









https://github.com/alibaba/canal/releases
1.开启mysql的binlog功能。
[mysqld]
log-bin=mysql-bin
binlog-format=ROW
server_id=1
查看log_bin日志是否正确
show variables like '%log_bin%';
show variables like 'binlog_format%'


添加mysql用户 账户:canal 密码:canal ,可以让canal查询、复制
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
注意:需要重启mysql才能生效
2.下载canal地址
这里显示1.1.4做演示,下载图中红框文件

3.配置canal.deployer-1.1.4.tar.gz
上传的服务器创建一个文件夹并解压到文件夹里面
mkdir canal-deployer #创建一个文件夹
tar zxvf canal.deployer-1.1.4.tar.gz -C canal-deployer #解压
cd canal-deployer #进入文件夹
内容如下

进入里面配置vim conf/example/instance.properties 配置文件
这里不需要配置canal.properties文件
默认文件什么都不需要改、只需要修改ip 为数据库的IP地址
# position info
canal.instance.master.address= 192.168.75.130:3306 #修改IP
canal.instance.master.journal.name=
canal.instance.master.position=
canal.instance.master.timestamp=
canal.instance.master.gtid=
...
现在我们启动
./bin/start.sh #启动canal
cat logs/canal/canal.log #图1
cat logs/example/example.log #图2
启动成功后
#图1
#图1
canal.deploter启动成功了
4.配置canal.adapter-1.1.4.tar.gz
创建文件夹解压都和canal.deploter步骤一样这里我就不再说了。完成后
这就是目录结构

进入里面配置vim conf/application.yml 配置文件
我们需要配置四个点,我在代码中标注了#1. #2. #3. #4.
数据库的账户密码就是我们刚刚创建的用户 canal canal
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
mode: tcp # kafka rocketMQ
canalServerHost: 127.0.0.1:11111 #1.修改成canal.deploter的ip
# zookeeperHosts: slave1:2181
# mqServers: 127.0.0.1:9092 #or rocketmq
# flatMessage: true
batchSize: 500
syncBatchSize: 1000
retries: 0
timeout:
accessKey:
secretKey:
srcDataSources: #2.填写好要连接的数据库
defaultDS:
url: jdbc:mysql://127.0.0.1:3306/test?useUnicode=true #2.1注意连接的数据库
username: canal
password: canal
canalAdapters:
- instance: example # canal instance Name or mq topic name
groups:
- groupId: g1
outerAdapters:
- name: logger
# - name: rdb
# key: mysql1
# properties:
# jdbc.driverClassName: com.mysql.jdbc.Driver
# jdbc.url: jdbc:mysql://127.0.0.1:3306/mytest2?useUnicode=true
# jdbc.username: root
# jdbc.password: 121212
# - name: rdb
# key: oracle1
# properties:
# jdbc.driverClassName: oracle.jdbc.OracleDriver
# jdbc.url: jdbc:oracle:thin:@localhost:49161:XE
# jdbc.username: mytest
# jdbc.password: m121212
# - name: rdb
# key: postgres1
# properties:
# jdbc.driverClassName: org.postgresql.Driver
# jdbc.url: jdbc:postgresql://localhost:5432/postgres
# jdbc.username: postgres
# jdbc.password: 121212
# threads: 1
# commitSize: 3000
# - name: hbase
# properties:
# hbase.zookeeper.quorum: 127.0.0.1
# hbase.zookeeper.property.clientPort: 2181
# zookeeper.znode.parent: /hbase
- name: es #3.配置Elasticsearch地址
hosts: 127.0.0.1:9300 # 127.0.0.1:9200 for rest mode
properties:
# mode: transport # or rest
# security.auth: test:123456 # only used for rest mode
cluster.name: elasticsearch #4.注意es的名字
配置完成后进入es文件夹,里面有三个文件可以删除,我建议大家保留做个模板参考
cd es
cp customer.yml canal.yml #拷贝一份
配置 canal.yml文件
dataSourceKey: defaultDS #一定要和application.yml下面的srcDataSources名字一样
destination: example
groupId: g1
esMapping:
_index: canal #配置es索引库
_type: _doc
_id: _id #注意这个和sql里的id别名一致不然会报后面的错误
# relations:
# customer_order:
# name: customer
sql: "select a.id as _id, a.name, a.sex, a.age, a.amount, a.email, a.occur_time from canal a"
# etlCondition: "where t.c_time>={}"
commitBatch: 3000
创建一张mysql数据库表用于测试
create table canal
(
id int auto_increment
primary key,
name varchar(20) null comment '名称',
sex varchar(2) null comment '性别',
age int null comment '年龄',
amount decimal(12, 2) null comment '资产',
email varchar(50) null comment '邮箱',
occur_time timestamp default CURRENT_TIMESTAMP not null
);
elasticsearch创建索引和Mappings
PUT 127.0.0.1:9200/canal
{
"mappings":{
"_doc":{
"properties":{
"id": {
"type": "long"
},
"name": {
"type": "text"
},
"sex": {
"type": "text"
},
"age": {
"type": "long"
},
"amount": {
"type": "long"
},
"email": {
"type": "text"
},
"occur_time": {
"type": "date"
},
"customer_order":{
"type":"join",
"relations":{
"customer":"order"
}
}
}
}
}
}
OK 我们启动 canal.adapter
#启动
./bin/start.sh
#查看日志
cat logs/adapter/adapter.log

