






1. 认识正则表达式
1.1 什么是正则表达式?
正则表达式就用某种模式去验证一类字符串是否匹配的公式。通俗讲,就是用一个字符串来描述一个特征,用其去验证另一个字符串是否符合该特征的公式
1.2 正则表达式的组成
正则表达式由:分隔符、表达式、修饰符三部分组成。
分隔符:除字母、数字、反斜线、空白字符的任意字符
表达式:由特殊字符或配特殊字符组成的字符串
修饰符:开启/关闭某些功能/模式
2. 元字符
2.1 什么是元字符?
元字符属于1.2中的表达式的组成部分。
元字符是有特殊作用或者说意义的特殊字符。
2.2 常用的元字符
元字符
描述
示例
.
匹配除了换行符以外的任何字符
\w
匹配字符、数字、下划线、汉字
\d
匹配数字
\b
匹配一个单词的开始和结束
\s
匹配任意空白字符
^
匹配一个字符串的开始
$
匹配一个字符串的结束
-
表示范围
[]
匹配括号中的任意一个字符
*、+、?
量词
2.3 常用量词
2.2很清晰的告诉了我们量词也属于元字符的一部分,量词和其他元字符的区别在于其代表的是数量。
元字符
描述
*
重复0次或更多次
+
重复1次或更多次
?
重复0次或一次
{n}
重复n次
{n,}
重复n次或更多次(最少n次)
{n,m}
重复n-m次(最少n次,最多m次)
2.4 注意
在正则表达式中单词的定义为一个字母或数字的后面为空格或其他特殊字符
3. 匹配规则
3.1 字符组
字符组即我们在一个字符串中需要匹配某个单字符(注意是单字符)时需要用到的匹配规则;
例如:需要匹配一个单词是否为cat、cut,我们可以这样写:
c[au]t
这样当出现cat或cut时则会匹配,但如果出现的是acut/cabt之类格式的单词时则不会匹配。
[au]就是字符组,字符组仅可以匹配一个单字符,需要注意的是字符组中需要匹配的字符有可能出现元字符。这时候就需要转义了。
3.2 转义
转义的含义即我们编程语言中的转义。正则表达式中的转义符为\
例如:需要匹配”{xxx}”时只需要将{和}转义就好了
\{.*\}
3.3 反义
反义可以理解为与上述元字符的含义相反的元字符;
3.3.1常用的反义符
元字符
描述
\W
匹配不是字符、数字、下划线、汉字的字符
\D
匹配不是数字的字符
\B
匹配不是一个单词的开始和结束的字符
\S
匹配不是任意空白字符的字符
[^x]
匹配不是x的字符
[^abcd]
匹配不是a/b/c/d的字符
3.3.2 反义符注意
[^x]中的^不要和匹配字符串开头的^搞混了。可以简单理解为只要^没有出现在表达式的开头就是取反的作用
在实际运用中尽量不要使用反义,因为反义会在无形中了范围。例如想要匹配一个变量的开头时可以使用 [a-zA-Z],而不会使用\D,因为变量的命名还有其他的规则,例如不能使用#等特殊字符,使用\D会扩大范围,无形中增加了隐患
3.4 分支
分支可以理解为我们程序中if(x==n)的x==n(即表达式)
例如:我们如果需要匹配cat/hat的开头可以这么写:
[ch]at
但如果需要匹配toat时,字符组就不能满足我们的需求了,这时就需要使用分支了
(c|h|to)at
正则表达式将()内的内容视作一个整体,|代表分支,即可能存在的多种情况。
3.5 分组
当我们需要单个字符重复多次的时候只需要在字符后面加上限定字符就可以a{3},当我们需要多个字符重复多次时怎么办呢?这个时候就需要分组来实现了
类别
语法
描述
捕获
(exp)
匹配exp,并将捕获的内容分配到自动命名的组里
捕获
(?< Word>exp)
匹配exp,并将捕获的内容分配到名为Word的组里,也可以(?’Word’exp)
捕获
(?:exp)
匹配exp,不分配组名、不捕获内容
零宽断言
(?=exp)
捕获exp后面的位置
零宽断言
(?<=exp)
捕获exp前面的位置
零宽断言
(?!exp)
捕获后面跟的不是exp的位置
零宽断言
(?
