







目录
(五)Temporal instruction fetch streaming
(六)Return address stack-directed instruction prefetching
(七)Proactive instruction fetch
(一)Stride and stream prefetchers for data
(二)Address-correlating prefetchers
4、Improving lookahead via prefetch depth
5、Improving lookahead via dead block prediction
6、Addressing on-chip storage limitations
(三)Spatially-correlating prefetching
2、Global history buffer PC-localized/delta-correlating(GHB/DC)
4、Spatial footprint prediction
Spatio-temporal memory streaming
(四)Execution-based prefetching
2、Helper-Thread and helper-core approaches
(五)Prefetch modulation and control
一、Introduction
(一)为什么需要对缓存进行预取
主要是在CPU 中处理器核和缓存之间的巨大性能差异,这一现象被称为“memory wall"问题。内存墙问题主要是由于处理器与内存性能之间的差距日益扩大。微架构、电路以及制造工艺技术的创新,使得这一时期处理器的性能呈指数级增长。与此同时,动态随机存取存储器(DRAM)主要得益于密度的提升,而其速度仅略有提高。
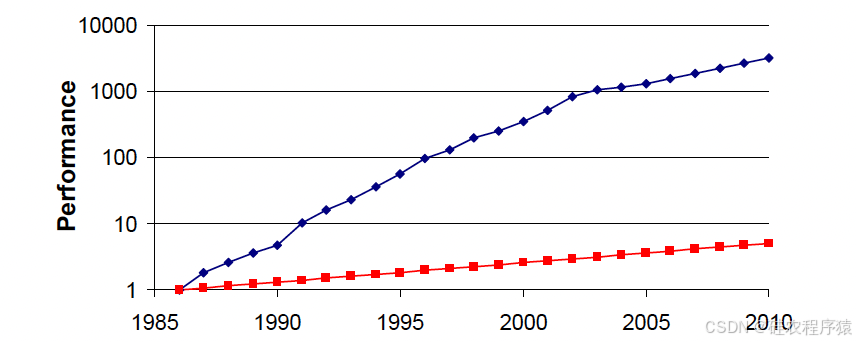
现代mem 的层级,为多级缓存的方式以减小访问处理和内存的速度差异。该层次结构由各级缓存组成,每一级都以容量换取更低的延迟。层次的目的是通过经常在缓存中处理内存请求,避免DRAM相对较长的访问延迟,从而改善表观平均内存访问时间。我们将离核心最近的缓存称为L1缓存,然后依次编号,将最终的缓存称为最后一级缓存(LLC)。
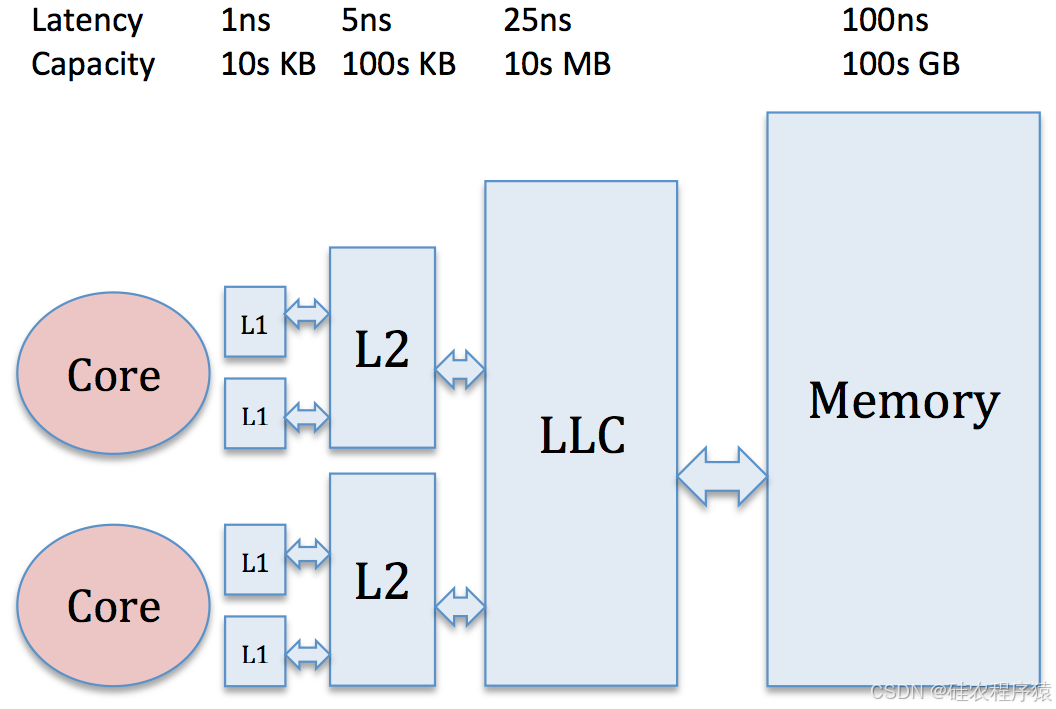
该层次结构依赖于两种类型的内存引用局部性:时间局部性和空间局部性。时间局部性是指最近被访问过的内存很可能会再次被访问。空间局部性是指物理上相邻的内存很可能会被访问,因为相邻的指令和数据通常是相关的。
尽管局部性作为一个概念非常强大,可以用来减少有效内存访问延迟,但它依赖于两个不一定适用于所有工作负载的基本前提,尤其是在缓存层次结构越来越深的情况下。第一个前提是,一个缓存大小适合所有工作负载和访问模式。事实上,现代工作负载的容量需求差异极大,不同的工作负载会从缓存层次结构各级的容量和速度的不同权衡中受益。第二个前提是,一种用于分配和替换缓存条目的策略(通常是按需分配并替换最近未使用的条目)适用于所有工作负载。然而,同样,内存访问模式存在巨大差异,对于决定要缓存哪些块的简单策略来说,这种差异可能导致效果不佳。
从算法、编译器级别和系统软件级别一直到硬件,已经提出了许多技术来克服“内存墙”。这些技术包括缓存无关算法、编译器级别的代码和数据布局优化,以及以硬件为中心的方法。此外,还提出了许多基于软件的预取技术。本文主要介绍基于硬件的指令和数据预取技术。
