







简介:本书为程序员和系统管理员提供了一套全面的Linux程序开发指南,涵盖了从命令行基础到系统调用和库函数的高级用法。书中详细介绍了Linux命令行工具的使用、文本处理工具如grep、sed、awk的应用,以及核心系统调用如open、read、write等的具体操作。此外,还讨论了信号处理、线程和内存管理等编程要素,并深入探讨了C语言及其标准库的使用,以及C++和Linux特定函数库如glibc、GTK+和Qt。本资源列表可作为学习平台,提供额外的学习支持和最新的技术动态,帮助读者全面提升Linux编程技能。 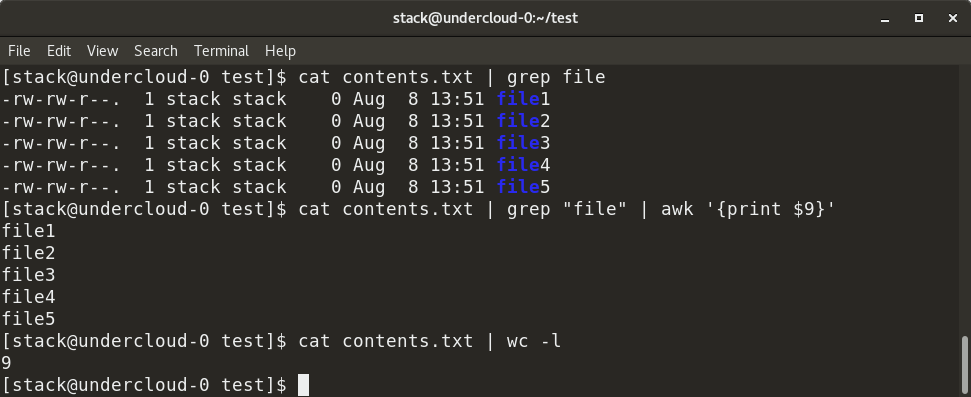
1. Linux编程白皮书概述
Linux作为开放源代码的操作系统,其在企业级和嵌入式系统中的广泛采用,为程序员提供了丰富的编程机会。本白皮书将带你从基础到深入,全面掌握Linux下的编程技巧与工具使用。在开始之前,我们将简要介绍Linux编程的背景、重要性以及本白皮书的结构和内容深度。此外,还会概述Linux编程的学习路径和一些必要的预备知识,为读者构建一个系统化和实用的学习蓝图。准备好了吗?让我们开启Linux编程之旅,挖掘其丰富的生态与潜能。
2. Linux基础命令行操作
2.1 命令行基础知识
2.1.1 shell的基本概念和种类
在Linux系统中,shell充当用户与操作系统之间的接口。它是一个命令解释器,负责解释用户的输入并将其转换为操作系统可以理解和执行的命令。shell的基本功能包括文件系统导航、程序执行以及输入/输出重定向。
shell有许多不同的种类,常见的如bash(Bourne Again SHell)、csh(C Shell)、zsh(Z Shell)等。每种shell都有其独特的特性和命令语法,但大多数Linux发行版默认使用bash。bash的普及是因为它的兼容性好,功能强大,还具备脚本编程能力。
2.1.2 文件系统结构与路径导航
Linux的文件系统是一个层次化的结构,以根目录(/)开始,之后再分出多个子目录。以下是一些常见的目录及其功能:
-
/bin:基本的用户命令和程序。 -
/etc:配置文件的存放地。 -
/home:用户主目录。 -
/lib:系统库文件。 -
/proc:系统和进程信息文件。 -
/tmp:临时文件存储目录。 -
/usr:用户程序和数据。 -
/var:经常变化的文件,如日志文件。
路径导航是通过使用各种命令来完成的,如 cd (更改目录)、 pwd (显示当前工作目录路径)。
2.2 常用命令行工具的使用
2.2.1 文件和目录操作命令
文件和目录操作是日常管理中不可或缺的一部分,以下是一些常用的命令及其用途:
-
ls:列出目录内容。例如,ls -l命令以长格式列出详细信息。 -
cp:复制文件或目录。例如,cp source.txt target.txt复制文件。 -
mv:移动或重命名文件。例如,mv oldname.txt newname.txt将文件重命名。 -
rm:删除文件或目录。例如,rm -r directoryname删除目录及其内容。 -
mkdir:创建新目录。例如,mkdir newdir创建一个新目录。 -
rmdir:删除空目录。例如,rmdir emptydir删除一个空目录。
2.2.2 文本处理与搜索命令
文本处理和搜索命令对于处理日志文件和配置文件等非常有用,以下是一些常用的文本处理命令:
-
cat:显示文件内容到标准输出,可以合并多个文件的内容。 -
head:显示文件的前几行,例如,head -n 5 filename显示前5行。 -
tail:显示文件的最后几行,例如,tail -f filename可以实时追踪文件内容。 -
grep:搜索文本,使用正则表达式来查找匹配的字符串。 -
find:在指定目录下查找文件,并对找到的文件执行操作。
2.2.3 权限设置与用户管理
权限设置和用户管理确保了Linux系统中的安全性和数据保护,以下是一些相关的命令:
-
chmod:改变文件或目录的权限。例如,chmod 755 filename给予所有者读写执行权限,给予组和其他用户读执行权限。 -
chown:改变文件或目录的所有者。例如,chown newowner filename将文件的所有者改为newowner。 -
useradd:添加新的用户账户。例如,useradd -m username添加一个新用户,并创建用户主目录。 -
passwd:设置或更改用户密码。例如,passwd username可以更改指定用户的密码。 -
groupadd:创建新的用户组。例如,groupadd newgroup创建一个新组。