捕获前面不是exp的位置
注释
(?#content)
注释内容
例如:我们需要简单的匹配一个IP地址,不使用分组的话需要这样写:
\d{3}.\d{3}.\d{3}
如果使用分组就可以这样写:
(?:\d{3}.){2}\d{3} // 将\d{3}.设置为一个分组匹配2次,最后匹配一个\d{3}
是不是优雅了好多
默认情况下,每个组会拥有一个组号,规则是从左向右开始遇到(为标识,组号从1开始,0为整个正则表达式。
组号的分配会从左到右的扫描两遍,第一遍给未命名组分配,第二遍给已命名组分配
3.6 反向引用
反向引用就是将组中捕获到的文本拿出来作为表达式的一部分。(重复匹配组中捕获到的文本)
例如:我们需要匹配重叠字如hello hello,我们可以这么做:
(?\w+)\s+\k
或者
(\w+)\s+\1
3.7 环视(零宽断言)
环视/断言并不是用于捕获字符串,而是用来声明一个应该为真的事实,当断言为真事表达式才会继续匹配。下述四种断言将匹配的是一个表达式之前或之后的位置是否为真。
3.7.1 顺序肯定环视 (?=exp)
(?=exp) 捕获exp后面的位置
例如我们需要匹配ing结尾的单词的前面的内容,可以这样做:
匹配字符串:reading a book
正则表达式:\b\w+(?=ing\b)
匹配结果: read
断言并不是用于捕获字符串,而是用来声明一个应该为真的事实,当断言为真事表达式才会继续匹配
3.7.2 逆序肯定环视 (?<=exp)
(?<=exp) 捕获exp前面的位置
例如我们需要匹配re开头的单词的后面的内容,可以这样做:
匹配字符串:reading a book
正则表达式:(?<=\bre)\w+\b
匹配结果: ading
断言并不是用于捕获字符串,而是用来声明一个应该为真的事实,当断言为真事表达式才会继续匹配
3.7.3 顺序否定环视 (?!exp)
(?!exp) 捕获后面跟的不是exp前面的位置
即此断言后面的内容不匹配exp的内容
例如我们需要匹配三个数字并且这3位数字后面不能是数字,可以这样做:
匹配字符串:123abc
正则表达式:\d\w{3}(?!\d)
匹配结果: 123
3.7.4 逆序否定环视 (?
捕获前面不是exp的位置
即此断言前面的内容不匹配exp的内容
例如我们需要匹配前面不是小写字母的3位数字,可以这样做:
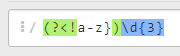
匹配字符串:abc123
正则表达式:https://regex101.com/r/CVTzzc/1
匹配结果:123
3.8 贪婪/懒惰匹配模式
3.8.1 懒惰限定符
限定符
描述
*?
重复任意次,但尽可能少重复
+?
重复1次或更多次,但尽可能少重复
??
重复0次或1次,但尽可能少重复
{n,m}?
重复n到m次,但尽可能少重复
{n,}?
最少重复n次,但尽可能少重复
3.8.2 贪婪模式(默认)
在整个表达式能得到匹配的前提下,尽可能的匹配更多字符
例如用a.*?b匹配aabab匹配出的内容为aabab
3.8.3 懒惰模式
在整个表达式能得到匹配的前提下,尽可能的匹配更少字符
例如用a.*?b匹配aabab匹配出的内容为aab、ab,为什么会匹配出aab的原因是正则表达式有一条优先级更高的匹配规则:最先开始的匹配拥有最高的优先权
4. 构造正则表达式
4.1 正则表达式的逻辑关系
弄清楚正则表达式中之间的逻辑关系有助于更清晰的理解正则表达式。
关系
描述
示例
与
在某个位置,某个元素(字符、字符组、子表达式)必须出现
abc、(?=exp)
或
在某个位置,某个元素可以出现,也可以不出现,或者出现的次数不确定,或者长度不确定
*、?、{n,m}
非
在某个位置,某个元素不出现
^、\D、(?!exp)
4.1.1 与
与是正则表达式中最普遍对关系,如果正则表达式中没有任何量词出现,那么其就是与关系。最能代表与关系的就是abc三个字符。
顺/逆序肯定环视也是与关系。
// 同时出现a、b、c三个字符
abc
// 匹配以ing结尾的单词
(?=ing\d)
4.1.2 或
或是正则表达式中最常见的关系,意思是出现的可能出现,可能不出现、次数不确定、出现的长度不确定。
例如?、*、|等
4.1.3 非
最能代表非关系的就是^、(?!exp)、(?
4.2 运算符优先级
正则表达式的运算符优先级其含义就像数学中的运算符优先级一样。
4.2.1 运算符优先级图表
以下表格按照优先级由高到低排序
运算符
描述
|转义符
()、(?:)、(?=)、[]
括号和中括号
*、+、?、{n}、{n,}、{n,m}、
限定符
^、$、\any、any
定位点和序列
l
替换(反斜线键,makdown表格打不出来,用小写的L代替)
4.3 常用模式
4.3.1 多行模式(m)
开启后将从换行符位置视作一行的结尾
4.3.2 懒惰模式(U)
开启后默认为懒惰模式
4.3.3 utf-8转义表达(u)
开启后可支持使用utf-8字符匹配中文,例如:你等价于你
4.3.4 点号通配模式(S)
开启后点好.将支持匹配换行符
本作品采用《CC 协议》,转载必须注明作者和本文链接















 995
995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