(二)预取条件
减少mem 访问延迟的一个方法是prefetch,预取是指预测后续的内存访问,并在实际内存访问之前提前获取所需的值,以减小任何可能的长延迟。在理想情况下,内存访问不会产生任何额外的开销,内存的性能似乎与处理器寄存器的性能相当。然而,在实际操作中,预取可能并不总是及时或准确。延迟或不准确的预取会浪费能量,在最坏的情况下,甚至会损害性能。
为了有效地减少延迟,预取机制必须做到以下几点:
- (1)预测内存访问的地址(即准确)
- (2)预测何时发出预取指令(即及时)
- (3)选择将预取的数据存放在何处(以及可能选择替换哪些其他数据)。
-
地址预测
地址预测并不容易但非常重要,如果预测不准确,prefetching会造成cache hierarchy 的污染(即预取的缓存块会驱逐可能有用的缓存块),并在内存系统中产生过多的流量和争用。
数据引用可以是对独立变量或数据结构元素的访问,引用的性质取决于程序在特定执行实例中所做的操作。有很多方法使得内存地址难以预测。包括,但不限于,对变量的交叉访问,多个数据结构,以及控制流相关的遍历(例如,搜索二叉树)。
指令的应用则包括顺序执行程序和分支指令。也取决于cache de hier层级。
在预取策略的侵略性和准确性之间通常存在tradeoff,更积极的预取将预测处理器实际请求的地址的更高比例,但代价是错误地获取更多地址。由于这个原因,许多预取器的评估研究报告了两个关键指标,这两个指标共同表征了预取器在预测地址方面的有效性。覆盖率测量预取成功的显式处理器请求的比例(即,预取消除的需求缺失的比例)。准确率衡量的是由预取器发出的访问中最终被证明为有用的部分(即,在所有预取操作中,正确预取的比例)。许多简单的预取器可以通过牺牲准确率来提高覆盖率,而理想的预取器则能够提供高准确率和覆盖率。
-
超前预取的时间
预取的时间不能过早,也不能太晚。如果预取器过早地发出预取指令,它可能无法在数据被访问之前将所有预取的内存数据长时间保留在处理器附近。在最好的情况下,过早预取将是徒劳的,因为预取的信息会在使用之前被从处理器中逐出。在最坏的情况下,它可能会逐出其他有用的信息(例如,其他预取的内存数据或高级缓存中的有用数据块)。
如果内存预取得太晚,那么在内存访问时就会暴露出内存访问延迟,从而降低预取的有效性。在极端情况下,过晚的预取可能会导致性能下降,因为这会增加内存系统流量,并与旨在优先处理时间关键型需求访问的机制产生。
-
放置预取的值
数据预取的最简单且可能是最古老的软件策略是将其像任何其他显式加载操作一样加载到处理器寄存器中。许多架构,特别是现代乱序处理器,在发出加载指令时并不会阻塞执行,而是仅当另一个指令使用加载的值时才阻塞依赖该加载值的指令。这种预取策略通常被称为绑定预取,因为在预取发出时,后续使用该数据的值就已经被绑定了。这种方法存在许多缺点:(1)它消耗了宝贵的处理器寄存器资源,(2)它强制硬件执行预取操作,即使内存系统已经重载,(3)如果预取地址错误,会导致语义上的困难(例如,预取一个无效地址是否应该导致内存保护故障?),(4)如何将这种策略应用于指令尚不清楚。
相反,大多数硬件预取技术将预取的值直接放入缓存层次结构中,或者放入增强缓存层次结构的补充缓冲区中,并且这些值和缓冲区是可以并行访问的。在多核和多处理器系统中,这些缓存和缓冲区参与了缓存一致性协议,因此在预取和后续访问之间的间隔期间,预取内存位置的值可能会发生变化;硬件有责任确保访问看到的是最新值。这种预取策略被称为非绑定预取。
二、指令预取
