






对刷过的算法进行总结,所用解法都是最符合我个人逻辑的,这对我来说很重要!

# 代码随想录——数组理论基础
首先要知道数组在内存中的存储方式,这样才能真正理解数组相关的面试题
数组是存放在连续内存空间上的相同类型数据的集合
数组可以方便的通过下标索引的方式获取到下标下对应的数据。
举一个字符数组的例子,如图所示:
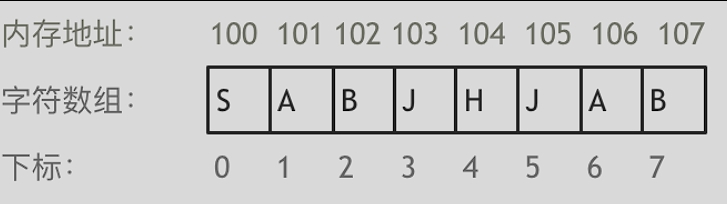
需要两点注意的是
- 数组下标都是从0开始的。
- 数组内存空间的地址是连续的
正是因为数组的在内存空间的地址是连续的,所以我们在删除或者增添元素的时候,就难免要移动其他元素的地址。
大家如果使用C++的话,要注意 vector 和 array 的区别,vector 的底层实现是 array,严格来讲vector 是容器,不是数组。数组的元素是不能删的,只能覆盖。
1、买卖股票的最佳时机
题目描述:

解法:
只用遍历一次数组,思路分为2部分:
- 使用数组中的首元素作为股票最低价格(minPrice),使用for循环遍历数组,找到真正的minPrice;
- 当卡住数组中临时的一个 minPrice 时,进入 else 来获取当前的利润(profit),这样不断往复,最终会获取到题目要求的最大利润。这样的解法十分优美!
class Solution {
public:
int maxProfit(vector<int>& prices) {
int profit = 0;
int minPrice = prices[0];
for(int i = 1; i < prices.size(); ++i){
// 找到数组中的最小元素
if(prices[i] < minPrice){
minPrice = prices[i];
}
// 找到最大利润
else{
if(prices[i] - minPrice > profit){
profit = prices[i] - minPrice;
}
}
}
return profit;
}
};2、移除元素
题目描述:

解法:
题目要求原地修改原数组,但数组的特性是:数组中的元素只能覆盖,不能删除。所以设一个新的索引 index 来重新排列修改后的数组。
使用 for 循环遍历数组时,如果 nums[i] == val, 则continue,程序不往下继续进行,而是进入下一次循环。当下一个 nums[i] != val 时,则将当前元素的索引赋值给新的索引 nums[index], 并且 index++ , 准备好接收下一个 != val 的数组元素。
class Solution {
public:
int removeElement(vector<int>& nums, int val) {
int index = 0;
for(int i = 0; i < nums.size(); ++i){
if(nums[i] == val){
// 跳过下面的赋值,进入下一次循环
continue;
}
nums[index] = nums[i];
index++;
}
return index;
}
};3、合并两个有序数组
题目描述:
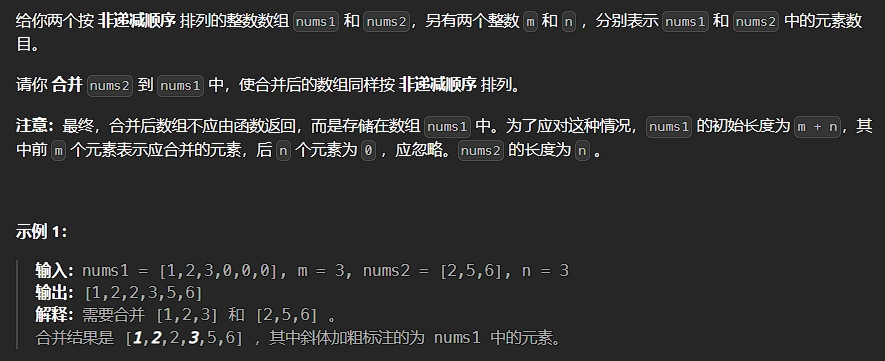
解法:
利用了2个数组非递减的特性,使用尾指针从后向前往 nums1 中加入元素。率先使用 resize 将 nums1 的长度扩大到 m + n,以便向 nums1 中加入新元素。
设置这样的 while 循环判断条件是考虑到2个数组总会有一方的索引先 < 0, 在消耗完其中一方时,再接一个 while 循环将另一方数组中的剩余元素添加至新的数组中
class Solution {
public:
void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) {
// 要将nums2合并到nums1中,nums1数组长度发生改变,定义新的长度以便定义新的尾指针
nums1.resize(m + n);
// 定义数组的尾指针
int i = m - 1;
int j = n - 1;
int index = m + n - 1;
while(i >= 0 && j >= 0){
if(nums1[i] < nums2[j]){
nums1[index] = nums2[j];
index--;
j--;
}
else{
nums1[index] = nums1[i];
index--;
i--;
}
}
while(i >= 0){
nums1[index] = nums1[i];
index--;
i--;
}
while(j >= 0){
nums1[index] = nums2[j];
index--;
j--;
}
}
};4、删除有序数组中的重复项
题目描述:
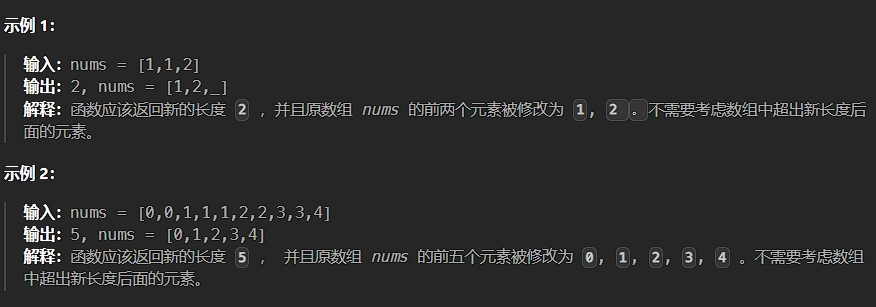
解法:
为数组首元素设置慢指针 slow,第二个元素设置快指针 fast,指针 fast 向后遍历,直至越界。指针 slow 只在指针 fast 遇到不重复项时向后移动一位,以此接收不重复项。最终返回 slow + 1即新数组的长度
题目中提到,返回的是最终的数组长度 ,是一个整数。但为什么输出的答案是数组呢? 输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的,根据我们函数返回的长度,它会打印出该长度范围内所有的元素
class Solution {
public:
int removeDuplicates(vector<int>& nums) {
int slow = 0;
int fast = 1;
while(fast < nums.size()){
if(nums[fast] != nums[slow]){
// 出现不重复的元素,用++slow去接收
++slow;
nums[slow] = nums[fast];
}
else{
// 出现重复元素,slow不动,fast往后走
fast++;
}
}
return slow + 1;
}
};5、删除有序数组中的重复项Ⅱ
题目描述:


解法:
首先给出第一次 AC 了8%测试用例的版本,方便记录我忽略了这道题[最关键的信息]。
class Solution {
public:
int removeDuplicates(vector<int>& nums) {
int slow = 1;
int fast = 3;
while(fast < nums.size()){
if(nums[fast] == nums[slow] && nums[fast - 1] == nums[slow]){
slow++;
nums[slow] = nums[fast - 1];
fast++;
}
else{
slow++;
nums[slow] = nums[fast];
fast++;
}
}
return slow + 1;
}
};由于这段代码的逻辑完全建立在第一个测试用例上
nums = [1,1,1,2,2,3]
可以处理前 3 个元素相同时的情况,但如果是下面这种情况:
nums = [0,0,1,1,1,2,2,3,3,4]
会将第二个元素 0 覆盖掉,很愁啊,修改了判断条件后连第一个测试用例都 AC 不过了!
那么关键是什么呢?答:“数组的前两个元素必然满足条件,无需处理”这一点官方解答中也提到了。
所以慢指针 slow 设在索引为 2 的位置上,使用一个循环,从索引为 2的位置开始遍历数组。对于当前遍历的元素,如果它与慢指针 slow 前两个位置的元素不相同,则将其加入到新数组中,同时慢指针 slow 增加。
正解:
class Solution {
public:
int removeDuplicates(vector<int>& nums) {
int n = nums.size();
// 打印 n 范围内所有的元素
if(n <= 2) return n;
int slow = 2;
for(int fast = 2; fast < n; ++fast){
// 当前元素要和它左边第 2 个元素进行比较
if(nums[fast] != nums[slow - 2]){
nums[slow] = nums[fast];
++slow;
}
}
return slow;
}
};还有一点值得注意:自增符 ++ 可以放在 nums[slow++] 中去写
- nums[slow++] —— 先用 nums[slow] 接收新值, slow 再加 1;
- nums[++slow] —— slow 先加 1,再用 nums[slow + 1] 接收新值;
6、多数元素
题目描述:
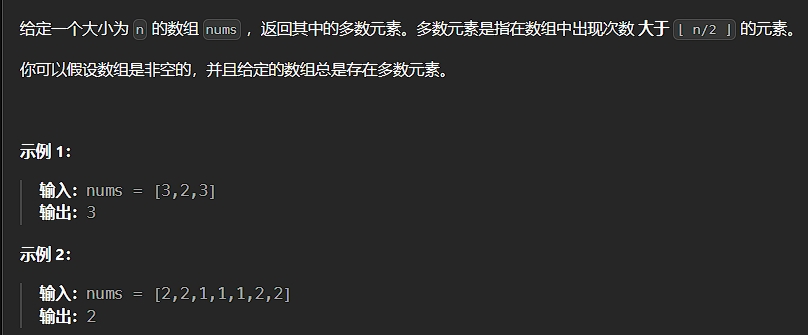 解法:
解法:
使用哈希映射(HashMap)来存储每个元素以及出现的次数。对于哈希映射中的每个键值对,键表示一个元素,值表示该元素出现的次数
对于数组的遍历,使用 C++11 中新增的 增强型 for 循环 :
for(int num: nums)
num 会遍历容器 nums 中的所有元素,这样可以很方便地记录每个元素的值和它们出现的次数
class Solution {
public:
int majorityElement(vector<int>& nums) {
// 利用映射类型的哈希结构,键存元素,值存出现次数
unordered_map<int, int> counts;
// 用来记录当前出现次数最多的元素以及它的出现次数
int Cur = 0;
int CurCnt = 0;
for(int num: nums){
++counts[num];
// 擂台赛
if(counts[num] > CurCnt){
Cur = num; // 更新主要元素为当前元素
CurCnt = counts[num]; // 更新出现次数最多的元素的出现次数
}
}
return Cur;
}
};使用 if 语句进行元素间的擂台赛,决出最终出现次数最多的元素,这个操作可以省去遍历哈希表找出值最大者这一过程
7、轮转数组
题目描述:
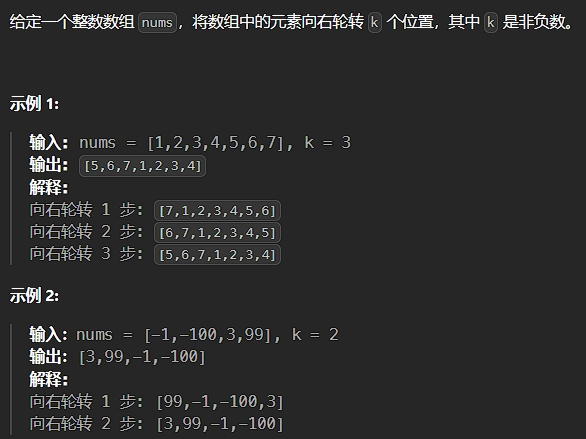
解法:
首先给出第一次 AC 了99%测试用例的版本,方便记录我忽略了这道题[最关键的信息]。
这道题的思路是容易想到的,说是“轮转”数组,其实用[滚动]数组描述更为贴切,每次从末尾元素开始,末尾元素滚至 下标0 的位置,剩余所有元素都要向右移动。
此时应注意的时,如果从头向尾移动,那么下标较大的元素会被下标较小的元素覆盖掉,所以应该从后向前移动每个元素,当除了原本的末尾元素还未就位,其余元素都已完成了位置的轮转,而且下标0 的位置被空出来了,把末尾元素插进去就好了,那么末尾元素为什么不会被覆盖掉呢?
我们可以提前使用一个临时变量来存储末尾元素
class Solution {
public:
void rotate(vector<int>& nums, int k) {
int n = nums.size();
while(k--){
int tmp = nums[n - 1]; // 将尾元素放在临时变量中
for(int i = n - 1; i > 0; i--){
nums[i] = nums[i - 1];
}
nums[0] = tmp;
}
}
};但是这种方法的时间复杂度是 O(k*n),k是旋转步数,n是数组的长度,在最后一个测试用例上超时了。
正解:
使用额外的等长数组来存储轮转后的元素,并将这个数组中的元素依次赋值回原数组,这个解法的时间复杂度只有O(n),因为只需要遍历1次数组
class Solution {
public:
void rotate(vector<int>& nums, int k) {
// 使用额外的等长数组
int n = nums.size();
vector<int> newNums(n);
for(int i = 0; i < n; ++i){
newNums[(i + k) % n] = nums[i];
}
for(int i = 0; i < n; ++i){
nums[i] = newNums[i];
}
}
};只是在判断元素的新下标时的公式不好想
(i + k) % n
总觉得有点像哈希冲突时的解法,希望下次写这题时我还记得这个公式
8、罗马数字转整数
题目描述:
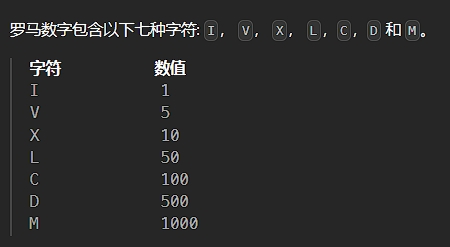
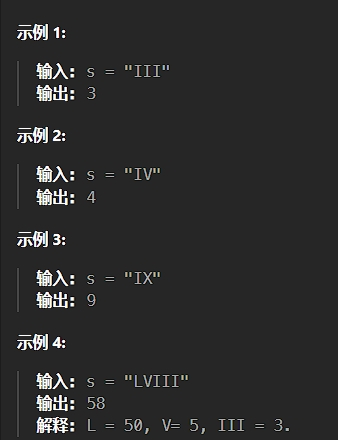
解法:
这题的唬人程度根本不是简单题的难度!官方给的描述太冗杂了,实际上就是
“如果当前字符的值小于其后面一个字符的值(即罗马数字规则中小数在大数左边表示减法),则将该值从结果中减去;否则将该值加到结果中。”
class Solution {
public:
int romanToInt(string s) {
// 标准的键值对形式,使用映射类型的哈希表结构存储
unordered_map<char, int> Roma = {
{'I', 1},
{'V', 5},
{'X', 10},
{'L', 50},
{'C', 100},
{'D', 500},
{'M', 1000},
};
int n = s.length();
int ans = 0;
for(int i = 0; i < n; ++i){
if(i < n - 1 && Roma[s[i]] < Roma[s[i + 1]]){
ans -= Roma[s[i]]; // 小数在大数左边表示减法
}else{
ans += Roma[s[i]];
}
}
return ans;
}
};对于官方提供的罗马数字和阿拉伯数字之间的对应关系,应该很自然地想到使用哈希表来存储它
if 语句的判断条件为:确保 i 不是最后一个元素,因为最后一个元素没有更后的元素和它比较了
当前元素如果小于后一个元素,则进行减法,否则进行加法
9、买卖股票的最佳时机Ⅱ
题目描述:

解法:
与“买卖股票的最佳时机”不同的是,此题可以买卖多支股票
找到最小的数了,在什么时候卖掉呢?示例1中表示,想要获得最大利润未必要在后续数中挑一个最大的去卖掉,按这个思路想的话会有以下问题:
1.如何判断买卖一支股票和买卖多支股票之间的利润大小?
2.刚开始可以找到值最小的那支股票,并假设后面可以卖掉;那么第二支股票呢?而且还面临一个问题:对于第一支股票而言,如果选择后续利润最大的一天卖掉,那么这一天之前价格比较低的第二支股票会因为过了买卖时间而无法进行交易了
总之想要用一般的方法去解决这个问题超出了我愚笨大脑的极限,所以总结了使用贪心解决问题的算法
(代码随想录)贪心算法:
假设以下数组

如果想到其实最终利润是可以分解的,那么本题就很容易了!
如何分解呢?
假如第 0 天买入,第 3 天卖出,那么利润为:prices[3] - prices[0]。
相当于(prices[3] - prices[2]) + (prices[2] - prices[1]) + (prices[1] - prices[0])。
此时就是把利润分解为每天为单位的维度,而不是从 0 天到第 3 天整体去考虑!
那么根据 prices 可以得到每天的利润序列:(prices[i] - prices[i - 1]).....(prices[1] - prices[0])。
从图中可以发现,其实我们需要收集每天的正利润就可以,收集正利润的区间,就是股票买卖的区间,而我们只需要关注最终利润,不需要记录区间。
那么只收集正利润就是贪心所贪的地方!
局部最优:收集每天的正利润,全局最优:求得最大利润。
局部最优可以推出全局最优,找不出反例,试一试贪心!
class Solution {
public:
int maxProfit(vector<int>& prices) {
int profit = 0;
for(int i = 1; i < prices.size(); ++i){
profit += max(prices[i] - prices[i - 1], 0);
}
return profit;
}
};10、最后一个单词的长度
题目描述:
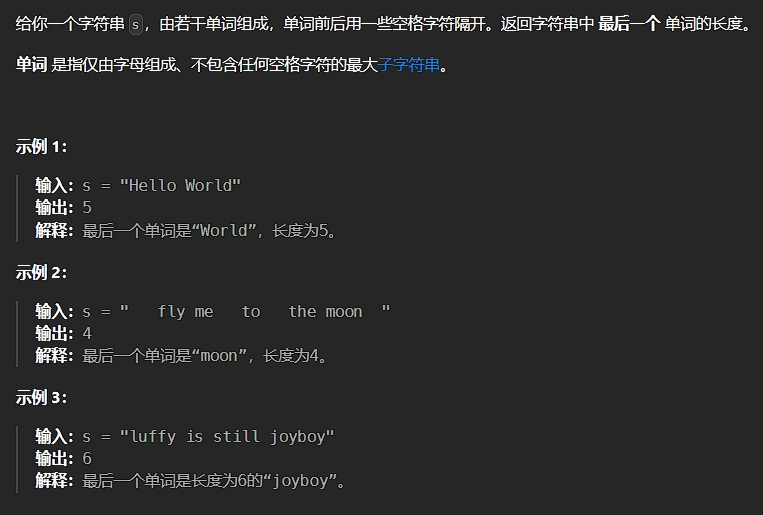
解法:
字符串是若干字符组成的有限序列,也可以理解为是一个字符数组。
从后往前遍历,先着手于测试用例1和3,如代码中的第二个while循环,可以统计最后一个单词的长度。
此时不加第一个while循环对串尾进行处理的话,index进不去第二个while循环,从而无法index--,会直接return cnt = 0。逻辑就是先处理正常情况下的字符串,而对于串尾是空格的字符串,再去执行处理方案。
class Solution {
public:
int lengthOfLastWord(string s) {
int cnt = 0;
int index = s.size() - 1;
// 处理串尾是空格时的情况
while(s[index] == ' ') index--;
while(index >= 0 && s[index] != ' '){
cnt++;
index--;
}
return cnt;
}
};11、跳跃游戏
题目描述:
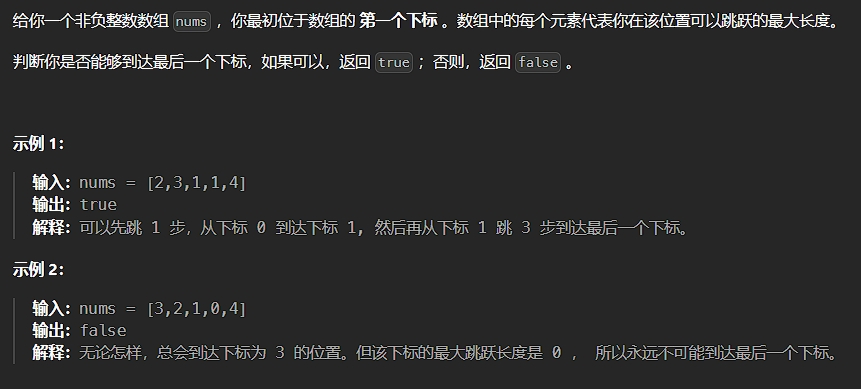
解法:
代码随想录中关于这题的解释非常清晰,如下:
用示例1举例,第一个位置元素是2,究竟是跳一步呢,还是两步呢?究竟跳几步才是最优呢?