在实际操作中,这些命令的组合使用可以实现复杂的数据管理和系统维护任务。对于Linux系统管理员来说,熟练使用这些命令是日常工作的基础。
3. 文本处理工具的高级应用
文本处理是Linux系统中非常重要的一个方面,它涉及到数据的提取、转换和处理等多个环节。本章将深入探讨grep和sed/awk这些强大的文本处理工具,让读者能够通过实际案例学习到如何高效地处理和分析文本数据。
3.1 grep的深入解析
grep是一个用于模式匹配的工具,能够对文本进行搜索并输出匹配的行。它广泛应用于日志文件的分析、代码审查以及其他需要文本搜索的场景。
3.1.1 正则表达式与模式匹配
正则表达式是文本处理的基石。它允许用户定义复杂的文本匹配规则,以便在数据中进行搜索。在Linux中,grep支持多种正则表达式的方言,其中扩展正则表达式(grep -E)是最常用的,它包括了更多的元字符和操作符。
一个基本的正则表达式例子如下:
grep 'error' filename.log
上面的命令将搜索文件 filename.log 中包含"error"文本的所有行。这里,"error"就是一个简单的正则表达式。
而更复杂的正则表达式可能包含多个部分,并使用如下的特殊字符:
-
.:任意单个字符 -
*:零个或多个前一个字符 -
[]:字符集,例如[abc]匹配任一字符a、b或c -
|:或操作,例如cat|dog匹配"cat"或"dog" -
():分组,用于组合表达式,并可以应用于后向引用
3.1.2 高级选项和自定义脚本
grep提供了许多选项来定制搜索行为,例如:
-
-i:忽略大小写 -
-v:反向匹配,只显示不匹配的行 -
-r:递归搜索目录下的所有文件 -
-n:显示匹配行的行号
这些选项可以根据需要组合使用,为文本分析提供了极大的灵活性。此外,通过与shell脚本或工具的结合,用户可以创建复杂的文本处理工作流。
grep -rn 'error' /var/log/ 2>/dev/null
此例中, -r 表示递归搜索整个 /var/log 目录; -n 表示显示匹配行的行号; 2>/dev/null 则将错误信息重定向到null设备,通常用于忽略权限错误等提示信息。
3.2 sed与awk的力量
sed和awk是Linux文本处理中极具力量的工具。它们都是流编辑器,可以对输入的文本流进行过滤和转换。
3.2.1 流编辑器sed的原理与实践
sed(stream editor)能够对输入的文本进行脚本化的编辑。它的工作方式是读取输入流(通常是文件或者标准输入),然后根据提供的脚本命令对这些文本进行处理,最后输出处理结果。
sed的基本命令格式如下:
sed [选项] '命令' [输入文件]
其中,一个简单的命令示例如下:
sed 's/error/recovered/g' filename.log
这个命令将会把文件 filename.log 中的"error"替换成"recovered"。
sed的高级用法还包括:
- 多条命令:
sed -e 's/error/recovered/g' -e 's/warning/caution/g' filename.log - 范围指定:
sed '/error/,/success/ s/error/recovered/g' filename.log - 删除行:
sed '/error/d' filename.log
3.2.2 编程式文本处理工具awk的精髓
awk是一个非常强大的编程语言,专门用于模式扫描和处理。它将输入视为记录和字段,允许复杂的文本处理和报告。
awk的基本命令格式如下:
awk '模式 {动作}' 输入文件
模式通常是正则表达式,而动作是用大括号括起来的一系列awk语句。
一个简单的awk示例:
awk '/error/ {print $0}' filename.log
该命令打印 filename.log 文件中含有"error"的所有行。这里 $0 代表当前行的全部内容。
awk的高级特性包括:
- 内置变量:如
NR表示当前处理的是第几条记录,NF表示当前记录的字段数。 - 函数:如
split()用于字段分割,substr()用于字符串截取。 - 条件语句和循环语句:允许执行更复杂的逻辑。
3.2.3 实际案例分析:文本数据的处理与转换
下面将通过一个实际案例展示如何使用sed和awk处理和转换文本数据。
假设我们需要处理一个由多个传感器生成的日志文件,该文件的格式如下:
2023-03-15 11:01:10, temperature: 23.4, humidity: 54
2023-03-15 11:02:10, temperature: 22.1, humidity: 55
