







《每个知识点都应该是唯一的——DRY原则》源站链接,阅读体验更佳~
《软件设计第一步——分离关注点和单一职责原则》一文中,我们提到了软件设计中至关重要的第一步——分离关注点,所谓的分离关注点其实就是识别各种知识点,并把相关的知识点封装在同一个模块中。经过关注点的分离之后,我们的复杂系统最终会被切分到一个层次,在这个层次上原本那些复杂的单元被精简为一个具有单一职责的单元,我们称这样的单元为最小粒度单元,每一个这样的最小粒度单元所负责的都是一个单一的知识点。
在这篇文章中,我们将会介绍另一个我认为非常重要和基础的软件设计原则——DRY原则。
DRY的英文描述为:Don’t Repeat Yourself。翻译成中文就是:不要做重复的事。对于这个原则想必同学们都有所耳闻。你可能觉得这条原则非常的简单,也非常容易应用——只要两段代码长得一样,那不就是违反了DRY原则了吗?真的是这样吗?答案是否定的。其实很多人都会有这样的误解,实际上,即使是重复的代码也不一定违反了DRY原则,而且有些看似不重复的代码,实际上可能违反了DRY原则。DRY原则真正的核心并不是禁止重复代码的出现,其核心应该是:每一个知识点都应该有一个唯一的、明确的、权威的表示。
上文提到,经过拆分后的每一个最小粒度单元都负责一个单一的知识点,DRY原则所指出的其实就是每个单元负责的知识都是唯一的,不会有其他的单元跟它负责相同的知识,对于一个知识点来讲,负责它的最小粒度单元应该是唯一的。通过上文的描述,想必大家也能发现,想要真正做到DRY,首先需要做好的就是关注点的分离和单一职责的划分。
既然DRY真正的内核不是禁止重复代码的出现,那么什么样的重复才是我们应该去避免的呢?而什么样的重复又是被允许的甚至是必要的呢?
重复代码就一定违背DRY吗?
重复的代码其实是非常令人讨厌的,甚至一些比较强大的IDE比如idea都内置了识别重复代码的功能,只要我们的代码中出现了大段逻辑相似的代码,IDE就会给出提示并建议我们对代码进行重构。确实,一旦我们的代码中出现了重复的代码,大概率就意味着同一个知识点出现了两个或者多个表示,这种情况下肯定是违反了DRY原则的。
但是,仅仅通过代码是否有重复是无法判断代码是否违反DRY的,原因是我们理解的代码重复可能是传统意义上的文本重复,这格局就小了,其实代码重复的形式有非常多,文本重复只是最浮于表面最明显的一类,这往往也是Ctrl+C/V的产物。其实还有很多的代码重复的情况我们一眼是看不出来的,最典型的三种代码重复的场景是:实现逻辑重复、功能语义重复和代码执行重复。下面我们就针对这三种场景来对DRY原则进行一个简单的分析。
实现逻辑重复
实现逻辑重复其实和文本重复是非常接近的,也是比较容易发现的一类代码重复,而产生这种重复的原因往往也是Ctrl+C/V。甚至我们可以把实现逻辑重复等同于代码文本重复。
我们先来看一下下面的Java代码:
public class UserAuthenticator {
public void authenticate(String username, String password) {
if (!isValidUsername(username)) {
// ...throw InvalidUsernameException...
}
if (!isValidPassword(password)) {
// ...throw InvalidPasswordException...
}
//...省略其他代码...