指令stall 是一个非常重要的性能瓶颈,指令获取stall对于具有大型指令工作集的工作负载的性能是有害的。当指令的供应速度减慢时,无论处理器的流水线执行资源有多么丰富,这些资源都会被浪费。虽然桌面和科学计算工作负载通常表现出较小的指令工作集,但传统的服务器工作负载和新兴的云工作负载的主要指令工作集往往远远超过上级缓存(upper-level caches)所能容纳的范围。
随着软件快速开发、脚本范式以及具有越来越深软件栈的虚拟化环境的发展趋势,主要指令工作集也在快速增长。现代硬件指令调度技术,如乱序执行(Out-of-Order Execution),通常能够有效地隐藏由于数据访问和其他长延迟指令引起的部分或全部停滞。然而,乱序执行通常无法隐藏指令获取的延迟。因此,指令stall经常占服务器中总体内stall的很大一部分。
(一)Next-line Prefetching
Next-line prefetch是指令预取的最简单形式,在大多数现代处理器设计中都很流行。因为代码是在连续的内存地址中按顺序排列的,所以指令缓存中通常有一半以上的查找是针对顺序地址的。生成顺序地址和获取它们所需的逻辑很少,而且相当容易合并到处理器和缓存层次结构中。

(二)Fetch-directed Prefetching
Next-line预取器非常有效且高效,但指令查找中只有一半是顺序的。控制流指令会打断顺序获取并造成获取中的不连续性,因此需要对未来的控制流进行预测和前瞻。
分支预测器导向的预取器复用现有的分支预测器来探索未来的控制流。这些技术利用分支预测器递归地进行未来预测,以找到用于预取的指令块地址。因为分支预测器在理论上与流水线的其余部分是一阶解耦的,所以预测器可以理论上在执行之前任意程度地前进,以预测未来的控制流。
“Fetch-directed instruction prefetching”(FDIP,取指指令预取),是基于分支预测器导向的最佳技术之一。
FDIP的概念与结构:
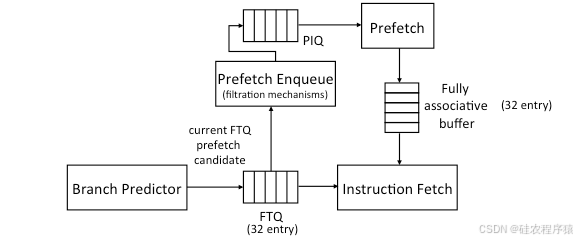
FDIP(取指指令预取)技术旨在将分支预测器与L1指令取指单元(L1 Instruction Fetch Unit)的停滞(stalls,即等待时间)解耦。通过在两个结构之间引入一个“取指目标队列”(Fetch Target Queue,FTQ)来实现。
预取器(Prefetcher)使用FTQ中的地址从L2缓存中取指令块,并将它们放置在一个小的、全相联的缓冲区中。这个缓冲区可以与L1缓存并行地被指令取指单元访问,从而实现与其他L1指令取指的重叠预取。
避免缓冲区与L1之间的冗余:
为了避免缓冲区与L1缓存之间的数据冗余,FDIP利用L1指令缓存的空闲端口来探测(probe)缓存中FTQ中的地址是否已经存在。只有当地址在L1中不存在时,才会将这些缺失的地址加入“预取指令队列”(Prefetch Instruction Queue,PIQ)以进行预取。
FDIP的效果与限制:
FDIP类机制在商业服务器应用程序中的预取效果,这些应用程序由于指令缓存未命中(misses)而产生了大量的停滞。
尽管FDIP在减少指令取指停滞方面很有效,但它从根本上受限于其有限的预取前瞻(prefetch lookahead)能力。
量化了分支预测带宽与预取前瞻之间的关系。结果表明,近一半的指令缓存未命中需要超过16个连续正确的分支预测(不包括内部循环分支)才能生成候选预取地址。这意味着,对于许多情况,FDIP可能无法足够提前地预取指令,从而限制了其性能提升潜力。
(三)Discontinuity Prefetching
