









一、题目描述
题目描述在这里:https://github.com/maplezzz/NTU_ML2017_Hung-yi-Lee_HW/tree/master/HW3
这个git项目里不包括train.csv,所以我一开始在jupyter notebook里运行data_analysis.ipynb的时候很奇怪为什么没有文件却可以写入并打印出结果,然后自己重新运行了一遍就报错了:
FileNotFoundError: [Errno 2] File b'data/train.csv' does not exist: b'data/train.csv'这篇博客中可以找到train.csv:https://www.cnblogs.com/HL-space/p/10888556.html
下载过程是漫长的(辣鸡百度云,哎),中间我还下了一本网络小说《有匪》哈哈。

第一行是index(这个在后面的数据处理需要注意),label描述表情属于哪一类((0)生气,(1)厌恶,(2)恐惧,(3)高兴,(4)难过,(5)惊讶和(6)中立(即面无表情,无法归为前六类)),feature由48*48=2304个人脸图像的像素值表示。
二、数据预处理
1、分割数据
导入fer2013.csv:

import pandas as pd
import os
infile = "fer2013.csv"
output_dir = "data\\"
rawData = pd.read_csv(infile,header=0)
#修改列名,不加inplace不会修改
rawData.rename(columns = {'emotion':'label','pixels':'feature'},inplace=True)
#统计训练集、验证集、测试集中的数据个数
num_train = 0
num_valid = 0
for index, row in rawData.iterrows():
if row["Usage"] == 'Training':
num_train += 1
elif row["Usage"] == 'PublicTest':
num_valid +=1
num_valid += num_train
#去掉Usage列
Data = rawData.drop(["Usage"], axis=1)
#划分训练集、验证集和测试集
train = Data[:num_train]#左闭右开区间
valid = Data[num_train:num_valid]
test = Data[num_valid:]
if not os.path.exists(output_dir):
os.mkdir(output_dir)
#\t表示制表符,index=False表示不添加索引
train.to_csv(os.path.join(output_dir+'train.csv'), index=False)
valid.to_csv(os.path.join(output_dir+'valid.csv'), index=False)
test.to_csv(os.path.join(output_dir+'test.csv'), index=False)
2、testData
统计各个表情的样本数,默认按从大到小排列:
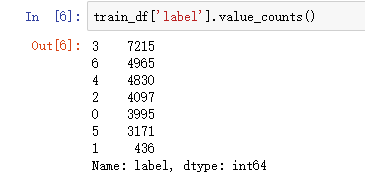
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
name = ['angry','disgust', 'fear', 'happy', 'sad', 'surprise', 'neutral']
train_filename = "data/train.csv"
train_df = pd.read_csv(train_filename)
train_df
train_df['label'].value_counts()
def plot_images(images, cls_true, cls_pred=None):
assert len(images) == len(cls_true) == 9
# Create figure with 3x3 sub-plots.创建子图
fig, axes = plt.subplots(3, 3)#axes子图轴域
fig.subplots_adjust(hspace=0.3, wspace=0.3)#调整边距和子图的间距
for i, ax in enumerate(axes.flat):#flat方法是将整个numpy对象转换成了1维对象
# Get the i'th image and reshape the array.
#image = images[i].reshape(img_shape)
# Ensure the noisy pixel-values are between 0 and 1.
#image = np.clip(image, 0.0, 1.0)