}
private boolean isValidUsername(String username) {
// check not null, not empty
if (StringUtils.isBlank(username)) {
return false;
}
// check length: 4~64
int length = username.length();
if (length < 4 || length > 64) {
return false;
}
// contains only lowcase characters
if (!StringUtils.isAllLowerCase(username)) {
return false;
}
// contains only a~z,0~9,dot
for (int i = 0; i < length; ++i) {
char c = username.charAt(i);
if (!(c >= 'a' && c <= 'z') || (c >= '0' && c <= '9') || c == '.') {
return false;
}
}
return true;
}
private boolean isValidPassword(String password) {
// check not null, not empty
if (StringUtils.isBlank(password)) {
return false;
}
// check length: 4~64
int length = password.length();
if (length < 4 || length > 64) {
return false;
}
// contains only lowcase characters
if (!StringUtils.isAllLowerCase(password)) {
return false;
}
// contains only a~z,0~9,dot
for (int i = 0; i < length; ++i) {
char c = password.charAt(i);
if (!(c >= 'a' && c <= 'z') || (c >= '0' && c <= '9') || c == '.') {
return false;
}
}
return true;
}
}
上面的代码非常简单,注释也比较详尽,这里就不做过多的解释了。上面的代码中有两处非常明显的重复代码片段:isValidUserName()和isValidPassword()函数,两个函数的代码对比如下:
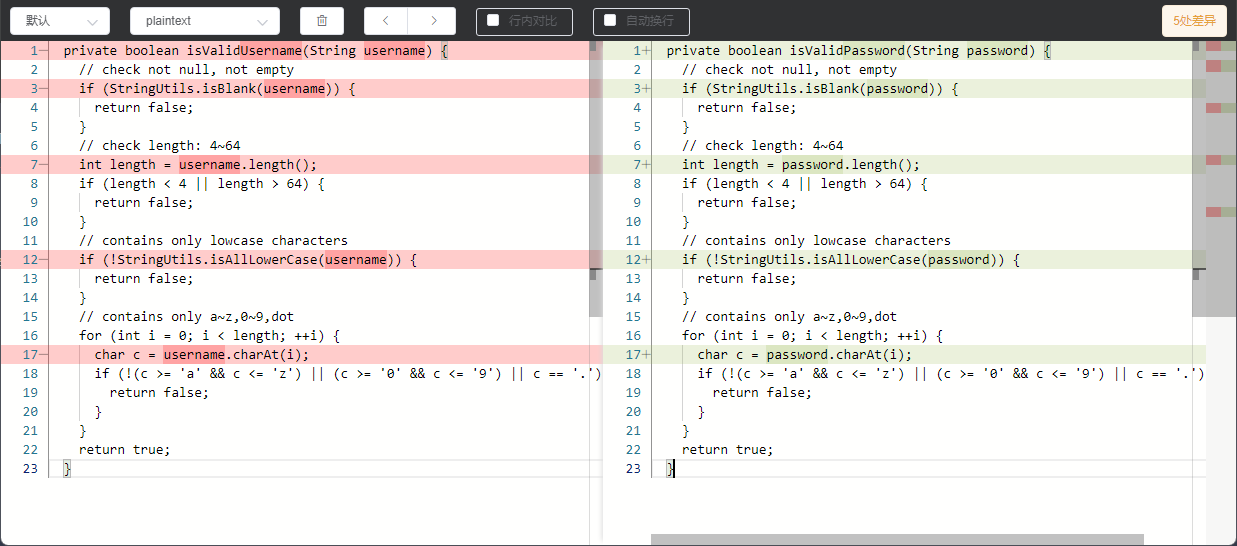
从上面的对比结果可以看出,isValidUserName()和isValidPassword()函数的功能是一模一样的,甚至我们感觉就是在写完isValidUserName()函数之后又复制了一份出来,稍作修改就产生了isValidPassword()函数,那么这段代码违反了DRY原则吗?我们先按照常规的思路,把这两个函数合并起来,看看合并之后会不会存在其他的问题。
这里,我们可以把isValidUserName()和isValidPassword()合并成同一个函数isValidUserNameOrPassword(),但是合并之后的isValidUserNameOrPassword()函数存在另一个问题,很明显isValidUserNameOrPassword()这个函数负责了两个知识点——校验用户名和校验密码,这明显违反了单一职责原则。
为什么会出现这种两难的境地呢?这是因为isValidUserName()和isValidPassword()虽然在功能实现上是完全一样的,但是其实从语义上来讲它们并不是重复的。“语义不重复”指的是:从功能上来看,这两个函数干的是完全不相同的两件事,一个是校验用户名,一个是校验密码。尽管在目前的设计中,用户名和密码的校验逻辑是完全一样的。但是如果按照合并的写法把二者合并为一个函数,就成了一个函数同时负责用户名和密码的校验,如果在未来的某一天,用户名和密码的校验逻辑变得不一样了,那么代码就需要重新拆分开来,而且一个处理不好可能会产生校验用户名或者校验密码逻辑不正确的bug。
**所以,尽管上面的isValidUserName()和isValidPassword()两个函数的代码基本上一样,但是它们具有明显不同的语义,也就是说,这两个函数是不同知识的表示,所以我们判断上面的两个函数并没有违反DRY原则。其实对于上面代码的重构,其重复的根源来自于拆分的粒度不够细。**对于包含重复代码的问题,我们可以通过抽象成更细粒度函数的方式来解决。比如将校验只包含 a-z、0-9、dot 的逻辑封装成 boolean onlyContainsCharAndDot(String str); 函数,通过把各种单一的校验规则封装成单独的函数,使得各种校验规则成为单一的知识点,而在校验用户名和校验密码的逻辑是组合使用单一的校验规则来实现逻辑。
功能语义重复
下面我们来看一个和上面的例子正好相反的一个示例:
public boolean isValidIp(String ipAddress) {
if (StringUtils.isBlank(ipAddress)) return false;
String regex = "^(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|[1-9])\\."