ok 我们的canal.adapter 启动成功
去数据库添加一条数据

查看完毕后看打印日志,如果没有报错那就说明插入成功了

踩坑记:大家遇到这种错误一半都是数据库与es类型不匹配,或者配置的_id不对
(如果没有报错略过)
2020-09-08 01:57:04.745 [pool-2-thread-1] ERROR c.a.o.canal.adapter.launcher.loader.CanalAdapterWorker - java.lang.NullPointerException
java.lang.RuntimeException: java.lang.NullPointerException
at com.alibaba.otter.canal.client.adapter.es.service.ESSyncService.sync(ESSyncService.java:110)
at com.alibaba.otter.canal.client.adapter.es.service.ESSyncService.sync(ESSyncService.java:58)
at com.alibaba.otter.canal.client.adapter.es.ESAdapter.sync(ESAdapter.java:169)
at com.alibaba.otter.canal.client.adapter.es.ESAdapter.sync(ESAdapter.java:148)
at com.alibaba.otter.canal.adapter.launcher.loader.AbstractCanalAdapterWorker.batchSync(AbstractCanalAdapterWorker.java:201)
at com.alibaba.otter.canal.adapter.launcher.loader.AbstractCanalAdapterWorker.lambda$null$1(AbstractCanalAdapterWorker.java:62)
at java.util.ArrayList.forEach(ArrayList.java:1259)
at com.alibaba.otter.canal.adapter.launcher.loader.AbstractCanalAdapterWorker.lambda$null$2(AbstractCanalAdapterWorker.java:58)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.NullPointerException: null
at com.alibaba.otter.canal.client.adapter.es.support.ESTemplate.insert(ESTemplate.java:82)
at com.alibaba.otter.canal.client.adapter.es.service.ESSyncService.singleTableSimpleFiledInsert(ESSyncService.java:442)
at com.alibaba.otter.canal.client.adapter.es.service.ESSyncService.insert(ESSyncService.java:133)
at com.alibaba.otter.canal.client.adapter.es.service.ESSyncService.sync(ESSyncService.java:93)
... 11 common frames omitted
5.查看elasticsearch的同步情况
get 127.0.0.1:9200/canal/_search
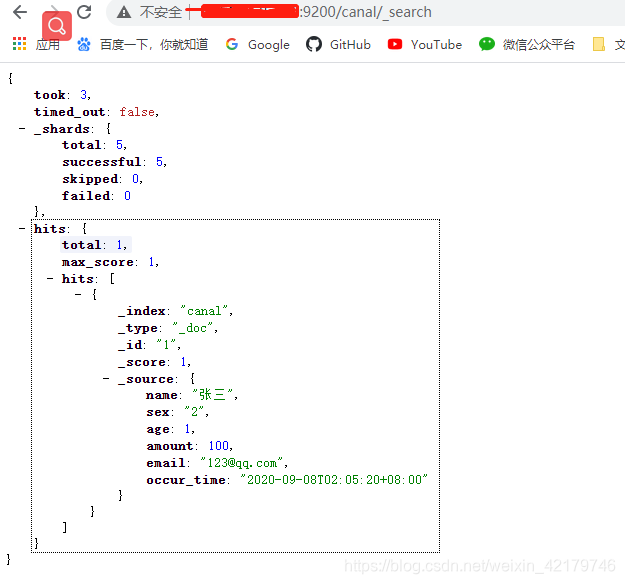
OK 看到这我们已经搭建好了增量数据同步了 goodbye














 8571
8571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