# Plot image.
ax.imshow(images[i],
cmap = 'gray',#颜色图谱(colormap), 默认绘制为RGB(A)颜色空间。
interpolation='nearest')#最近邻差值
# Show true and predicted classes.
if cls_pred is None:#还没有预测结果
xlabel = "True: {0}".format(name[cls_true[i]])#字符串格式化
else:
xlabel = "True: {0}, Pred: {1}".format(name[cls_true[i]], name[cls_pred[i]])
# Show the classes as the label on the x-axis.
ax.set_xlabel(xlabel)#把xlabel在图中标注出来
# Remove ticks from the plot.
ax.set_xticks([])#设置坐标轴刻度
ax.set_yticks([])
# Ensure the plot is shown correctly with multiple plots
# in a single Notebook cell.
plt.show()
class clean_data(object):
def __init__(self, filename):
self._train_df = pd.read_csv(filename)#读文件
self._distribution = self._train_df['label'].value_counts()#统计各类表情数目
#.map将函数作用在序列的每个元素上,然后创建由函数返回值组成的列表
#.split通过指定分隔符对字符串进行切片
#将feature(字符串)分割为浮点型数值列表
self._train_df['feature'] = self._train_df['feature'].map(lambda x : np.array(list(map(float, x.split()))))
#获取feature(image像素点)的size
self._image_size = self._train_df.feature[0].size
#获取图片大小
self._image_shape = (int(np.sqrt(self._image_size)), int(np.sqrt(self._image_size)))
#获取样本数目
self._dataNum = self._train_df.size
#feature矩阵
self._feature = np.array(self._train_df.feature.map(lambda x: x.reshape(self._image_shape)).values.tolist())
self._label = self._train_df.label.values
self._labelNum = self._train_df['label'].unique().size
#负责装饰一个对象函数,让某生成对应的setter和getter函数,调用的时候,直接可以使用对象名.函数名这种类似于属性的调用方法来执行函数
@property
def distribution(self):
return self._distribution
@property
def image_size(self):
return self._image_size
@property
def image_shape(self):
return self._image_shape
@property
def dataNum(self):
return self._dataNum
@property
def feature(self):
return self._feature
@property
def label(self):
return self._label
@property
def labelNum(self):
return self._labelNum
data = clean_data('data/train.csv')
data.labelNum
a = pd.read_csv('data/train.csv')['label']
#index() 函数用于从列表中找出某个值第一个匹配项的索引位置。
sample_images = [list(a[a == x].index)[0:9] for x in range(data.labelNum)]
for x in sample_images:
plot_images(data.feature[x], data.label[x])
sample_images
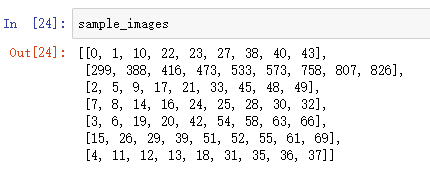
其中用到的一些数据:
a是image的label(表情)列表:

sample_images是从每一类中挑选出的前九张image(的标号):
data.feature方法可以将大小为2304的数据绘制成48*48的图像:

df = pd.DataFrame([[1, 1, 1, 1], [2, 2, 2, 2], [3, 3, 3, 3]])
s = df.sum(axis=1)
s1 = s[:, np.newaxis]
二、CNN&DNN
1、训练网络
很奇怪tensorBoard报错说文件路径不存在,提示说好像可以换成summaryfile,我也不会修改,于是就把生成tensorboard注释掉了。
tensorflow.python.framework.errors_impl.NotFoundError: Failed to create a directory: logs/1570693883from utility import clean_data, plot_training_history
import pandas as pd
import numpy as np
from time import time
from matplotlib import pyplot as plt
import tensorflow as tf
from tensorflow.python.keras.models import Sequential
from tensorflow.python.keras.layers import InputLayer, Input
from tensorflow.python.keras.layers import Reshape, MaxPooling2D
from tensorflow.python.keras.layers import Conv2D, Dense, Flatten, Dropout, Activation
from tensorflow.python.keras.layers.normalization import BatchNormalization
from tensorflow.python.keras.callbacks import TensorBoard
from tensorflow.python.keras.models import Model
from sklearn.utils.class_weight import compute_class_weight
name = ['angry','disgust', 'fear', 'happy', 'sad', 'surprise', 'neutral']
train_data = clean_data('data//train.csv')
test_data = clean_data('data//test.csv', False)
train = train_data.feature.reshape((-1, 48, 48, 1))/255
train_x = train[:-2000]
train_label = train_data.label[:-2000]
train_onehot = train_data.onehot[:-2000]
test_x = train[-2000:]
test_label = train_data.label[-2000:]
test_onehot = train_data.onehot[-2000:]
class_weight = compute_class_weight(class_weight='balanced',
classes=np.unique(train_data.label),
y=train_data.label)
#CNN model
inputs = Input(shape=(48,48,1))
'''
# First convolutional layer with ReLU-activation and max-pooling.
net = Conv2D(kernel_size=5, strides=1, filters=64, padding='same',
activation='relu', name='layer_conv1')(inputs)
net = MaxPooling2D(pool_size=2, strides=2)(net)
net = BatchNormalization(axis = -1)(net)
net = Dropout(0.25)(net)
# Second convolutional layer with ReLU-activation and max-pooling.
net = Conv2D(kernel_size=5, strides=1, filters=128, padding='same',
activation='relu', name='layer_conv2')(net)
net = MaxPooling2D(pool_size=2, strides=2)(net)
net = BatchNormalization(axis = -1)(net)
net = Dropout(0.25)(net)
# Third convolutional layer with ReLU-activation and max-pooling.
net = Conv2D(kernel_size=5, strides=1, filters=256, padding='same',
activation='relu', name='layer_conv3')(net)
net = MaxPooling2D(pool_size=2, strides=2)(net)
net = BatchNormalization(axis = -1)(net)
net = Dropout(0.5)(net)
# Flatten the output of the conv-layer from 4-dim to 2-dim.
net = Flatten()(net)
# First fully-connected / dense layer with ReLU-activation.
net = Dense(128)(net)
net = BatchNormalization(axis = -1)(net)
net = Activation('relu')(net)
# Last fully-connected / dense layer with softmax-activation
# so it can be used for classification.
net = Dense(7)(net)
net = BatchNormalization(axis = -1)(net)
net = Activation('softmax')(net)
# Output of the Neural Network.
outputs = net
model = Model(inputs=inputs, outputs=outputs)
tensorboard = TensorBoard(log_dir='logs/{}'.format(time()))
model.compile(optimizer='Adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
y = model.fit(x=train_x,
y=train_onehot,
validation_data=(test_x, test_onehot),
class_weight=class_weight,
epochs=100, batch_size=64,
callbacks=[tensorboard]
)
plot_training_history(y)
#
model.save('cnn.h5')
#DNN model
'''
inputs = Input(shape=(48,48,1))
dnn = Flatten()(inputs)
dnn = Dense(512)(dnn)
dnn = BatchNormalization(axis = -1)(dnn)
dnn = Activation('relu')(dnn)
dnn = Dropout(0.25)(dnn)
dnn = Dense(1024)(dnn)
dnn = BatchNormalization(axis = -1)(dnn)
dnn = Activation('relu')(dnn)
dnn = Dropout(0.5)(dnn)
dnn = Dense(512)(dnn)
dnn = BatchNormalization(axis = -1)(dnn)
dnn = Activation('relu')(dnn)
dnn = Dropout(0.5)(dnn)
dnn = Dense(7)(dnn)
dnn = BatchNormalization(axis = -1)(dnn)
dnn = Activation('softmax')(dnn)
outputs = dnn
#writer=tf.summary.FileWriter("logs",tf.get_default_graph())
#writer.close()
model2 = Model(inputs=inputs, outputs=outputs)
#tensorboard = TensorBoard(log_dir="logs/{}".format(time()))
model2.compile(optimizer='Adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
d = model2.fit(x=train_x,
y=train_onehot,
validation_data=(test_x, test_onehot),
class_weight=class_weight,
epochs=100, batch_size=64,
#callbacks=[tensorboard]
)
plot_training_history(d)
#model2.save('dnn.h5')
比较
在可训练参数数目相差不多的情况下, dnn每一个epoch的训练时间约为4s, 远快于cnn的19s, 但是在同样做了BN以及droupout的情况下, cnn的训练效果远好于dnn。
在验证集为数据集最后2000笔的情况下, cnn在验证集的正确率达到了60%, 而dnn只有40%, 证明了课上的理论, cnn能够更高效的利用每一个参数。















 1037
1037











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