+ "(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|\\d)\\."
+ "(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|\\d)\\."
+ "(1\\d{2}|2[0-4]\\d|25[0-5]|[1-9]\\d|\\d)$";
return ipAddress.matches(regex);
}
public boolean checkIfIpValid(String ipAddress) {
if (StringUtils.isBlank(ipAddress)) return false;
String[] ipUnits = StringUtils.split(ipAddress, '.');
if (ipUnits.length != 4) {
return false;
}
for (int i = 0; i < 4; ++i) {
int ipUnitIntValue;
try {
ipUnitIntValue = Integer.parseInt(ipUnits[i]);
} catch (NumberFormatException e) {
return false;
}
if (ipUnitIntValue < 0 || ipUnitIntValue > 255) {
return false;
}
if (i == 0 && ipUnitIntValue == 0) {
return false;
}
}
return true;
}
上面代码中的两个函数isValidIp()和checkIfIpValid()的功能是一样的,都是校验一个字符串是不是一个合法的IP地址,之所以同一个项目中会出现两个功能相同的函数是因为项目中的两个开发者都需要校验IP地址的功能,但是它们彼此并不知道对方也开发了相同的功能。
可以看出来,这个例子和上面的例子正好是两个相反的代码重复的场景,在这个例子里面,isValidIp()和checkIfIpValid()的代码实现上没有任何相似之处,但是它们的语义是重复的,也就是功能重复了。这种情况明显违反了DRY原则,因为很明显**同一个知识,出现了两个不同的表示。**而解决这个重复的方式非常简单,我们只保留二者中的一个就可以了。
语义重复其实是一种非常令人讨厌的代码重复,假设我们不统一实现思路,在项目中有的地方使用isValidIp()来校验IP地址,而有的地方使用checkIfIpValid()来校验IP地址,这就会导致代码看起来很奇怪,给不熟悉这部份代码的同事增加了阅读的难度,同事可能研究了半天觉得两个函数的功能是一样的,但是有有点疑惑,认为可能是有什么更深层次的考虑才定义了两个功能类似的函数。
而且,语义重复很容易造成知识的不唯一、不明确、不权威,造成逻辑上的不统一甚至使系统产生难以预料的bug。比如,如果哪天项目中 IP 地址是否合法的判定规则改变了,255.255.255.255 不再被判定为合法的了,相应地,我们对 isValidIp() 的实现逻辑做了相应的修改,但却忘记了修改 checkIfIpValid() 函数。又或者,我们压根就不知道还存在一个功能相同的 checkIfIpValid() 函数,这样就会导致有些代码仍然使用老的 IP 地址判断逻辑,导致出现一些莫名其妙的 bug。
其实DRY原则最核心的思想就是消除语义重复类型的代码重复,因为语义重复真的是“做了相同的事”。
代码执行重复
前两个例子一个是实现逻辑重复,一个是语义重复,下面我们再来看第三种情况,首先看如下的示例代码:
public class UserService {
private UserRepo userRepo;//通过依赖注入或者IOC框架注入
public User login(String email, String password) {
boolean existed = userRepo.checkIfUserExisted(email, password);
if (!existed) {
// ... throw AuthenticationFailureException...