2023-03-15 11:03:10, temperature: 24.5, humidity: 53
我们希望提取并计算每分钟的平均温度。首先,可以使用sed提取温度字段:
sed 's/.*temperature: //; s/,.*//' logfile.txt
该命令将输出:
**.*
**.*
**.*
然后,我们可以使用awk计算平均值:
awk '{total += $1; count++;} END {print total/count;}' temperature.log
该命令将计算出所有行温度值的平均数。
通过组合使用sed和awk,我们有效地转换和分析了原始的日志数据,得到了我们想要的统计结果。这展示了文本处理工具在数据处理和分析中的强大能力。
graph LR
A[原始日志文件] -->|使用sed提取温度| B[提取的温度值]
B -->|使用awk计算平均值| C[平均温度结果]
在上图中,我们可视化了数据处理的流程,从原始日志文件开始,通过两个步骤得到了最终结果,这个过程体现了sed和awk在处理文本数据中的应用价值。
以上内容仅为本章的节选,完整章节将包含更多关于文本处理工具的深入介绍和实用案例。
4. Linux系统调用与核心操作
4.1 系统调用的原理与应用
4.1.1 open、read、write系统调用详解
系统调用是操作系统内核提供的接口,允许应用程序访问硬件资源和服务。在Linux系统中,open、read、write系统调用是最基础的文件操作接口,它们允许程序打开文件、读取内容以及写入数据。
#include <fcntl.h> /* For O_* constants */
#include <sys/stat.h> /* For mode constants */
#include <unistd.h>
#include <stdio.h>
int main() {
int fd = open("example.txt", O_RDONLY); // 打开文件
if (fd == -1) {
perror("open");
return -1;
}
char buffer[1024];
ssize_t bytes_read = read(fd, buffer, sizeof(buffer)); // 读取数据
if (bytes_read == -1) {
perror("read");
close(fd);
return -1;
}
printf("Read %ld bytes: %s\n", bytes_read, buffer);
ssize_t bytes_written = write(STDOUT_FILENO, buffer, bytes_read); // 写入数据到标准输出
if (bytes_written == -1) {
perror("write");
close(fd);
return -1;
}
close(fd); // 关闭文件描述符
return 0;
}
在上述代码中,首先通过 open 函数以只读模式打开一个名为 example.txt 的文件,然后使用 read 函数从文件中读取内容到缓冲区 buffer 。读取成功后,使用 write 函数将读取的内容写入到标准输出。最后关闭文件描述符。
参数说明: - fd :文件描述符,是一个非负整数,用于标识打开的文件。 - buffer :内存缓冲区,用于存储读取或准备写入的数据。 - bytes_read 和 bytes_written :分别表示成功读取和写入的字节数。
逻辑分析: - open :函数用于打开文件,根据返回的文件描述符,可以对文件进行读写操作。 - read :函数用于从文件描述符指向的文件中读取数据。 - write :函数用于向文件描述符指向的文件或设备写入数据。
4.1.2 其他重要系统调用的介绍
除了基本的文件操作之外,Linux系统提供了大量其他重要的系统调用,例如 fork 用于创建进程, exec 用于执行新的程序, wait 用于等待子进程结束, signal 用于处理信号,以及 socket 用于网络通信。
例如,创建一个新的进程可以通过以下代码:
#include <unistd.h>
int main() {
pid_t pid = fork(); // 创建子进程
if (pid == -1) {
perror("fork");
return -1;
}
if (pid == 0) {
// 子进程中
execlp("/bin/ls", "ls", NULL);
// 注意:execlp执行失败后不会返回
} else {
// 父进程中
