







https://p0.itc.cn/q_70/images03/20220726/26447de0d3aa4abb8d7b26e231b13e85.png
从ETL 到 ELT
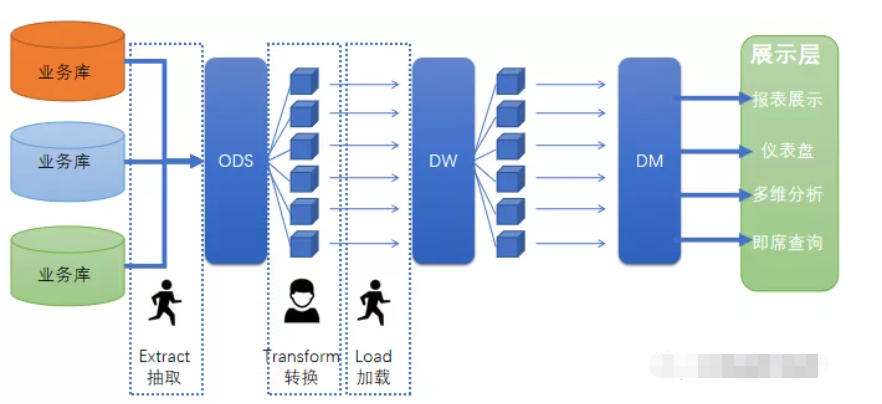
传统数仓ETL的过程:
从业务系统搬数据到ODS(Extract抽取),然后像流水线一样,处理一个环节(Transform转换),再放到一个框里(Load加载),再处理一个环节,再放到一个框里(数仓某一层)。
优势:流水线最大的好处是在固定的处理环节前提下,建设效率最快,成本最优,建好之后基本上只需要维护就行了。
ELT出现的背景:
ETL致命的弱点:流程繁杂且笨重,改动成本过高。
造成ETL过于笨重的原因:T、L过于耦合导致的
ELT的出现:随着snowFlake,BigQuery等云数仓的出现,大量公司开始将本地数仓向云数仓迁移。而云服务带来的最大优势就是灵活性。显然这与传统ETL流程是背道而驰的。所以催生出了ELT的新思路。 ELT的核心思路就是,将T与L拆分开,是的EL工具可以更专注于数据的迁移,而数据工程师专注于数据的T。
ELT的优势:T、L解耦后,将本来线性的流程拆分为不同的部分,使得更换组件、修改业务逻辑更加灵活,能更好的适应复杂的市场。
技术方案:
Airbyte+DBT+AirFlow
Airbyte
简介
AirByte的描述非常简单,它是一个专注于数据E/L的,开源的,国外目前非常流行的数据集成工具。Fivetran的开源替代。