}
User user = userRepo.getUserByEmail(email);
return user;
}
}
public class UserRepo {
public boolean checkIfUserExisted(String email, String password) {
if (!EmailValidation.validate(email)) {
// ... throw InvalidEmailException...
}
if (!PasswordValidation.validate(password)) {
// ... throw InvalidPasswordException...
}
//...query db to check if email&password exists...
}
public User getUserByEmail(String email) {
if (!EmailValidation.validate(email)) {
// ... throw InvalidEmailException...
}
//...query db to get user by email...
}
}
简单解释一下上面的代码,UserService中的login()函数用来校验用户登录是否成功。如果失败就抛出异常,如果成功就返回用户信息。这段代码里既没有重复逻辑,也没有重复语义,理论上来说,上面的代码是没有违反DRY的,但是上面的代码是不是会存在其他方面的问题呢?
仔细分析一下login()函数的执行流程你就会发现,在整个login()执行完成之后,EmailValidation.validate()一共被执行了两次,一次是在调用 checkIfUserExisted() 函数的时候,另一次是调用 getUserByEmail() 函数的时候。这个问题解决起来比较简单,我们只需要将校验逻辑从 UserRepo 中移除,统一放到 UserService 中就可以了。
除此之外,代码中还有一处比较隐蔽的执行重复,不知道你发现了没有?实际上,login() 函数并不需要调用 checkIfUserExisted() 函数,只需要调用一次 getUserByEmail() 函数,从数据库中获取到用户的 email、password 等信息,然后跟用户输入的 email、password 信息做对比,依次判断是否登录成功。
实际上,这样的优化是很有必要的。因为如果 checkIfUserExisted() 函数和 getUserByEmail() 函数都需要查询数据库,而数据库这类的 I/O 操作是比较耗时的。我们在写代码的时候,应当尽量减少这类 I/O 操作。
按照刚刚的修改思路,我们把代码重构一下,移除“重复执行”的代码,只校验一次 email 和 password,并且只查询一次数据库。重构之后的代码如下所示:
public class UserService {
private UserRepo userRepo;//通过依赖注入或者IOC框架注入
public User login(String email, String password) {
if (!EmailValidation.validate(email)) {
// ... throw InvalidEmailException...
}
if (!PasswordValidation.validate(password)) {
// ... throw InvalidPasswordException...
}
User user = userRepo.getUserByEmail(email);
if (user == null || !password.equals(user.getPassword()) {
// ... throw AuthenticationFailureException...
}
return user;
}
}
public class UserRepo {
public boolean checkIfUserExisted(String email, String password) {
//...query db to check if email&password exists
}
public User getUserByEmail(String email) {
//...query db to get user by email...
}
}
对于这种代码重复执行的情况,其实是很难完全避免的。一个比较好的方式是我们在设计代码的时候,将基础的校验、查询等动作封装成单独的函数,只在对外暴露的方法中执行这些动作,而对于不对外暴露的模块内部的方法和函数,我们要充分相信自己代码的上下文,保证在调用到模块内部方法的时候,数据的状态,基本的上下文是正确和完整的。
代码可复用性和DRY原则