wait(NULL); // 等待子进程结束
}
return 0;
}
上述代码展示了如何使用 fork 创建一个新的子进程,并通过 wait 系统调用等待子进程的结束。在子进程中,使用 execlp 替换当前进程的映像为 /bin/ls ,执行列出当前目录内容的命令。
4.2 文件系统操作与进程管理
4.2.1 文件的创建、读写、删除与属性管理
文件的创建、读写、删除以及属性管理是Linux系统中基本且频繁的操作。在C语言中,这些操作可以通过 touch 、 write 、 unlink 、 chmod 等系统调用来实现。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/stat.h>
int main() {
// 创建新文件
if (touch("newfile.txt") == -1) {
perror("touch");
return -1;
}
// 写入数据到文件
FILE *file = fopen("newfile.txt", "w");
if (file == NULL) {
perror("fopen");
unlink("newfile.txt"); // 删除创建失败的文件
return -1;
}
fprintf(file, "Hello, world!");
fclose(file);
// 更改文件属性为只读
if (chmod("newfile.txt", S_IRUSR | S_IRGRP | S_IROTH) == -1) {
perror("chmod");
unlink("newfile.txt");
return -1;
}
// 删除文件
if (unlink("newfile.txt") == -1) {
perror("unlink");
return -1;
}
return 0;
}
在上述代码中,首先使用 touch 创建一个名为 newfile.txt 的新文件,然后使用标准的C库函数 fopen 和 fclose 对文件进行读写操作。通过 chmod 更改文件属性,使其成为只读文件。最后,通过 unlink 删除文件。
4.2.2 进程的创建、调度与控制
进程管理涉及创建新进程、终止进程以及进程间的通信。 fork 系统调用在第四节中已经讨论过,它是创建新进程的关键。
进程间的通信可以通过管道( pipe )、信号量( semget 、 semop )、共享内存( shmget 、 shmat )等多种方式实现。
例如,下面的代码展示了如何创建一个管道:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main() {
int pipefd[2]; // 创建一个管道
if (pipe(pipefd) == -1) {
perror("pipe");
return -1;
}
pid_t pid = fork();
if (pid == -1) {
perror("fork");
return -1;
}
if (pid == 0) {
// 子进程中
close(pipefd[1]); // 关闭写端
char buf;
while (read(pipefd[0], &buf, 1) > 0) {
write(STDOUT_FILENO, &buf, 1);
}
write(STDOUT_FILENO, "\n", 1);
close(pipefd[0]); // 关闭读端
_exit(EXIT_SUCCESS);
} else {
// 父进程中
close(pipefd[0]); // 关闭读端
write(pipefd[1], "Hello, world!", 13);
close(pipefd[1]); // 关闭写端
wait(NULL); // 等待子进程结束
}
return 0;
}
在该示例中,父进程创建了一个管道,并通过 fork 创建子进程。子进程关闭写端,从管道的读端读取数据,并将数据写入标准输出。父进程关闭读端,向管道的写端写入字符串"Hello, world!",然后关闭写端并等待子进程结束。
4.3 网络通信的实现机制
4.3.1 套接字编程基础
Linux系统中的套接字(Socket)编程是实现网络通信的基础。它允许程序之间通过互联网进行数据交换。
套接字编程分为几个步骤:
- 创建套接字:使用
socket系统调用。 - 绑定地址:使用
bind系统调用。 - 监听连接:使用
listen系统调用。 - 接受连接:使用
accept系统调用。 - 发送和接收数据:使用
send和recv系统调用。
