







UTF-8和Unicode之间的关系
我们知道ASCII码主要是存储字母、个别符号的啊,最多有128位。也就是说,使用ASCII码可以表示最多128个基本符号。
如何用二进制来表示其他国家语言呢?如中文等
这就用到了Unicode。统一码(Unicode),也叫万国码、单一码、全球码,是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
我们常见的UTF-8是使用最广的Unicode编码方式。UTF-8将每个代码点映射到1-4个字节中。

图中说的Unicode码是啥呢?其实就是二进制码。下面举个例子:
汉字 --- 十六进制 --- 对应的二进制
'中' --- 4e2d --- 100111000101101
UTF-8中对十六进制的编码格式如下:
00-7F : 0xxxxxxx
80-7FF:110xxxxx 10xxxxxx
800-FFFF:1110xxxx 10xxxxxx 10xxxxxx
10000-10FFFF:11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
我们假设有字符 ‘中’ ,现需要知道它的utf-8编码
我们现在知道 ‘中’ 的十六进制为4E2D,那么属于800-FFFF范围。4E2D的二进制为100 1110 0010 1101。我们将其填充到1110xxxx 10xxxxxx 10xxxxxx 中的x里。得到11100100 10111000 10101101 -> 这个就是utf-8的编码,常见到utf-8给我们的是十六进制,你可以把这个二进制转为16进制就是了。
如何判断我们的计算对不对? 我们反推一下。已知utf-8编码11100100 10111000 10101101,求它原来的二进制?
根据上面的格式:我们知道是这样做的1110xxxx 10xxxxxx 10xxxxxx
那么我们将11100100 10111000 10101101和1110xxxx 10xxxxxx 10xxxxxx,把xxx拿出来就行了。 0100111000101101。
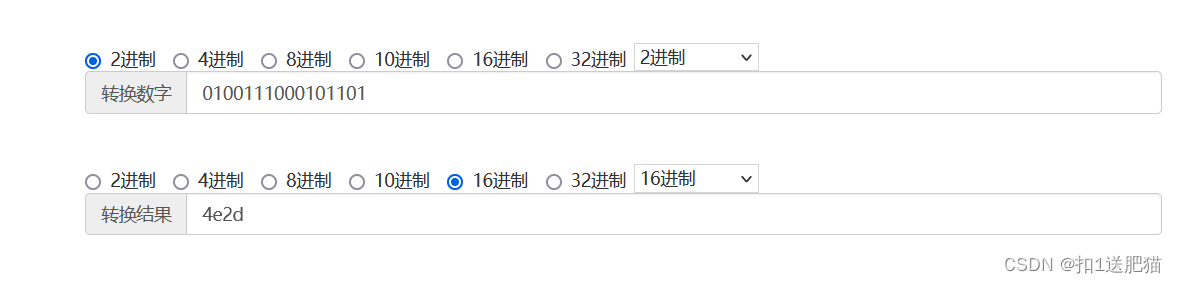
图 - 2进制转16进制














 1278
1278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









