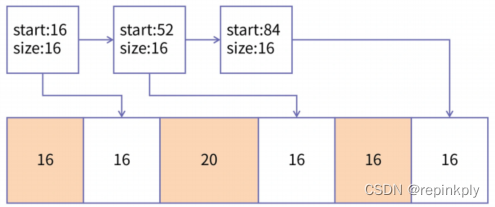
100字节的内存,已经分割成 16、16、20、16、16、16 六个小的内存块。其中着色部分,也就是第一、第三和第五块内存是已经分配出去的,正在使
用的内存,而白色区域则是尚未分配的内存。图的上半部分代表空闲链表,每一块未分配的内存都会由一个空闲链表的节点进行管理。结点中记录了这块空闲内存区域的起始位置和长度。
缺点1: 如果此时,又到达了一个内存分配请求,要申请一个大小为 20 的内存区域,虽然所有空闲区域的大小之和是 48,是超过 20 的,但是由于这三块空闲区域并不连续,所以,我们已经无法从这 100 字节的内存中再分配出一块 20 字节的内存区域了,相对于这次请求,这三块 16 字节的空闲区域就是内存碎片。这就是我们所介绍的简单算法的第一个缺陷:会产
生内存碎片。
**缺点2:**每一次分配内存时,我们都需要遍历 free list,最差情况下的时间复杂度显然是 O(n)。如果是多线程同时分配的话,free list 会被多线程并发访问,为了保护它,就必须使用各种同步机制,比如锁。可见上述算法的第二个缺陷是分配效率一般,且多线程并发场景下性能还会恶化。
分桶式内存管理法
- 分桶式内存管理采用了多个链表,对于单个链表,它内部的所有结点所对应的内存区域的大小是相同的。换句话说,相同大小的区域会挂载到同一个链表上。
- 最常见的方式是以 4 字节为最小单位,把所有 4 字节的区域挂到同一个链表上,再把 8 字节的区域挂到一起,然后是 16 字节,32 字节,这样以 2 次幂向上增长。如下图所示:
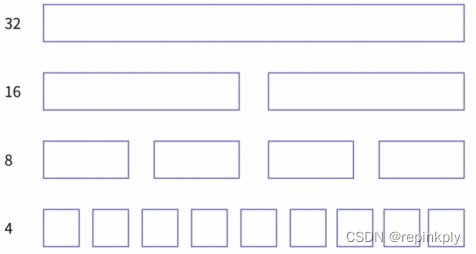
- 采用了新的数据结构以后,分配和回收的算法也相应地发生了变化。首先,分配的时候,我们要只要找到能满足这一次分配请求的最小区域,然后去相应的链表里把整块区域都取下来。比如,分配一个 7 字节的内存块时,我们就可以从 8 字节大小的空闲链表里直接取出链表头上的那块区域,分配给应用程序。由于从链表头上删除元素的时间复杂度是 O(1),所以我们分配内存的效率就大大提高了。
- 由于整个大块内存被提前分割成了整齐的小块(比如是以 4 字节对齐),所以整个区域里不存在块与块之间内存碎片。但是这种做法还是会产生区域内部的空间浪费,比如上面举的例子,当申请的内存大小是 7 时,按当前算法,只能分配给它大小为 8 的块,这就造成了一个字节的内部浪费,或者称之为内部碎片。
- 内部碎片带来的问题是内存使用率没有达到 100%,在最差情况下,可能只有 50%。但是内部碎片随着这一块区域的释放也就消失了,所以不会因为长时间运行而积累成严重的问题。
- 释放时,只需要把要释放的内存直接挂载到相应的链表里就可以了。 这个速度和分配是一样的,效率非常高。
缺点:
- 分桶式内存管理比简单算法无论是在算法效率方面,还是在碎片控制方面都有很大的提升。但它的缺陷也很明显:区域内部的使用率不够高和动态扩展能力不够好。
- 例如,4 字节的区域提前消耗完了,但 8 字节的空闲区域还有很多。如果这个时候应用程序需要很多 1,2,3,4字节内存的时候, 此时就会面临两难选择,如果直接分配 8 字节的区域,则区域内部浪费就比较多,如果不分配,则明明还有空闲区域,却无法成功分配。
- 为了解决上述两个问题,人们在分桶的基础上继续改进,让内存可以根据需求动态地决定小的内存区域和大的内存区域的比例。这种设计的典型就是伙伴系统,我们一起来看下。
伙伴系统算法
- 正如上面的例子所讲的,当系统中还有很多 8 字节的空闲块,而 4 字节的空闲块却已经耗尽,这时再有一个 4 字节的请求,则会出现 malloc 失败的情况。为了避免分配失败,我们其实还可以考虑将大块的内存做一次拆分。
- 如下图所示。分配一块 4 字节大小的空间,在 4 字节的 free list 上找不到空闲区域,系统就会往上找,假如 8 字节和 16 字节的 free list 中也没有空闲区域,就会一直向上找到 32字节的 free list。
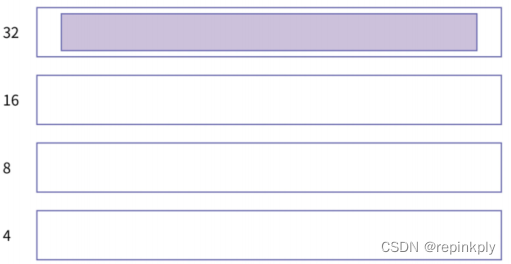
- 伙伴系统不会直接把 32 的空闲区域分配出去,因为这样做的话,会带来巨大的浪费。它会先把 32 字节分成两个 16 字节,把后边一个挂入到 16 字节的 free list 中。然后继续拆分前一半。前一半继续拆成两个 8 字节,再把后一半挂入到 8 字节的 free list;最后,前8 字节继续拆分成2个4字节,把后面4个字节加入 free list中,前面4个字节用于本次malloc分配。分配后的内存的状态如下所示:

- 这种不断地把一块内存分割成更小的两块内存的做法,就是伙伴系统,这两块更小的内存就是伙伴。
- 它的好处是可以动态地根据分配请求将大的内存分割成小的内存。当释放内存时,如果系统发现与被释放的内存相邻的那个伙伴也是空闲的,就会把它们合并成一个更大的连续内存。通过这种拆分,系统就变得更加富有弹性。
malloc 的实现:
15. malloc 的实现,在历史上先后共有几十种策略,这些策略往往就是上述三种算法的组合。具体到 glibc 中的 malloc 实现,它就采用了分桶的策略,但是它的每个桶里的内存不是固定大小的,而是采用了将 1 ~ 4 字节的块挂到第一个链表里,将 5 ~ 8 字节的块挂到第二个链表里,将 9~16 字节的块挂到第三个链表里,依次类推。
16. 在单个链表内部则采用 naive 的分配方式,比如要分配 5 个字节的内存块,我们会先在 5~ 8 这个链表里查找,如果查找到的内存大小是 8 字节的,那就会将这个区域分割成 5 字节和 3 字节两个部分,其中 5 字节用于分配,剩余的 3 字节的空闲区域则会挂载到 1~4这个链表里。
17. 可见 malloc 的实现策略是比较灵活的,针对不同的场景,不同的分配策略的性能表现也是不一样的。很多公司的基础平台都选择自己实现内存池来提供 malloc 接口,这样可以更好地服务本公司的业务。最著名的例子就是 Google 公司实现的 Tcmalloc 库。
18. Tcmalloc 相比起其他的 malloc 实现,最大的改进是在多线程的情况下性能提升。我们知道,在多线程并发地分配内存时,每次分配都要对 free list 进行加锁以避免并发程序带来的问题,这就容易形成性能瓶颈。
为了解决这个问题,Tcmalloc 引入了线程本地缓存 (Thread Local Cache),每个线程在分配内存的时候都先在自己的本地缓存中寻找,如果找到就结束,只有找不到的情况才会继续向全局管理器申请一块大的空闲区域,然后按照伙伴系统的方式继续添加到本地缓存中去。















 1071
1071











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