AirByte提供的功能非常简单,即将数据从Source迁移到Destination 。
AirByte帮我们解决了什么问题?
1、常规的数据迁移遇到的问题:
当连接API数据集时,Python就非常方便,而如果连接的是关系型数据库,那Java的JDBC使得能支持更多的数据库。但论Python还是Java,其程序包依赖都很复杂和易错,开发成本各不相同。
而AirByte通过连接器的方式,为我们提供了200个Source类型连接器,100 个Destination类型的连接器来抹平我们对接不同数据源产生的阻碍,做到开箱即用。
Airbyte规定每个connector都放在一个完整的docker镜像中,这个镜像包含了所有运行的依赖,我们甚至可以直接运行和使用这些connector的docker镜像。

全部链接器都是通过docker进行
操作流程
1、通过web页面非常简单的建立Source和Destination
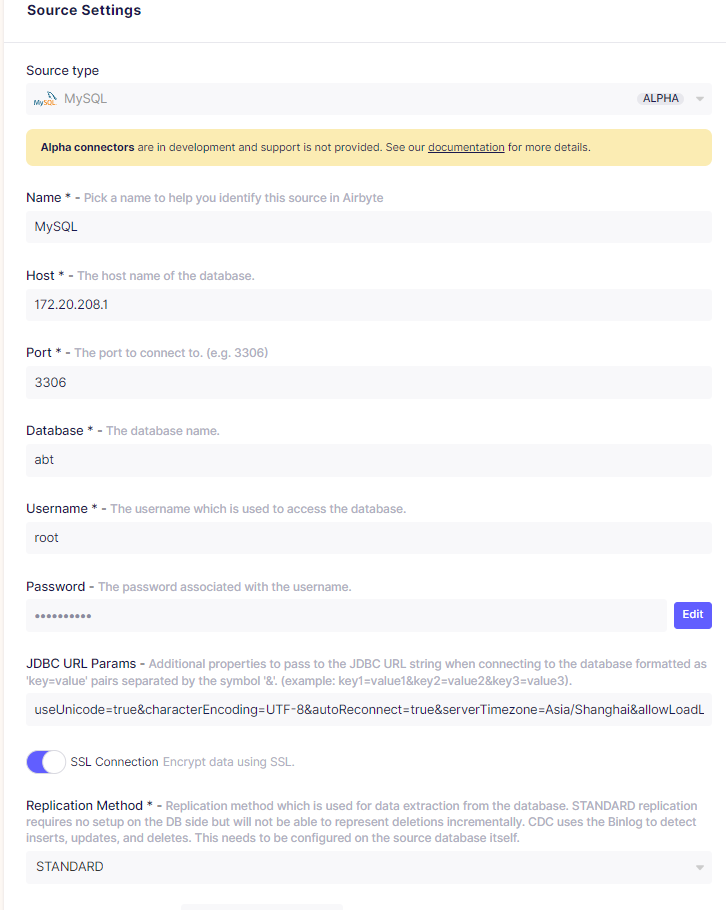
2、建立一个Connect
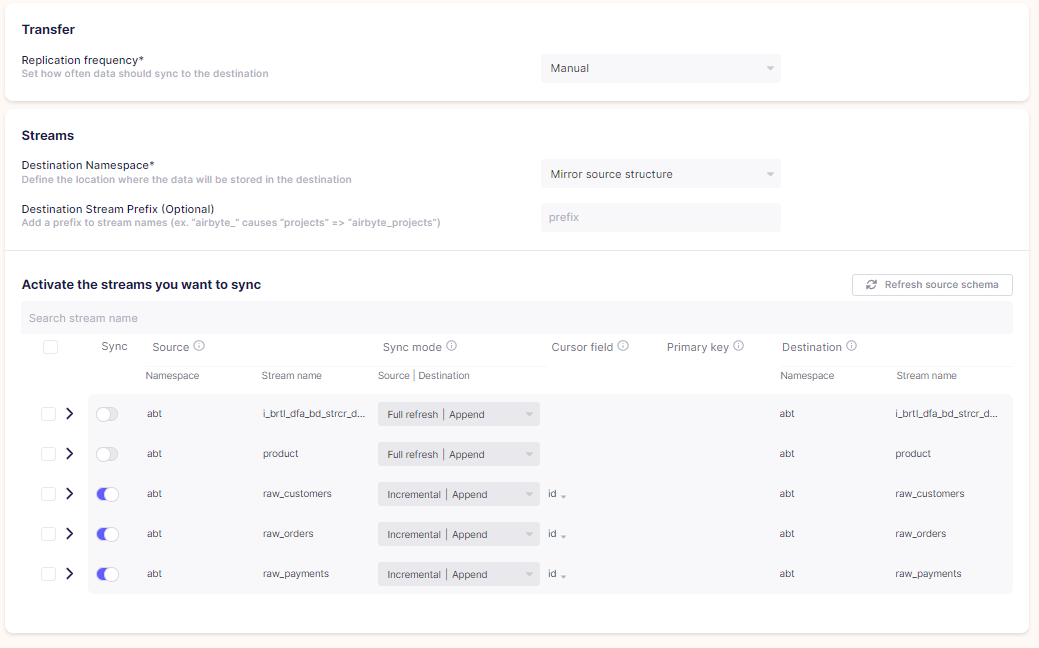
3、建立数据转换 if you want
4、查看运行状态
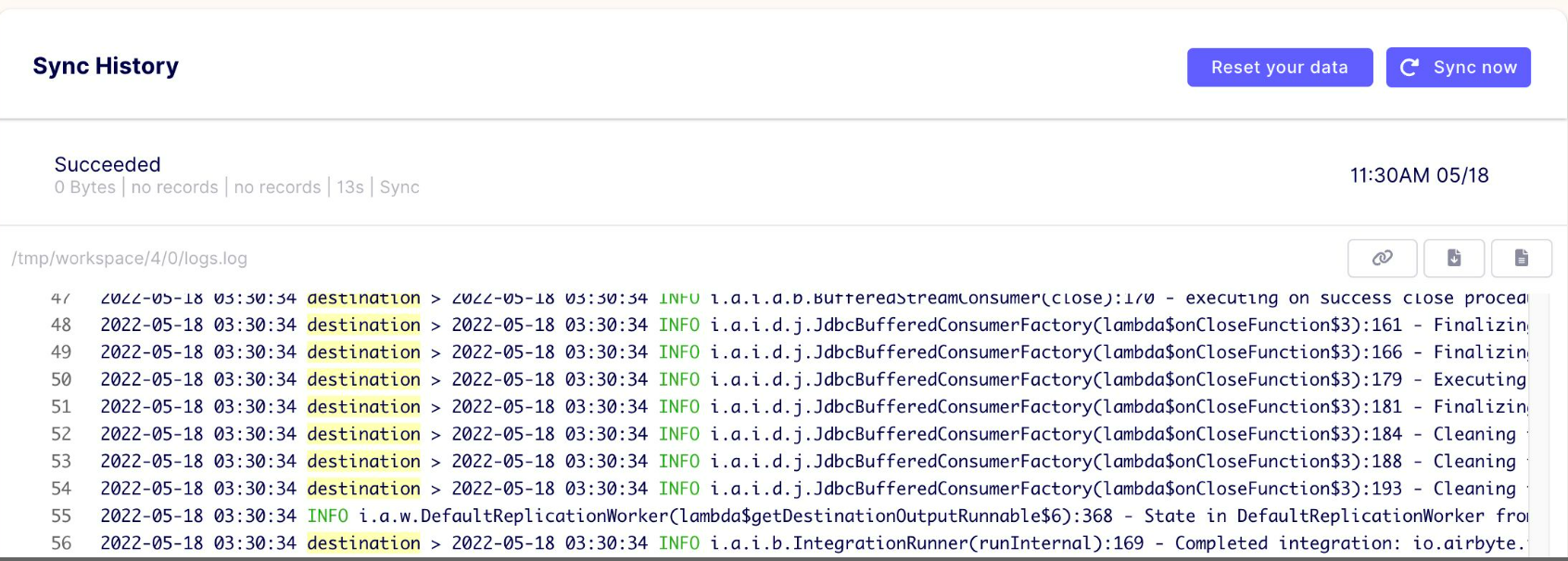
备注:
AirBtye会通过在Source和Destination的目标表中增加一些字段和表来完成迁移工作,会产生侵入性的影响。