例如,下面的代码展示了如何创建一个TCP服务器:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <netinet/in.h>
#define PORT 8080
int main() {
int server_fd, new_socket;
struct sockaddr_in address;
int addrlen = sizeof(address);
char buffer[1024] = {0};
char *hello = "Hello from server";
// 创建套接字
if ((server_fd = socket(AF_INET, SOCK_STREAM, 0)) == 0) {
perror("socket failed");
exit(EXIT_FAILURE);
}
// 绑定套接字到端口8080
address.sin_family = AF_INET;
address.sin_addr.s_addr = INADDR_ANY;
address.sin_port = htons(PORT);
if (bind(server_fd, (struct sockaddr *)&address, sizeof(address))<0) {
perror("bind failed");
exit(EXIT_FAILURE);
}
// 监听套接字
if (listen(server_fd, 3) < 0) {
perror("listen");
exit(EXIT_FAILURE);
}
// 接受客户端连接
if ((new_socket = accept(server_fd, (struct sockaddr *)&address, (socklen_t*)&addrlen))<0) {
perror("accept");
exit(EXIT_FAILURE);
}
// 读取客户端发送的数据
read(new_socket, buffer, 1024);
printf("Message from client: %s\n", buffer);
// 向客户端发送数据
send(new_socket, hello, strlen(hello), 0);
printf("Hello message sent\n");
// 关闭套接字
close(new_socket);
close(server_fd);
return 0;
}
在该代码中,服务器监听在端口8080上,接受一个客户端的连接,并读取客户端发送的消息。之后,服务器向客户端发送一条欢迎消息,并关闭连接。
4.3.2 网络服务端与客户端编程示例
除了服务器端编程之外,还需要编写客户端代码以连接服务器并进行通信。下面是一个简单的TCP客户端示例:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#define PORT 8080
int main() {
struct sockaddr_in serv_addr;
char *hello = "Hello from client";
char buffer[1024] = {0};
int sock = 0;
if ((sock = socket(AF_INET, SOCK_STREAM, 0)) < 0) {
printf("\n Socket creation error \n");
return -1;
}
serv_addr.sin_family = AF_INET;
serv_addr.sin_port = htons(PORT);
// 将IPv4和IPv6地址从文本转换为二进制形式
if(inet_pton(AF_INET, "***.*.*.*", &serv_addr.sin_addr)<=0) {
printf("\nInvalid address/ Address not supported \n");
return -1;
}
// 连接到服务器
if (connect(sock, (struct sockaddr *)&serv_addr, sizeof(serv_addr)) < 0) {
printf("\nConnection Failed \n");
return -1;
}
// 发送数据
send(sock, hello, strlen(hello), 0);
printf("Hello message sent\n");
// 读取服务器回复的数据
read(sock, buffer, 1024);
printf("Message from server: %s\n", buffer);