在《什么是代码质量》一文中我们曾提到过,代码的可复用性是评判代码质量的一个重要指标。当我们提到DRY原则的时候其实也很容易联想到代码的可复用性。在我们代码的可复用性足够好的情况下,我们的代码会更加容易满足DRY原则。这里,我们借着介绍DRY原则的机会对代码的可复用性进行一个更加深入的介绍。
这里我们首先要区分三个概念:代码复用性(Code Reusability)、代码复用(Code Resue)和DRY原则。
首先,**“不重复”并不代表“可复用”。**在一个项目的代码中,可能不存在任何重复的代码,但是这并不代表着项目中的代码都是可复用的。不重复和可复用完全是两个概念。所以,从这个角度来讲,DRY原则和代码的可复用性是两回事。
其次,**“复用”和“可复用性”关注角度不同。**代码的可复用性是从代码的开发者来讲的,复用是从代码的使用者角度来讲的。比如,A 同事编写了一个 UrlUtils 类,代码的“可复用性”很好。B 同事在开发新功能的时候,直接“复用”A 同事编写的 UrlUtils 类。“复用”这个概念不仅可以指导细粒度的模块、类、函数的设计开发,实际上,一些框架、类库、组件等的产生也都是为了达到复用的目的。比如,Spring 框架、Google Guava 类库、UI 组件等等。
尽管复用、可复用性、DRY 原则这三者从理解上有所区别,但是它们之间的内在联系是非常紧密的。因为代码的“可复用性”高了,我们在开发的新的功能的时候,就可以更多的“复用”现有的代码,这可以有效减少代码量,避免重复代码的出现,在更大程度上满足DRY原则。
如何提高代码的可复用性
我们要提高代码的可复用性,首先要明确的一点是:**提高代码可复用性的目的是对代码进行复用,而对代码进行复用的根本其实是对一系列现有细小知识点的重新组合应用。**就拿我们上面校验用户名和密码的例子来讲,把一系列对字符串的校验规则视为一个一个的细小知识点,再把这些校验规则封装成一个模块,那么我们在校验用户名和密码的时候就可以直接复用这一个一个的校验规则了,代码大体如下:
class StringCheckUtil {
/**
* 校验字符串的长度范围
* @return 如果满足条件返回null,否则返回错误信息
*/
public static boolean checkLength(String source, int min, int max) {
return true;
}
/**
* 是否只包含小写字母
* @return 如果满足条件返回null,否则返回错误信息
*/
public static boolean onlyLowercase(String source) {
return true;
}
/**
* 是否只包含 a~z、0~9、dot
* @return 如果满足条件返回null,否则返回错误信息
*/
public static boolean onlyContainsCharAndDot(String source) {
return true;
}
}
class UserAuthenticator {
public void authenticate(String username, String password) {
if (!isValidUsername(username)) {
// ...throw InvalidUsernameException...
}
if (!isValidPassword(password)) {
// ...throw InvalidPasswordException...
}
//...省略其他代码...
}
private boolean isValidUsername(String username) {
// check length: 4~64
if (!StringCheckUtil.checkLength(username, 4, 64)) {
return false;
}
// contains only lowcase characters
if (!StringCheckUtil.onlyLowercase(username)) {
return false;
}
// contains only a~z,0~9,dot
if (!StringCheckUtil.onlyContainsCharAndDot(username)) {
return false;
}
return true;
}
private boolean isValidPassword(String password) {
// check length: 4~64
if (!StringCheckUtil.checkLength(password, 4, 64)) {
return false;
}
// contains only lowcase characters
if (!StringCheckUtil.onlyLowercase(password)) {
return false;
}
// contains only a~z,0~9,dot
if (!StringCheckUtil.onlyContainsCharAndDot(password)) {