AirByte基础架构
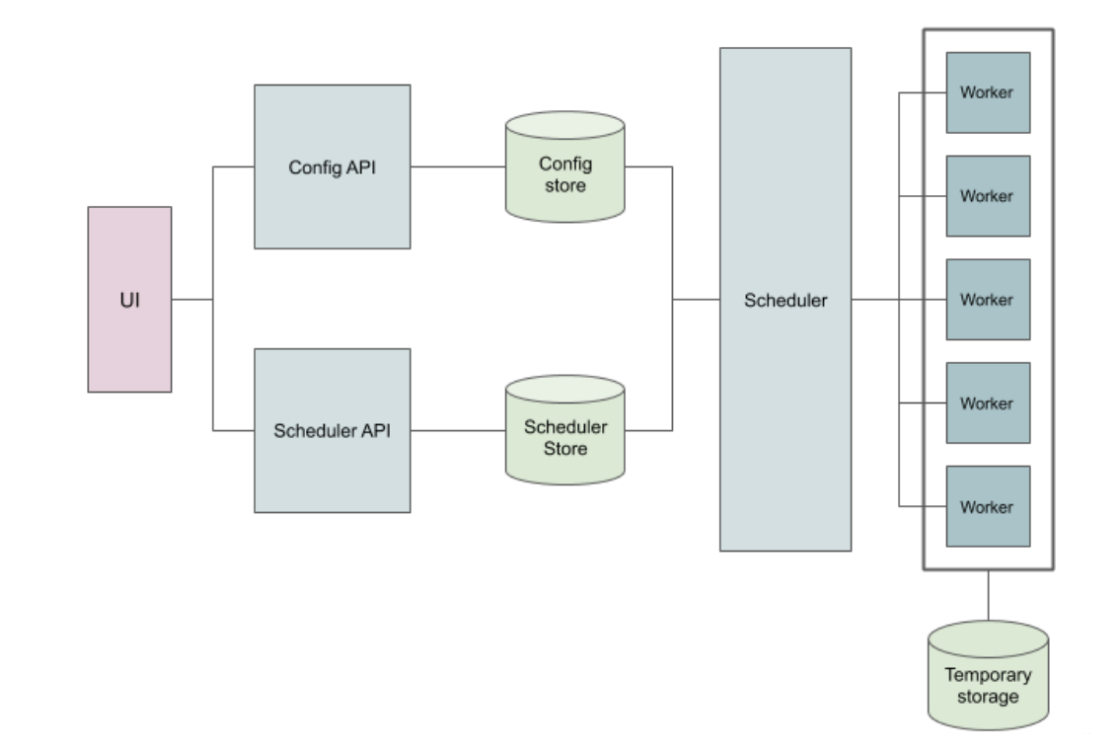
ui 进行配置,以及通过界面查看同步&&日志
config store 关于认证&&同步次信息存储
scheduler 存储关于调度执行情况
config api 方便ui 进行连接配置
scheduler api ui 进行调度job 配置
scheduler 进行数据任务的调度编排以及状态追踪
worker 具体数据从source 到sink 的操作
tep store 临时存储(需要数据写入磁盘的场景)
AirByte工作流程
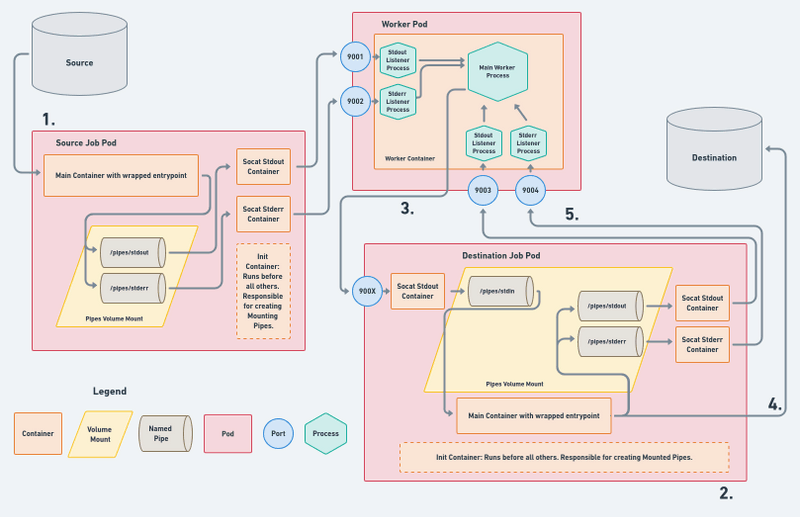
参考:https://airbyte.com/blog/scaling-data-pipelines-kubernetes
worker pod 创建一个源作业 pod。它传递作业 pod 它的 IP 地址和它正在侦听的端口,因此作业 pod 的 socat 边车可以将 stdout/stderr 重定向到它。
worker pod 创建一个destination job pod,并告诉job pod 侦听特定端口,以便它可以将输入发送到destination work pod。worker pod 还为destination pod 打开端口去传输 stdout/stderr 。
使用 socat 和上述机制,source job pod将从source读取的数据传输(pipe)到 Airbyte worker。worker进程在将其发送到destination job pod 之前对其进行验证。
destination pod 的 stdin socat sidecar 接收到这个并将其发送到main container。在写入destination 之前,数据会转换为与目标兼容的格式。
destination pod 的 socat sider car 通过管道将destination job pod 主容器的 stdout/stderr 传回worker 以进行状态和错误处理。
总之,worker pod 位于动态创建的destination pod 和source pod 之间。它读取source pod 的标准输出流,对流数据执行基本验证,并将其提供给destination pod 的标准输入流。所有这一切都可以通过 Kubernetes API、socat、命名管道(named pipe)和sider car容器的整体组合来实现。这种机制为 Airbyte 的所有 Kubernetes 作业提供支持。
RoadMap
反向ETL
反向ETL是一种提取已清理的和处理过的数据架构。通过这种方式,我们可以将我们自己累积的数据资产,变为真正有价值的数据,为我们的BI、预测等功能提供差异化的分析结果。















 514
514











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