// 关闭套接字
close(sock);
return 0;
}
在客户端代码中,首先创建套接字,然后建立与服务器的连接。之后,客户端发送消息给服务器,并接收服务器的回复。最后,关闭套接字。
这些示例展示了如何使用Linux提供的系统调用来进行基本的网络编程,从而在不同的应用程序之间实现数据交换。网络编程是许多高级应用场景(如Web服务、数据库通信、远程过程调用等)的基础,理解和掌握这些基础对于设计和开发可扩展、健壮的网络应用至关重要。
5. 高级编程概念与实践
5.1 信号处理与线程编程
在现代操作系统中,信号和线程是构建复杂应用程序的基础。本章节将深入探讨Linux环境下的信号处理机制和POSIX线程(pthread)的使用。
5.1.1 信号的概念、类型与应用
信号是软件中断,用于通知进程发生了某个事件。系统提供了多种信号,允许进程响应不同的事件。例如, SIGINT 表示由用户输入的中断信号,通常由Ctrl+C产生。
信号处理通常涉及以下几个方面:
- 发送信号:可以通过
kill命令或者进程间通信机制向目标进程发送信号。 - 捕获信号:通过设置信号处理函数来捕获信号。
- 默认行为:如果未捕获信号,则系统会执行默认行为,比如终止进程。
信号处理函数的设置示例如下:
#include <signal.h>
#include <stdio.h>
#include <unistd.h>
void handle_signal(int sig) {
printf("Received signal: %d\n", sig);
// 恢复默认行为
signal(sig, SIG_DFL);
// 发送信号给自己以执行默认行为
kill(getpid(), sig);
}
int main() {
// 设置SIGINT的处理函数
signal(SIGINT, handle_signal);
while(1) {
pause(); // 等待信号
}
return 0;
}
5.1.2 POSIX线程(pthread)的使用与管理
POSIX线程库(pthread)提供了一种创建和管理线程的机制。线程是进程中的执行流,允许并发执行。
创建线程的代码示例如下:
#include <pthread.h>
#include <stdio.h>
// 线程函数
void *thread_function(void *arg) {
printf("Hello from the thread!\n");
return NULL;
}
int main() {
pthread_t thread_id;
// 创建线程
if (pthread_create(&thread_id, NULL, thread_function, NULL) != 0) {
perror("Failed to create thread");
return 1;
}
// 等待线程结束
pthread_join(thread_id, NULL);
printf("Thread joined\n");
return 0;
}
使用pthread时,常常需要考虑线程同步和互斥问题。互斥锁(mutexes)和条件变量(condition variables)是常见的同步机制。
5.2 内存管理与优化策略
高效管理内存是编写高性能应用程序的关键。本小节将讨论动态内存的分配与释放,以及内存泄漏检测和性能优化的策略。
5.2.1 动态内存分配与释放
C语言的动态内存管理依赖于 malloc() , calloc() , realloc() 和 free() 函数。正确管理动态内存是避免内存泄漏和指针悬挂的关键。
#include <stdlib.h>
#include <stdio.h>
int main() {
int *array = (int*)malloc(10 * sizeof(int));
if (array == NULL) {
perror("malloc failed");
return 1;
}
// 使用动态内存...
free(array); // 释放内存
return 0;
}
5.2.2 内存泄漏检测与性能优化
内存泄漏是指应用程序分配的内存在使用后未正确释放。这会导致内存使用不断增加,甚至耗尽系统资源。为了避免这种情况,开发者应使用内存泄漏检测工具,例如Valgrind。
性能优化方面,程序员可以使用内存池来减少动态内存分配的开销,或者使用jemalloc这类高效的内存分配库。
内存泄漏示例:
void memory_leak() {
int *ptr = malloc(sizeof(int)); // 分配内存但未释放
// 代码继续执行...
