







本文讨论一下如果使用python来批量替换word中的内容。
一、目标:
在word文档中,将水果的名称由中文替换为英文。
而且我们有多份word文档。

二、实现:
使用了python-docx 这个库。
1、安装
使用pip 安装很方便
pip install python-docx特别注意:python-docx这个库只能用来处理docx文件,不能进行doc文件的处理。
如果在Windows环境下, 可以使用 win32com模块,来批量把doc 文件转换为docx。
延伸一点:
doc文件与docx文件有什么不同呢?
- 存储方式的不同: doc 是二进制存储,docx是打包文件(docx文件可以解压,能看到里面的文件结构,主要是xml 等组成的打包文件);
- docx易于跨平台,docx更小;
- docx对于处理一些复杂对象比如公式、表格、图片更得心应手,因为可以通过xml的配置进行。
2、要使用的 python-docx 的基本用法
import docx
# 创建文档对象,获得word文档
doc = docx.Document(path)
#每一段的内容
for para in doc.paragraphs:
print(para.text)
#每一段的编号、内容
for i in range(len(doc.paragraphs)):
print(str(i), doc.paragraphs[i].text)3、简单的替换函数
# 将想要替换的内容写成字典的形式,
# dict = {"想要被替换的字符串": "新的字符串"}
replace_dict = {
"苹果":"apple",
"香蕉":"banana",
"猕猴桃":"Kiwi fruit",
"火龙果":"pitaya",
}函数如下:
def check_and_change(document, replace_dict):
"""
遍历word中的所有 paragraphs,在每一段中发现含有key 的内容,就替换为 value 。
(key 和 value 都是replace_dict中的键值对。)
"""
for para in document.paragraphs:
for i in range(len(para.runs)):
for key, value in replace_dict.items():
if key in para.runs[i].text:
print(key+"->"+value)
para.runs[i].text = para.runs[i].text.replace(key, value)
return document4、 一个完整的例子
环境:python ==3.7.4 , python-docx== 0.8.10
# coding=utf-8
import os
from docx import Document
# 放了一些docx 文件
old_file_path = "/Users/xxx/yyy/docx/"
# 生成新文件后的存放地址
new_file_path = "/Users/xxx/yyy/new_docx/"
replace_dict = {
"苹果": "apple",
"香蕉": "banana",
"猕猴桃": "Kiwi fruit",
"火龙果": "pitaya",
}
def check_and_change(document, replace_dict):
"""
遍历word中的所有 paragraphs,在每一段中发现含有key 的内容,就替换为 value 。
(key 和 value 都是replace_dict中的键值对。)
"""
for para in document.paragraphs:
for i in range(len(para.runs)):
for key, value in replace_dict.items():
if key in para.runs[i].text:
print(key+"-->"+value)
para.runs[i].text = para.runs[i].text.replace(key, value)
return document
def main():
for name in os.listdir(old_file_path):
print(name)
old_file = old_file_path + name
new_file = new_file_path + name
if old_file.split(".")[1] == 'docx':
document = Document(old_file)
document = check_and_change(document, replace_dict)
document.save(new_file)
print("^"*30)
if __name__ == '__main__':
main()三、运行结果
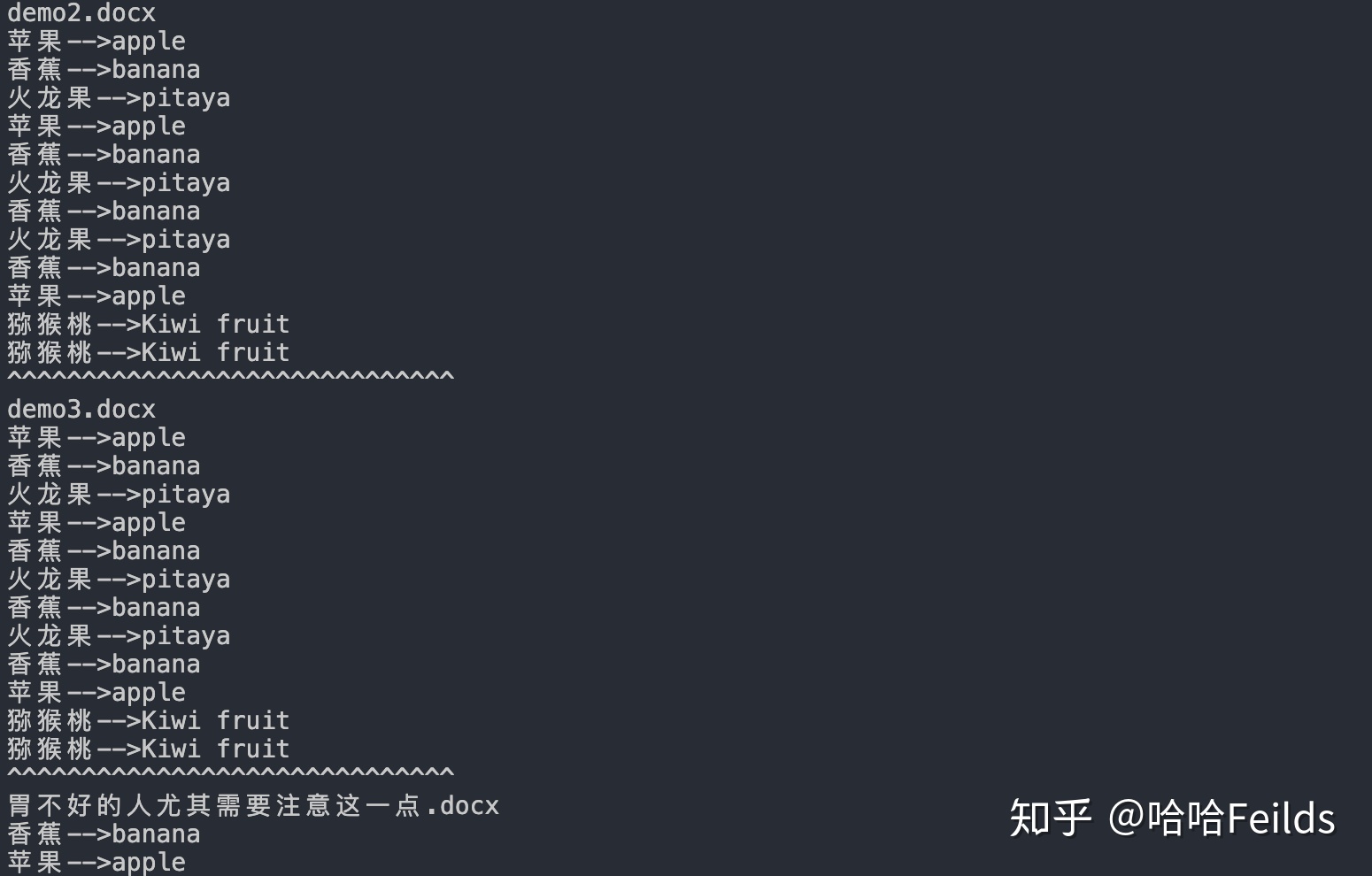
每一份word中,相应的内容替换成功。















 1810
1810











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