其实跳几步无所谓,关键在于可跳的覆盖范围!不一定非要明确一次究竟跳几步,每次取最大的跳跃步数,这个就是可以跳跃的覆盖范围。
这个范围内,别管是怎么跳的,反正一定可以跳过来。
那么这个问题就转化为跳跃覆盖范围究竟可不可以覆盖到终点!
每次移动取最大跳跃步数(得到最大的覆盖范围),每移动一个单位,就更新最大覆盖范围。
贪心算法局部最优解:每次取最大跳跃步数(取最大覆盖范围),整体最优解:最后得到整体最大覆盖范围,看是否能到终点。
class Solution {
public:
bool canJump(vector<int>& nums) {
int cover = 0;
if(nums.size() == 1) return true;
// i 每次移动只能在 cover 的范围内移动
for(int i = 0; i <= cover; ++i){
cover = max(cover, nums[i] +i); // 首先更新当前位置可覆盖的最大范围
if(cover >= nums.size() - 1) return true;
}
return false;
}
};i 每次移动只能在 cover 的范围内移动,每移动一个元素,cover 得到该元素数值(新的覆盖范围)的补充,让 i 继续移动下去。
而 cover 每次只取 max(该元素数值补充后的范围, cover 本身范围)。
如果 cover 大于等于了终点下标,直接 return true 就可以了。
12、跳跃游戏Ⅱ
题目描述:
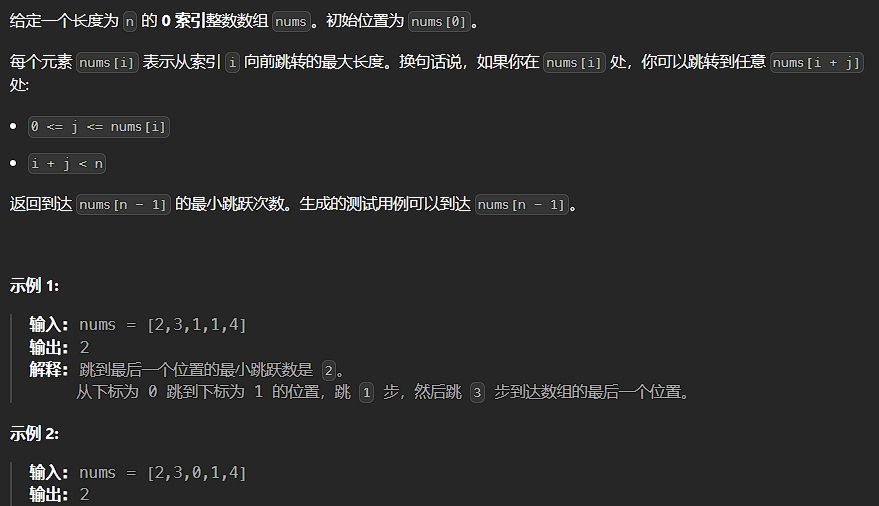
解法:
和上一题不同的是,此题需要记录跳到最后一个位置的最小跳数,用数组
[2,3,1,1,4]
举例说明。
初始位置为0,next此时为2,表示当前索引 0 可抵达的最大范围,
此时 i = 0, i 在 cover的范围内移动,i 和 cover 的值都是数组的索引下标。
当 i 抵达 cover 时,先判断当前的 i 是否已经抵达了终点,如果没有,则至少还需要跳一次,并记录下一跳可以抵达的最远范围,此时 count = 1, cover 也变成了 2
继续进入 for 循环,此时 i = 1,next = max(2, nums[1] + 1),即 next = 4, 此时 i 还没有抵达cover,因此不往下执行,而是进入 for 循环,此时 i = 2
i 这次可以抵达 cover了,但当前的 cover 还没有覆盖到终点,所以还需一跳, count = 2, cover = 4
此时 cover 可以覆盖到终点了,break 跳出循环并返回最小跳数
class Solution {
public:
int jump(vector<int>& nums) {
int cover = 0, count = 0, next = 0;
if(nums.size() == 1) return count;
// i仍旧只能在cover范围内移动
for(int i = 0; i <= cover; ++i){
// 更新当前位置可抵达的最大范围
next = max(next, nums[i] + i);
// 当i抵达cover时
if(i == cover){
// 如果没有抵达终点
if(i < nums.size() - 1){
count++; // 跳数+1
cover = next; // 更新当前跳到的最大范围
if(cover >= nums.size() - 1) break;
}
}
}
return count;
}
};13、最长公共前缀
题目描述:

解法:
将字符串数组中的第一个字符串作为基准,每次拿出基准中的一个字符和剩余的字符串进行对比。
class Solution {
public:
string longestCommonPrefix(vector<string>& strs) {
string base = strs[0]; // 选择首个字符串为基准
for(int i = 0; i < base.size(); ++i){
char c = base[i]; // 拿出基准的第一个字符
// 拿剩余的字符串和基准进行对比
for(int j = 1; j < strs.size(); ++j){
// 当出现不同的字符时,才去截断基准获取最长公共前缀
// 如果按照正向思路,当字符相同时将该字符加入最后的结果中,这样比较的话很难对已经加入结果的字符进行删除
// 就像 flower 和 flow,最终会保存 flow 为最长前缀,那么当 flight和基准进行比较时,还得删去ow两个字符
// 所以使用“出现不同字符再去截断,而之前的前缀就是答案”的思想
if(strs[j][i] != c){
return base.substr(0, i);
}
}
}
return base;
}
};if(strs[j][i] != c) 将后续每个字符串的当前字符和基准进行比较,每次只比一个字符,继而更新 c 值,比第二个、第三个...第n个字符
base.substr(0, i)表示对当前的字符串进行从 0 到 i 的截断,对 base 原地进行修改。
14、整数转罗马数字
题目描述:

解法:
通过这道题我知道罗马帝国灭亡是有原因的
按官方的解法提前定义一个长度为13的键值对Roma[],有各种排列组合

然后就简单了,使用 for(const auto& [value, symbol] :Roma)来遍历预定义的容器Roma,这里的 & 符号表示通过引用方式获取容器中的元素,可以避免不必要的复制开销。
class Solution {
public:
string intToRoman(int num) {
// 定义罗马十三钗
const pair<int, string> Roma[] = {
{1000, "M"},
{900, "CM"},
{500, "D"},
{400, "CD"},
{100, "C"},
{90, "XC"},
{50, "L"},
{40, "XL"},
{10, "X"},
{9, "IX"},
{5, "V"},
{4, "IV"},
{1, "I"},
};
string result = "";
for(const auto &[value, symbol] : Roma){
while(num >= value){
num -= value;
result += symbol;
}
if(num == 0) break;
}
return result;
}
};15、H指数
题目描述:

解法:
首先对数组进行 sort,默认从小到大排序,用示例1举例:
排序后的数组为:
[0, 1, 3, 5, 6]
因为后面的论文被引次数最高,所以选择从后向前遍历。我们先定义 h 指数为0,接下来则:
6 > 0,则 h + 1, h = 1
5 > 1,则 h + 1, h = 2
3 > 2,则 h + 1, h = 3
此时1 < h,则返回 h 指数
在与 h 进行比较的过程中,我们都可以找到至少引用了 h + 1次的论文,而对于数组中的某一篇论文而言,必定是没有达到前面逐层递增的引用次数的,
这种思路并不建立在“先找到合适的拥有居中引用次数的论文”,而是通过引用次数较多的论文来逼近满足 h 指数的最低引用论文,这个思路很偏,但意外地很好接受
class Solution {
public:
int hIndex(vector<int>& citations) {
// 先对数组排序,默认从小到大
sort(citations.begin(), citations.end());
int h = 0;
for(int i = citations.size() - 1; i >=0; i--){
if(citations[i] > h) h++;
}
return h;
}
};16、O(1)时间插入、删除和获取随机元素问题
题目描述:
这道题不是常规意义上的算法题,而是考验数据结构的设计题
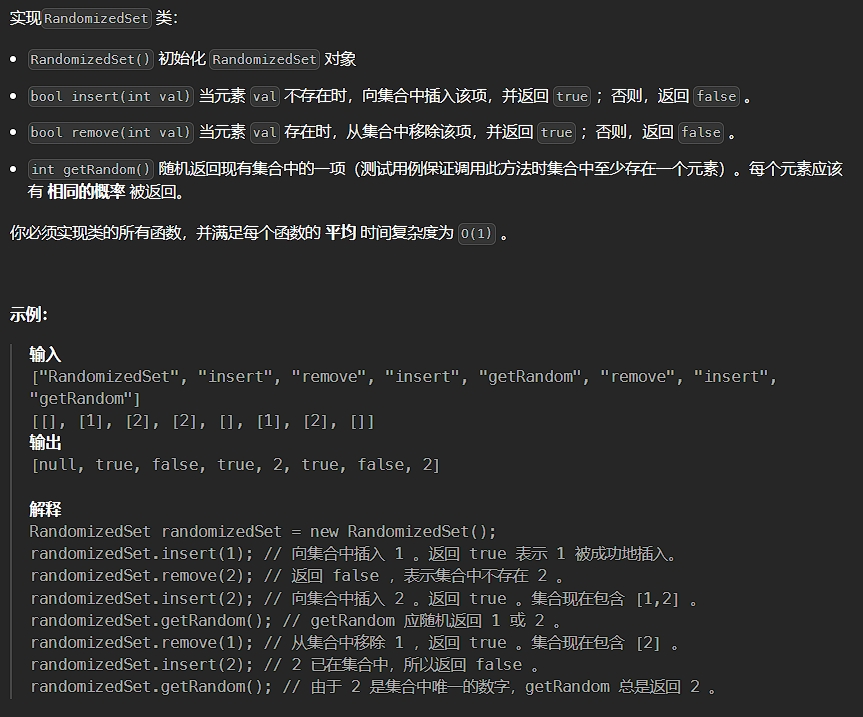
解法:
这道题要求实现一个类,满足插入、删除和获取随机元素操作的平均时间复杂度为 O(1)
数组可以在 O(1)的时间内完成获取随机元素操作,但是由于无法在O(1) 的时间内判断元素是否存在,因此不能在 O(1) 的时间内完成插入和删除操作。
哈希表可以在 O(1) 的时间内完成插入和删除操作,但是由于无法根据下标定位到特定元素,因此不能在O(1) 的时间内完成获取随机元素操作。
为了满足插入、删除和获取随机元素操作的时间复杂度都是O(1),需要将数组和哈希表结合,数组中存储元素,哈希表中存储每个元素在数组中的下标。
对于动态数组,C++ 有一个成熟且靠谱的工具,叫做 vector
对于哈希表,则 unordered_map<int,int> hashtable

