






Abstract
受过大规模数据训练的深度网络可以学习可转移的特性,以促进学习多种任务。随着深度特征最终从一般到特定的深度网络的转换,一个根本的问题是如何利用不同任务之间的关系,并提高特定任务层的特性可转移性。本文提出了在深层卷积神经网络中,基于新颖的张量先验的深度关系网络(DRN),在多任务特定层的参数张量上发现任务关系。通过联合学习可转移的特性和任务关系,DRN能够缓解在特征层中负转移的困境和分类器层的低转移。广泛的实验表明,DRN在标准的多任务学习基准上产生了最先进的结果。
1 Introduction
受监督的学习者,在有限制的标签样本的情况下,容易过度拟合,而对新领域的充分训练数据的手工标注则是不可能的。因此,必须设计出降低标签成本的算法,通常是利用相关任务中现成的标签数据。多任务学习是基于这样一种观点,即一个任务的性能可以通过相关的任务作为归纳偏差[ 4 ]来改进。了解任务关系应该能够从相关的任务中转移共享知识,这样就只需要学习特定于任务的特征。这个基本思想激发了各种各样的方法,包括多任务特征学习,它学习了一个共享的特征表示[ 1 , 2 , 6 , 5 , 16 ]和多任务关系学习,它模拟了内在的任务关系[11, 18, 31, 32, 20, 22, 8]。
学习固有的任务关联性是一个难题,因为不同任务的训练数据可以从不同的分布中取样,并由不同的模型进行拟合。如果没有对任务相关性的先验知识,分布的变化可能会在不同任务之间传递知识的过程中遇到很大的困难。不幸的是,如果跨任务的知识转移是不可能的,那么由于标记数据的数量有限,我们将会对每个任务过拟合。解决这一难题的一种方法是使用外部数据源,例如ImageNet,来学习可转移的特性,通过这种特性,可以减少归纳偏差的变化,从而使不同的任务能够更有效地关联起来。这个想法激发了一些最新的深度学习方法用于学习多个任务 [ 28 , 26 , 29 , 7 ],这些方法可以在分类器层中学习共享表示,并在分类器层中学习多个独立分类器,但不需要推断任务关系。这可能导致分类器层的传输不足,因为知识不能跨不同的分类器传输。文献的最新发现表明,深层特征最终会在网络中从一般向特定的过渡,而随着任务差异的增加特征可转移性在更高的层次上显著下降[ 30 ],因此,所有特征层的共享可能有负转移的风险。因此,如何在不同任务之间利用任务关系,同时考虑到深层网络中特定任务层的特征可转移性,仍然是一个开放的问题。
本文提出了一种用于学习多任务的深层关系网络(DRN)结构,它发现了基于多个任务特定层的深层卷积神经网络的内在任务关系。首次对多任务学习的张量正态分布进行了探讨,并将其作为对所有任务特定层的网络参数的先验分布,以学习任务关系。通过联合学习可转移的特性和任务关系,DRN能够克服在特征层中负转移的困境和分类器层的低转移。由于深度模型预先训练了像ImageNet这样的大型数据库,它代表了通用感知任务 [ 12 , 30 , 17 ],DRN模型是通过在ImageNet[ 21 ]上预先训练的AlexNet模型进行微调训练的。实证研究表明,DRN学习了合理的任务关系,并在标准数据集上获得了最先进的性能。
3 Tensor Normal Distribution
3.1 Probability Density Function
张量正态分布是多元正态分布和矩阵-变量正态分布 [ 15 ]的自然延伸。多元正态分布是一阶的张量正态分布,而矩阵正态分布是二阶的张量正态分布。在定义张量正态分布之前,我们先介绍一下 K阶张量的符号和运算。一个K阶张量是K向量空间张量积的一个元素,每个向量空间都有自己的坐标系。一个向量是一个阶张量,维度是d 1。矩阵
是一个带有维数 (d 1 ,d 2 )的阶2阶张量。一个K阶张量
维数
元素
。X的矢量化是将张量展开成一个矢量,由vec(X)表示。X的矩阵化是向量化的泛化,把X的元素重新排列成一个矩阵。本文为了简化符号和描述张量的关系,我们使用 mode- n matricization,用X(n)表示 mode- n matricization张量X,X(n)的第i行包含X 中n-th索引等于i的所有的元素X。
考虑一个K阶张量。因为我们可以将X向向量化到一个向量
,所以张量X的正态分布可以被认为是一个多元正态分布在向量vec(X)的
维上的。然而,这样一个普通的多元分布忽略了X作为
张量的特殊结构,因此,元素X的协方差的特征大小为
这对于建模和估计通常是不可行的。为了探索X的结构,张量正态分布假设
协方差矩阵
可以被分解为 Kronecker product
并且X的元素的向量化遵循正态分布
这里是一个正定矩阵,表示
第k行的协方差矩阵,⊗是Kronecker product, M是一个和X相同大小的平均张量,包含X的每个元素的期望。由于分解协方差矩阵为Kronecker product,张量X的K阶正态分布有一个概率密度函数,以张量M和协方差矩阵 Σ 1 ,...,Σ K作为参数
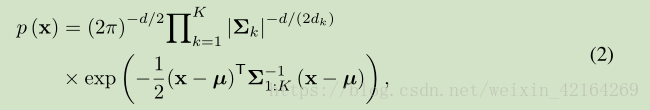
这里|.|是一个正方矩阵,µ=vec(M),
张量正态分布对应于Kronecker可分解的协方差张量的多元正态分布。X遵循张量正态分布(equivalently,vec(X)遵循正态分布与Kronecker分解协方差)
3.2 Maximum Likelihood Estimation
考虑一组n个样本每一个xi是由等式2张量正太分布生成的张量。平均张量M的极大似然估计(MLE)为