}
以上代码中,内存泄漏发生于 ptr 分配内存后没有被释放。在实际应用中,应当通过适当的清理逻辑来避免这种情况。
6. C/C++语言在Linux下的编程技巧
6.1 C语言标准库函数的应用
6.1.1 标准输入输出函数的深入
C语言的标准输入输出函数在Linux编程中扮演着至关重要的角色,它们是与用户交互和数据处理的桥梁。 printf 和 scanf 是我们最常用的两个函数,但是深入理解它们的使用细节可以更有效地进行编程。
- printf的格式化输出:
printf函数支持多种格式化指定符,这使得程序员能够灵活地控制输出格式。例如,%d用于输出整数,%f用于浮点数,%s用于字符串。此外,还可以指定输出宽度、对齐方式和精度等参数。
c printf("%-10d%5.2f\n", number, value); 上述代码将整数输出为左对齐,并占用10个字符宽度,浮点数输出为5个字符宽度,其中包含两位小数。 - 表示左对齐。
- scanf的格式化输入:
scanf函数用于从标准输入读取格式化的数据。它同样使用与printf相似的格式化指定符来解析输入。
c int a; float b; scanf("%d %f", &a, &b); 在上述代码中, scanf 将会等待用户输入两个由空格分隔的值,并分别赋值给整型变量 a 和浮点型变量 b 。
6.1.2 动态内存管理与调试技巧
C语言在Linux平台下提供了动态内存分配和释放的功能,这些功能是通过 malloc 、 calloc 、 realloc 和 free 这几个函数实现的。正确使用动态内存管理,对于程序的稳定性和性能至关重要。
- 动态内存分配函数:
malloc函数用于分配指定字节大小的内存块,返回一个指向它的指针,如果分配失败则返回NULL。c int *ptr = (int*)malloc(sizeof(int)); if (ptr == NULL) { // 内存分配失败处理 }calloc与malloc类似,但它会将内存中的每个字节初始化为零。
realloc 函数用于重新分配先前通过 malloc 或 calloc 分配的内存块。这在需要改变之前分配的内存大小时非常有用。
- 内存释放与调试: 动态分配的内存在使用完毕后必须通过
free函数显式释放,否则会造成内存泄漏。
c free(ptr);
使用诸如 valgrind 这样的工具可以帮助检测和调试内存泄漏。在编译时加入 -g 选项,可以使程序包含调试信息,便于后续的内存问题分析。
sh gcc -g -o my_program my_program.c valgrind --leak-check=full ./my_program
6.2 C++语言及其标准模板库(STL)
6.2.1 面向对象编程与STL的结合
C++语言与C语言最大的不同在于其支持面向对象编程(OOP)的特性。类、对象、继承、多态等概念,使得C++在构建复杂系统时更加得心应手。同时,C++标准模板库(STL)提供了一系列可重用的数据结构和算法,大幅度提高了开发效率。
- STL容器的使用: STL提供多种容器,如
vector、list、map等。vector是动态数组,适用于元素数量动态变化的情况。
cpp std::vector<int> vec; vec.push_back(10); vec.push_back(20);
- STL算法的利用: STL中的算法提供了丰富的函数式操作,可以轻松地对容器中的数据进行操作,如排序、查找、遍历等。
cpp std::sort(vec.begin(), vec.end());
6.2.2 高级特性如异常处理、智能指针
C++提供了异常处理机制,允许程序在出现错误时进行优雅的错误处理。使用 try , catch , throw 关键字,可以捕获和处理程序运行时可能出现的异常。
- 异常处理的使用:
cpp try { // 可能抛出异常的代码 } catch (const std::exception& e) { // 异常处理代码 }
智能指针(如 std::unique_ptr , std::shared_ptr )是C++11引入的特性,它们帮助自动管理动态分配的对象的生命周期,避免内存泄漏。
- 智能指针的使用:
cpp std::unique_ptr<int> ptr = std::make_unique<int>(42);使用智能指针,当指针对象生命周期结束时,分配的资源会自动释放,无需手动delete。
在本章节的介绍中,我们了解到C/C++语言在Linux环境下编程的一些核心技巧和高级特性。下一章节将探讨Linux下的专业函数库与资源,进一步拓展编程者的知识范围和技能深度。
7. Linux下的专业函数库与资源