1、取指不连续性的挑战:
当程序执行过程中遇到函数调用、分支跳转(特别是条件分支的跳转)或陷阱时,指令的取指序列会被中断,形成取指不连续性。
这些不连续性使得指令预取变得复杂,因为预取器需要预测下一个要取指的指令位置,而这在存在不连续性的情况下变得非常困难。
2、解决控制流不连续性的方法:
多种解决控制流不连续性的方法,如“错路预取”(Wrong-path prefetching)、分支历史引导预取(Branch-history guided prefetcher)、执行历史引导预取(Execution-history guided prefetcher)、多流预测器(Multiple-stream predictor)、下一条跟踪预测器(Next-trace predictors)和调用图预取(Call graph prefetching)等。
错路预取是一种简单的方法,它利用分支预测器但预测相反的路径。尽管这种方法的有效性有限,但它可以预取过数据依赖分支和通过后退循环分支的出口处的指令,这些是FDIP(Fetch-directed instruction prefetching)无法预取的。
其他方法则通过跟踪早期指令来预测不连续性,这些预测与分支预测器独立进行。
3、调用图预取和不连续性预测器:
调用图预取针对服务器应用程序中重复的深层调用栈进行预测,尝试同时预测即将到来的调用栈,而不仅仅是下一个不连续性。
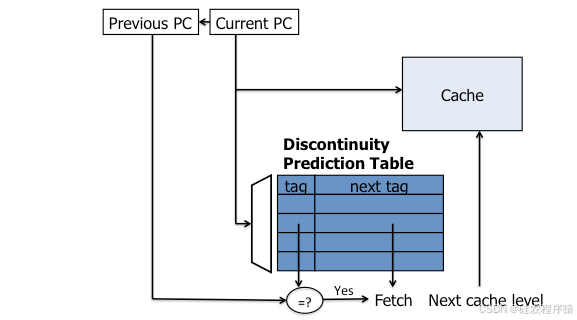
文中提到的一个最新例子是不连续性预测器(Discontinuity predictor),它维护了一个取指不连续性的表,将包含跳转分支的程序计数器(PC)映射到分支目标。
当预取器(特别是下一行指令预取器)在取指单元之前探索时,它会用每个块地址查询不连续性表,并在匹配时除了顺序路径外还预取不连续路径。
4、不连续性预测器的限制:
尽管不连续性预测器简单且所需硬件最少,但它只能桥接一个取指不连续性。
递归查找以探索额外路径会导致预取块数量的指数增长,因此限制为最多遍历一个不连续性,这限制了预取器的前瞻能力。
覆盖率有限,因为表只记录每个缓存块的一个不连续性,而在某些情况下,一个指令块内会发生多个跳转分支。
(四)Prescient Prefetch
- 利用空闲或并行资源进行指令预取:
为了提高指令预取的效率,研究者提出了利用处理器中的空闲或并行资源来进行指令预取的方法。
- Prescient Fetch 技术:
Prescient Fetch 技术使用辅助线程(helper threads)来识别关键的计算和控制转移,并提前执行它们,以辅助运行较慢且与之并行的主线程。
这些方法可以用于循环和函数调用之外的指令预取,但其中只有Prescient Instruction Fetch是专门为这一目的而设计的。
- Speculative Threading 技术:
Speculative Threading 技术通过识别关键执行信息,并利用这些信息来超越主线程,提前发出指令预取请求。
这些技术能够遍历多个取指不连续性(fetch discontinuities),但由于它们是以单个指令为粒度来遍历未来的指令流,因此其前瞻能力仍然有限。
为了发现一个新的用于预取的缓存块,Speculative Threading 技术通常需要遍历大量的指令。
- 总结:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