极大似然估计的协方差通过迭代求解系统计算:

该触发器算法通过简单的矩阵运算来求解,保证了收敛性。协方差矩阵是不可识别的,最大化密度(2)的解决方案不是唯一的,而只有Kronecker product将是可识别的。
4 Deep Relationship Networks
该工作通过联合学习可转移的特征和任务关系来建模多个任务。给定T任务,训练数据,其中
和
是第t个任务的N t 训练例子和相关标签,分别来自于D维特征空间和C-基数标签空间,也就是每一个训练例子
和
。我们的目标是构建一个深度网络,用于多个任务
,以学习可转移的特征和自适应任务关系,从而有效地、有力地连接不同的任务。
4.1 Model
我们从深度卷积神经网络(CNN)[ 21 ]开始,这是一个学习可转移特征的强大模型,它可以很好地适应多个任务[ 33 , 30 , 17 , 29 ]。主要的挑战是,在多任务学习中,每个任务都提供了有限数量的标签数据,这对于构建可靠的分类器是不够的。从这个意义上说,对任务关系进行建模是至关重要的,通过这种关系,如果他们是相关的每一对任务都可以互相帮助,如果它们是不相关的,他们可以保持独立来减少负转移。利用这一理念,我们设计了一种深度关系网络(DRN),它利用特性可转移性和任务关系来建立健壮的多任务学习。图1展示了所提出的DRN模型的结构。