其中删除元素 remove(val) 需要特别说明一下:
如果直接在vector中删除某个元素,会引起后续元素的大幅度移动。所以为了实现常量时间,我们选择将要删除的元素调换到最后一位,再使用vector的pop_back()方法进行删除。
这里需要注意,要同步修改哈希表中的元素!使用erase(val) 删除元素的键值对,同时还要修改原先在最后一位,被调换到前面的元素的对应下标!
LeetCode上有一位的解答比官方好理解的多,推荐大家去看!我也是按照他的思路去解决这道题的,直接帖代码吧~
class RandomizedSet {
private:
unordered_map<int, int> hash;
vector<int> nums;
public:
RandomizedSet() {
// 初始化随机数生成器的种子,在getRandom函数中的rand调用,目的是每次生成不同的随机数
srand((unsigned)time(NULL));
}
bool insert(int val) {
// hash.end()指哈希表中最后一个元素之后的位置
if(hash.find(val) != hash.end()) return false; // 该元素已经存在于集合中了
nums.push_back(val); // 向nums末尾插入
hash[val] = nums.size() - 1; // 更新该元素下哈希表中的下标
return true;
}
bool remove(int val) {
if(hash.find(val) == hash.end()) return false; // 删除时,如果集合中不存在val,返回false
int valPos = hash[val]; // 被删元素当前的下标
int lastPos = nums.size() - 1; // 数组末尾元素的下标
// 交换被删元素和nums末尾元素的位置
int tmp = nums[valPos];
nums[valPos] = nums[lastPos];
nums[lastPos] = tmp;
nums.pop_back(); // // 删除nums末尾元素
hash[nums[valPos]] = valPos; // 更新交换后nums末尾元素的下标和值
hash.erase(val);
return true;
}
int getRandom() {
// 使用 rand() 函数生成一个随机数,并对其取模 size
// 以得到一个下标介于 0 到 size-1 之间的随机整数,如果不提前初始化种子,每次随机取值的结果是相同的
int pos = rand() % nums.size();
return nums[pos];
}
};
/**
* Your RandomizedSet object will be instantiated and called as such:
* RandomizedSet* obj = new RandomizedSet();
* bool param_1 = obj->insert(val);
* bool param_2 = obj->remove(val);
* int param_3 = obj->getRandom();
*/17、除自身以外数组的乘积
题目描述:
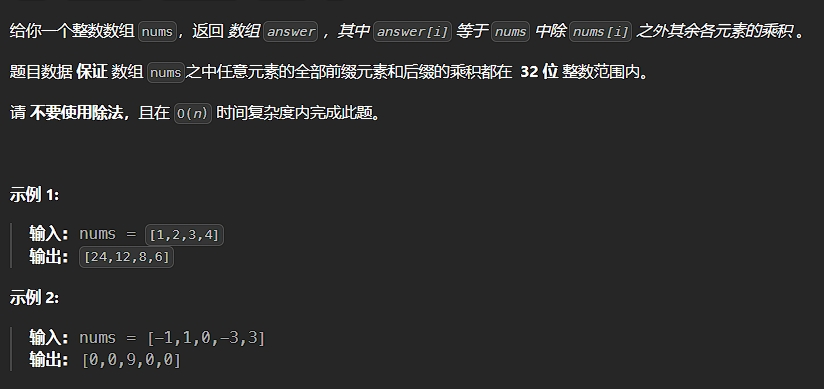
解法:
这道题在题库中的顺序刚好在16题,即关于变长数组和哈希表的上题的下面,我想着这俩题排在一起应该是会存在某种规律的
所以我想到——“每次处理某个元素时,将该元素放在数组的末尾,再将前面的元素全部相乘”
这个逻辑适用于除末尾元素之外的所有元素,所以一开始就先把末尾元素给处理了。
但这个方法的时间复杂度来到了O(n²),不符合题意。
class Solution {
public:
vector<int> productExceptSelf(vector<int>& nums) {
int n = nums.size();
vector<int> answer(n, 1);
// 先处理数组末尾元素
int last = 0;
while(last < n - 1){
answer[n - 1] *= nums[last];
last++;
}
for(int i = 0; i < n - 1; ++i){
int temp = 0;
int j = 0;
// 把将要操作的 nums[i] 放在数组最后
temp = nums[n - 1];
nums[n - 1] = nums[i];
nums[i] = temp;
// 遍历前面每一个元素并相乘
while(j < n - 1){
answer[i] *= nums[j];
j++;
}
}
return answer;
}
};正解:
利用索引左侧所有数字的乘积和右侧所有数字的乘积(即前缀与后缀)相乘得到答案
我们需要用两个循环来填充 L 和 R 数组的值。对于数组 L,L[0] 应该是 1,因为第一个元素的左边没有元素。对于其他元素:
L[i] = L[i - 1] * nums[i - 1]
同理,对于数组 R,R[n - 1] 应为 1。n 指的是输入数组的大小。其他元素:
R[i] = R[i+1] * nums[i+1]
class Solution {
public:
vector<int> productExceptSelf(vector<int>& nums) {
int n = nums.size();
// left 和 right 分别表示左右两侧的乘积列表
vector<int> L(n), R(n);
vector<int> answer(n);
L[0] = 1;
R[n - 1] = 1;
// 从原数组第二个元素开始处理
for(int i = 1; i < n; ++i){
L[i] = nums[i - 1] * L[i - 1];
}
// 从原数组倒数第二个元素开始处理
for(int i = n - 2; i >= 0; --i){
R[i] = nums[i + 1] * R[i + 1];
}
for(int i = 0; i < n; ++i){
answer[i] = L[i] * R[i];
}
return answer;
}
};
18、加油站
题目描述:

解法:
直接从全局进行贪心选择,情况如下:
-
情况一:如果 gas 的总和小于 cost 总和,那么无论从哪里出发,一定是跑不了一圈的
-
情况二:rest[i] = gas[i]-cost[i]为一天剩下的油,i从0开始计算累加到最后一站,如果累加没有出现负数,说明从0出发,油就没有断过,那么0就是起点。
-
情况三:如果累加的最小值是负数,汽车就要从非0节点出发,从后向前,看哪个节点能把这个负数填平,能把这个负数填平的节点就是出发节点。
class Solution {
public:
int canCompleteCircuit(vector<int>& gas, vector<int>& cost) {
// 从全局贪心思路出发
int curSum = 0;
int min = INT_MAX; // 设置最大整数宏,防止溢出
// 从0号加油站出发,根据跑完一圈后的 curSum 的值推断出 3 种情况
for(int i = 0; i < gas.size(); ++i){
int rest = gas[i] - cost[i]; // 从当前加油站出发的油量剩余情况
curSum += rest;
if(curSum < min){
min = curSum;
}
}
if(curSum < 0) return -1; // 情况1
if(min >= 0) return 0; // 情况2
// 情况3
for(int i = gas.size() - 1; i >=0; --i){
int rest = gas[i] - cost[i];
min += rest;
if(min >= 0) return i;
}
return -1;
}
};19、反转字符串中的单词
题目描述:

解法:
如何处理串前、串后以及串间的空格是解决本题的关键
思想“从后向前遍历,先处理串尾多余的空格,遇到一个单词后为该单词后面手动添加1个空格,并将该单词添加到提前定义的辅助数组中”
想要实现上面的思想,需要使用到2个指针,首先使用快指针 fast 遍历字符串,去除空格,并定位到第一个单词的首个字符的位置,此时引入慢指针 slow ,slow 刚好卡在第一个单词的末尾,紧接着使用 substr 函数截取当前完整的
substr(string,start<,length>)从string 的 start 位置开始提取字符串,length:待提取的字符串的长度
当前单词处理结束后,又会遇到空格,则此时仍让 fast 指针先走,除掉空格后,将 slow 指针定位到下一个单词的末尾
class Solution {
public:
string reverseWords(string s) {
// 使用双指针
int fast = s.size() - 1;
string res; // 使用额外空间接收每个单词
// 删除末尾空格
while(s[fast] == ' ' && fast > 0) fast--;
// 当串尾不为空格时,引入慢指针
int slow = fast;
while(fast >= 0){
while(fast >= 0 && s[fast] != ' ') fast--;
res += s.substr(fast + 1, slow - fast) + ' '; // 给每个单词后面加上空格
while(fast >= 0 && s[fast] == ' ') fast--;
slow = fast; // 将慢指针定位到下一个单词的末尾
}
return res.substr(0, res.size() - 1); // 截断为res中最后一个单词添加的额外空格
}
};20、找出字符串中第一个匹配项的下标
题目描述:

解法:
这道题都在宣扬模式匹配算法(KMP算法),可是这学起来真的很麻烦,假如笔试遇到了,再让我用 KMP 写大概率是写不出来的,还是用暴力解法吧!
- 将字符串 needle 从头开始的每个字符逐一和字符串 haystack 的字符逐一匹配(也是从第一个字符开始)
- 如果遇到不匹配的情况则继续从字符串 haystack 的第二个字符开始匹配,同理如果还是遇到不匹配的情况,则从第三个字符开始……以此类推,直至遍历完 haystack 或出现完全匹配的情况
- 若出现了完全匹配的情况,则返回第一个匹配项的下标,如示例1
利用 '\0' 判断是否遍历完整个字符串,这个方法取自C语言中字符串的特性
count_j 用来判断是否已经遍历完 haystack 字符串,仍未找到匹配项
class Solution {
public:
int strStr(string haystack, string needle) {
int n = haystack.size();
int m = needle.size();
if(m > n) return -1;
int i = 0, j = 0;
int count_j = 0;
while(true){
i = 0; // 重置i,每一次都要从needle第一个字符开始匹配
j = count_j;
if(haystack[j] == '\0') return -1; // haystack已经遍历完,且没有出现匹配项
// 将字符串needle和字符串haystack的字符逐一匹配
while(needle[i] == haystack[j] && needle[i] != '\0' && haystack[j] != '\0' ){
i++;
j++;
}
// 如果循环退出后needle[i]为'\0',就说明已经完全匹配,返回第一个匹配项的下标
if(needle[i] == '\0') return count_j;
//如果未完全匹配,则从haystack的下一个字符开始重新与字符串needle进行匹配
else count_j++;
}
return -1;
}
};21、Z字形变换
题目描述:
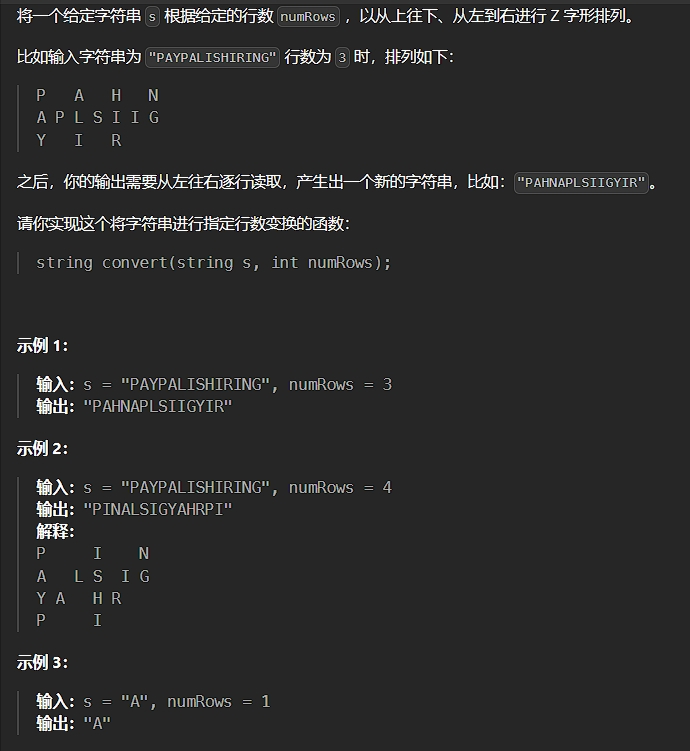
解法:
这题的解法只推荐K神的解法——传送门(超帅解法!)
这道题的描述是很差劲的,但我们不需要去考虑为什么要这样 Z 形排列,只要抓住重点“每个字符都有自己应该呆在的行”而后灵活运用 flag 来进行行数的变换,妙啊,很妙啊!
class Solution {
public:
string convert(string s, int numRows) {
// 根据未通过的测试用例加上这句
if(numRows < 2) return s;
// 有几行,就建立有几个“格子”的字符串数组,每个格子存放相同行数的字符
vector<string> rows(numRows);
int i = 0;
int flag = -1;
string res;
for(char c : s){
// 先将第一个字符压入rows
rows[i].push_back(c);
// 该换行了!需要换行的2种情况
// 前 numRows 个元素一定是在不同行的
if(i == 0 || i == numRows - 1){
flag *= -1;
}
i += flag; // 如果 numRows=3,则 i 根据 flag而变化的值为0、1、2
}
for(string row : rows){
res += row;
}
return res;
}
};这个解法是真的帅啊!看到题解的时候给我的感觉不亚于翔阳面对牛若时发出的感叹!
以上的题目都是根据我每天刷力扣上的面试150题记录得来的,数组和字符串篇到此结束。
常看常知新!不同于去年刷题,只会强行理解题解,这次刷题明显感觉自己能做出来的题变多了,看题解也会掺入自己的想法去修改为自己最能理解的版本,总之再接再厉!














 586
586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