return false;
}
return true;
}
}
虽然我们在实际编码实现这样的校验的时候,很少这么写,在这种情况下使用正则表达式可能是更好的选择,但是这个用户名和密码校验的例子放在这里却有很好的说明意义。
从上面的例子其实我们不难看出,想要提高代码的可复用性,最基本的还是对关注点分离了单一职责的落实。如果我们的每一个知识点都有唯一明确且权威的表示,如果在我们编写新功能的时候需要新的小知识点,那么就在原有的基础上,找到适合存放这个知识点的模块,把这个新知识点加入其中,剩下的工作就是对这些细小知识点的组合应用了,这样代码的复用就是一件自然而然的事情了。
这么描述可能还是过于抽象了,那么我们在编码的时候有什么具体的措施可以提高我们代码的复用性么?我总结了以下几点:
-
编码规范
每个人的编码习惯可能都是不同的,但是现在的编码工作却往往不是一个人能够单独完成的,复杂软件的编写需要依赖的是一个团队,而这个团队最好具有统一的编码规范,比如如何命名、如何划分模块等等。规范存在的目的是让团队内的成员养成同样的习惯,当大家都遵循同样的规范的时候,我们依靠类、方法、变量等程序实体的签名在很大程度上就能够识别出系统中现有的知识点,避免不同的成员对同一个知识点进行重复描述。
-
减少代码耦合
对于高度耦合的代码,当我们希望复用其中的一个功能,想把这个功能的代码抽取出来成为一个独立的模块、类或者函数的时候,往往会发现牵一发而动全身。移动一点代码,就要牵连到很多其他相关的代码。所以,高度耦合的代码会影响到代码的复用性,我们要尽量减少代码耦合。
-
满足单一职责原则
我们前面讲过,如果职责不够单一,模块、类设计得大而全,那依赖它的代码或者它依赖的代码就会比较多,而且依赖关系可能变得错综复杂,这就会使得模块间的耦合变得不健康。根据上一点,也就会影响到代码的复用性。相反,越细粒度的代码,代码的通用性会越好,越容易被复用。
-
模块化
这里的“模块”,不单单指一组类构成的模块,还可以理解为单个类、函数。我们要善于将功能独立的代码,封装成模块。独立的模块就像一块一块的积木,更加容易复用,可以直接拿来搭建更加复杂的系统。
-
业务与非业务逻辑分离
越是跟业务无关的代码越是容易复用,越是针对特定业务的代码越难复用。所以,为了复用跟业务无关的代码,我们将业务和非业务逻辑代码分离,抽取成一些通用的框架、类库、组件等。
-
通用代码下沉
从分层的角度来看,越底层的代码越通用、会被越多的模块调用,越应该设计得足够可复用。一般情况下,在代码分层之后,为了避免交叉调用导致调用关系混乱,我们只允许上层代码调用下层代码及同层代码之间的调用,杜绝下层代码调用上层代码。所以,通用的代码我们尽量下沉到更下层。
除了刚刚我们讲到的几点,还有一些跟编程语言相关的特性,也能提高代码的复用性,比如泛型编程。如果我们使用的是支持面向对象编程范式的语言,那么我们还可以使用面向对象的一些手段来提高代码的可复用性:
-
抽象、封装、继承、多态
利用继承,可以将公共的代码抽取到父类,子类复用父类的属性和方法。利用多态,我们可以动态地替换一段代码的部分逻辑,让这段代码可复用。除此之外,抽象和封装,从更加广义的层面、而非狭义的面向对象特性的层面来理解的话,越抽象、越不依赖具体的实现,越容易复用。代码封装成模块,隐藏可变的细节、暴露不变的接口,就越容易复用。
-
应用模板方法等设计模式
一些面向对象设计模式,也能提高代码的复用性。比如,模板模式利用了多态来实现,可以灵活地替换其中的部分代码,整个流程模板代码可复用。当关于应用设计模式提高代码复用性这一部分,我们留在后面慢慢来讲解。当然,设计模式并不是面向对象特有的,甚至有一些模式是针对特定语言的,这一点我们在后面的文章中也会有所介绍。
实际上,除了上面讲到的这些方法之外,复用意识也非常重要。在写代码的时候,我们要多去思考一下,这个部分代码是否可以抽取出来,作为一个独立的模块、类或者函数供多处使用。在设计每个模块、类、函数的时候,要像设计一个外部 API 那样,去思考它的复用性。
总结
这篇文章中,我们介绍了一个非常重要且基础的设计原则——DRY原则,其核心思想是**每一个知识点都应该有一个唯一的、明确的、权威的表示。**同时我们也说明了三种典型的代码重复的场景:实现逻辑重复、功能语义重复和代码执行重复。在这三种代码重复的场景中,只有功能语义重复是直接违反DRY的,但是其他的重复虽然没有违反DRY,但是也存在它们的问题。
同时,这篇文章中我们也介绍了代码的可复用性,提高代码的可复用性可以更好地落实DRY原则。
以上就是我对DRY原则和代码可复用性的基本理解。本人深知自己技术水平和表达能力有限,文章中一定存在不足和错误,欢迎与我进行交流(laomst@163.com),跟我一起讨论,修改文中的不足和错误,感谢您的阅读。
参考资料
[1]王争.设计模式之美[M].北京:人民邮电出版社,2022.6:104-110.


















 1637
1637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