在Linux环境下,丰富的函数库与资源能够帮助开发者提高开发效率,加强程序功能。本章将对Linux特定的专业函数库进行介绍,并提供相关的学习资源与认证信息。
7.1 Linux特定函数库介绍
Linux拥有众多第三方和官方支持的函数库,这些库能够简化编程任务,加速开发进程。本节重点介绍两个重要的库:glibc和图形界面库GTK+与Qt。
7.1.1 glibc库的使用与定制
glibc(GNU C Library)是Linux系统中最重要的C语言库之一。它是系统调用的用户空间接口,提供了POSIX和C标准所规定的所有函数。glibc库的定制和优化对于提升应用程序性能至关重要。
#include <stdio.h>
#include <stdlib.h>
int main() {
// 示例:使用malloc分配内存
int *p = (int*)malloc(sizeof(int) * 10);
if (p == NULL) {
perror("Unable to allocate memory");
exit(EXIT_FAILURE);
}
// 释放内存
free(p);
return 0;
}
在上例中,我们使用了 malloc 和 free 函数来分配和释放内存。这是glibc库提供的功能之一,是每个C语言开发者必须掌握的基础。
7.1.2 GTK+与Qt图形界面库的对比与选择
在Linux图形界面开发中,GTK+和Qt是两个主要的选择。GTK+主要由Gnome社区维护,而Qt由Nokia的子公司Trolltech开发。
GTK+优缺点:
- 优点:
- 跨平台
- 良好的本地化支持
- 开源和自由软件
- 缺点:
- 文档和教程相比Qt较少
Qt优缺点:
- 优点:
- 强大的跨平台支持
- 高质量的开发文档
- 丰富的组件和模块
- 缺点:
- 商业许可成本较高
#include <QApplication>
#include <QPushButton>
int main(int argc, char *argv[]) {
QApplication app(argc, argv);
QPushButton button("Hello, Qt!");
button.show();
return app.exec();
}
上例演示了一个简单的Qt应用程序,创建了一个窗口,并显示了一个按钮。
7.2 学习资源与认证信息
为了进一步提升Linux开发技能,学习资源和认证信息是不可或缺的。
7.2.1 在线课程、文档与社区资源
- 在线课程: 如Udemy、Coursera等平台提供的Linux相关课程,可系统学习Linux编程知识。
- 文档资源: 官方文档如Linux Documentation Project(LDP)提供了详尽的指南和手册。
- 社区资源: GitHub、Stack Overflow和Reddit等社区,提供了丰富的交流和讨论机会。
7.2.2 Linux相关认证的意义与准备
Linux认证,如RHCE(Red Hat Certified Engineer)和LPIC(Linux Professional Institute Certification),是衡量个人Linux技能水平的国际标准。
准备方法:
- 熟悉Linux基础命令和系统管理
- 实践系统配置和网络服务部署
- 参加在线教程、模拟考试和认证培训课程
# 示例:RHCE认证相关的模拟命令练习
sudo yum install httpd -y
sudo systemctl start httpd
sudo systemctl enable httpd
在本章中,我们了解了Linux下的专业函数库,包括glibc的使用、GTK+和Qt图形界面库的对比,以及如何选择适合自己的图形界面库。此外,本章也提供了丰富的学习资源和认证信息,帮助IT从业者进一步提升专业技能。接下来,我们将继续探索Linux编程世界的深奥知识。
简介:本书为程序员和系统管理员提供了一套全面的Linux程序开发指南,涵盖了从命令行基础到系统调用和库函数的高级用法。书中详细介绍了Linux命令行工具的使用、文本处理工具如grep、sed、awk的应用,以及核心系统调用如open、read、write等的具体操作。此外,还讨论了信号处理、线程和内存管理等编程要素,并深入探讨了C语言及其标准库的使用,以及C++和Linux特定函数库如glibc、GTK+和Qt。本资源列表可作为学习平台,提供额外的学习支持和最新的技术动态,帮助读者全面提升Linux编程技能。

















 163
163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