提出的DRN模型建立在AlexNet[21]的基础上,它由卷积层( conv1 – conv5 ) 和全连接层 ( fc6 – fc8 )组成。第l个fc层学习任务t的一个非线性映射这里
是
的隐藏表示,
和
是权重和偏置参数,
是激活函数,认为隐藏层的激活函数为RELU输出层的激活函数为softmax
。定义第t个任务的CNN分类器
在
上的经验误差为
这里J是交叉熵损失,是分配
给标签
的条件概率。我们将不会描述如何计算卷积层,因为这些层可以学习可转移的特性 [ 30 ] ,我们将简单地在不同的任务中共享这些层的网络参数,而不需要显式地对这些层中的任务关系进行建模。为了从预训练和微调中获益,我们将这些层从在ImageNet 2012 [30, 19]上预训练的模型中复制,并对所有的conv1–conv5层进行微调。
根据最新的文献发现,标准CNNs的深层特征必须最终从一般到特定的网络转移,而特征的可转移性随着任务差异的增加而减少,使更高层的特征fc7 – fc8在不同的任务中不可安全地转移。换句话说,为原始目标量身订做的fc层以降低目标任务的性能为代价,这可能会使基于深度神经网络的多任务学习变得更加糟糕。大多数以前的方法通常假设,由于深度神经网络 [ 9 , 28 , 26 , 33 , 29 ]的特征层conv1 – fc7的学习的共享表示,多个任务可以很好地关联起来。然而,如果不同的任务在深层特征上没有很好的关联,那么它可能是脆弱的,这是很常见的,因为较高的层不能安全地转移,任务可能也不一样。此外,现有的多任务学习方法是为二进制类任务而设计的。在多任务学习中,探索多类分类的任务关系仍然是一个开放的问题。
在这项工作中,我们同时在贝叶斯框架中学习多个特定于任务的层L的可转移特征和任务关系。在AlexNet中,最后一个特征层fc7的特征是4096维,这对于多任务关系学习来说是相对较高的。因此,我们在最后一个特性层fc7和分类器层fc8之间附加了一个瓶颈层fc7‘,将特征尺寸减少到256。然后特定于任务的层L被设置为{fc7’,fc8}。
定义任务T的数据为,
定义第t个任务第l个层的网络参数为
这里
定义矩阵
的行数和列数。为了捕捉所有T个任务之间的参数,我们构建第l个层的参数张量为
。定义所有特定层
参数张量为
。给定训练数据
,网络参数W的最大后验概率(MAP)估计为
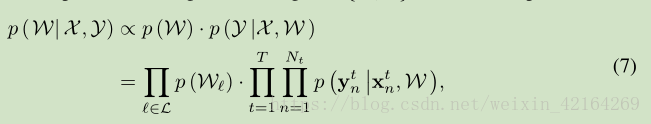
我们假设,对于先验的p(W),每个层的参数张量是独立于其它层的参数张量的
,这是大多数神经网络方法[3]所做的一个常见的假设。最后,我们假设当网络参数从先验取样时,所有任务都是独立的。这些独立的假设导致了方程的(7)的后验分解。
方程(7)中的最大似然估计(MLE)是由深度CNN在方程(6)中建模的,它可以在较低的层次上学习可转移的特性,用于多任务学习。我们选择共享所有这些层的网络参数(conv1-fc7)。该参数共享策略是对现有方法的一种放松,即[ 26 , 33 , 7 , 29 ],它们共享除分类器层之外的所有特性层。我们不共享特定于任务的层(瓶颈特性层fc7’和分类器层fc8),以减少潜在的负转移[30]。
方程的前一部分(7)是启用多任务深度学习的关键,因为前面的部分应该能够在参数张量上对任务关系进行建模。这篇论文第一次定义了基于张量正态分布[25]的第l层参数张量的先验
这里是模式1,模式2,模式3的协方差矩阵。具体地说,在张量正态先验中,第l层网络参数
中,行协方差矩阵
建模特征之间的关系(特征协方差),列协方差矩阵建模类之间的关系(类协方差),模式3协方差矩阵建模任务之间的关系。以前的方法广泛使用的一种通用策略,用于特征协方差[32、8]和类协方差[2、16],隐式地假设独立的特征和类,可能无法捕获它们之间的依赖关系。在此工作中,我们学习了所有的特征协方差、类协方差、任务协方差和所有来自数据的网络参数,以构建自适应任务关系。
我们将CNN的损失(6)和张量正态先验常(8)整合到(7)中的MAP 估计和取负对数,将W的MAP估计作为深度关系网络(DRN)的优化问题,形式化如下
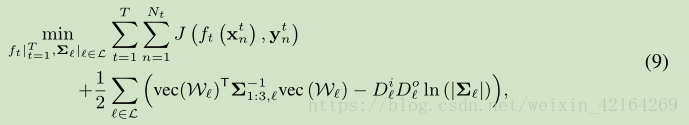
这里是特征协方差、类协方差和任务协方差的Kronecker product。此外,我们可以假设跨不同层的共享任务关系为
,它增强了特性fc7和分类器fc8之间的任务关系之间的联系。
4.2 Algorithm
优化问题 (10)相对于参数张量W,特征协方差,类协方差
,任务协方差
是非凸的。因此,我们迭代的优化一个,而固定其它的。我们首先更新任务t在第l层的参数
。当通过深度学习训练反向传播时,我们只需要反向传播(10)的目标函数的梯度,记为
在每个数据点
为,它可以通过下面计算
这里表示
中元素的矩阵化,它对应于参数矩阵
。由于训练CNN需要大量的带标签数据,它阻止了一些多任务学习问题,我们在ImageNet预训练的AlexNet上微调[30]。在每次迭代,我们更新W,我们可以更新特征协方差
,类协方差
,任务协方差
通过下面的触发算法
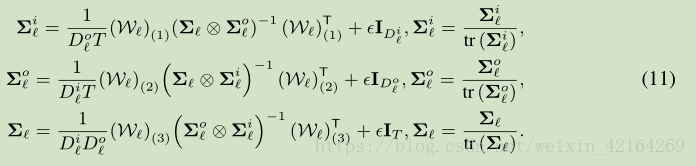
这里 ε 是一个小的惩罚,第二个方程为数值稳定性的协方差矩阵进行了标准化。这个算法是线性的。对于每一次迭代,卷积层的花费和标准的CNN一样,全连接层的花费为
。在多个曾更新任务关系张量的花费为
。
4.3 Discussion
我们的工作与之前的关系学习[31、32、16]和多任务深度学习在两个关键方面进行了对比。(1)张量正态先验。我们的工作是第一个探索张量正态分布的方法,作为不同层次的网络参数的先验,以在深层网络中学习任务关系。由于多个任务的网络参数自然地堆叠成一个3阶张量(如果考虑到卷积层,将是4阶张量),以前的矩阵正态分布[15]不能作为网络参数的先验来学习任务关系。(2)深层任务关系。我们在多个特定于任务的层上定义张量正常, L = {fc7' ,fc8}。以前的深度学习方法不学习任务关系,并假设共享的深层特性可以用于多任务学习,而这可能不是真正的[30]。以前的关系学习方法不是在深度网络中设计的,它不能为多任务学习学习可转移的特征。请注意,张量因子分解方法的多任务深度学习是第一个通过张量因子分解来解决多任务深度学习的工作,它从多层参数张量中学习共享特征子空间;与此相反,我们的工作从多人的参数张量中学习任务关系。














 8686
8686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









