







Attention
2014年,Sutskever 等人提出的 sequence-to-sequence(seq2seq) 模型,是通过编码器神经网络逐个符号地处理输入序列,并将输入序列的所有信息压缩为向量表示形式,然后解码器神经网络根据编码器状态逐个符号地预测输出值,在解码过程中,将前一步预测出的值作为下一步预测的输入:
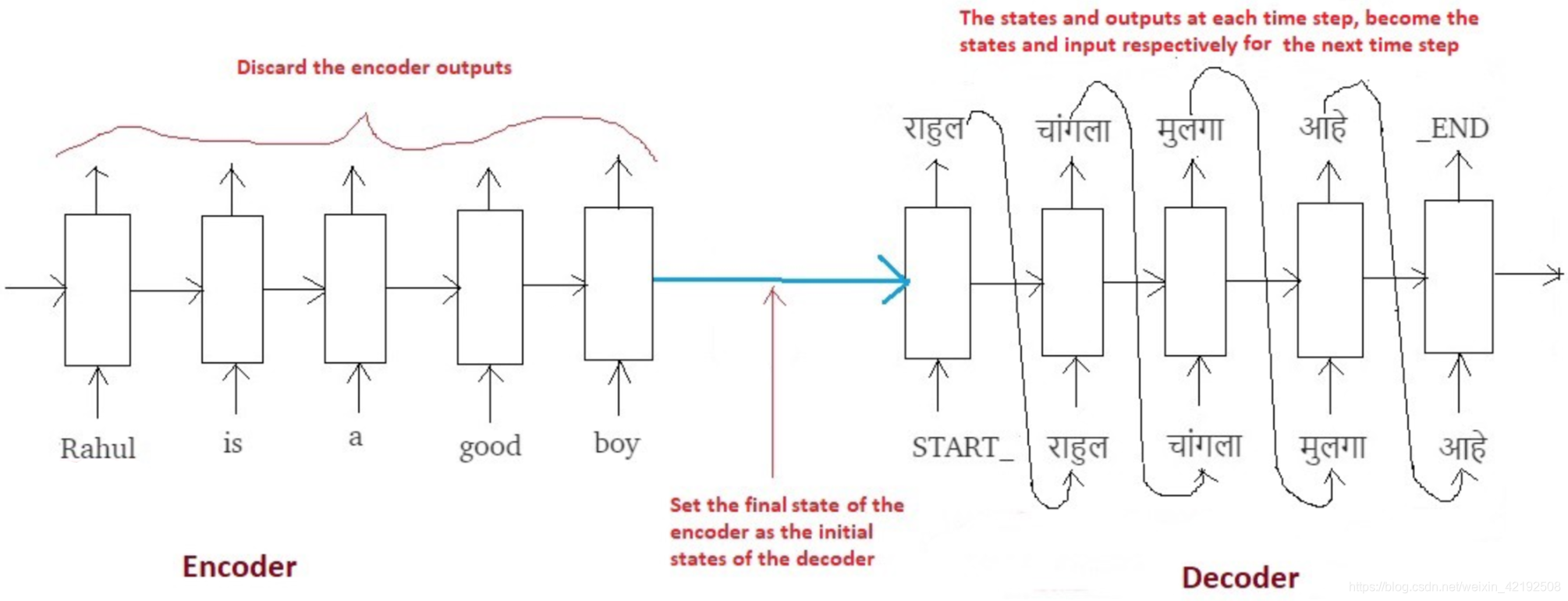
然而 seq2seq 模型的主要瓶颈在于需要把源序列的所有信息压缩为一个固定长度的向量(context vector)。随着输入序列的长度变长,在处理整个序列时,经常会忘记序列的前面部分。因此,Attention 机制被提出来解决这个问题。
Attention 机制允许解码器回头查看编码器的中间状态,然后将其加权平均作为额外输入提供给解码器。
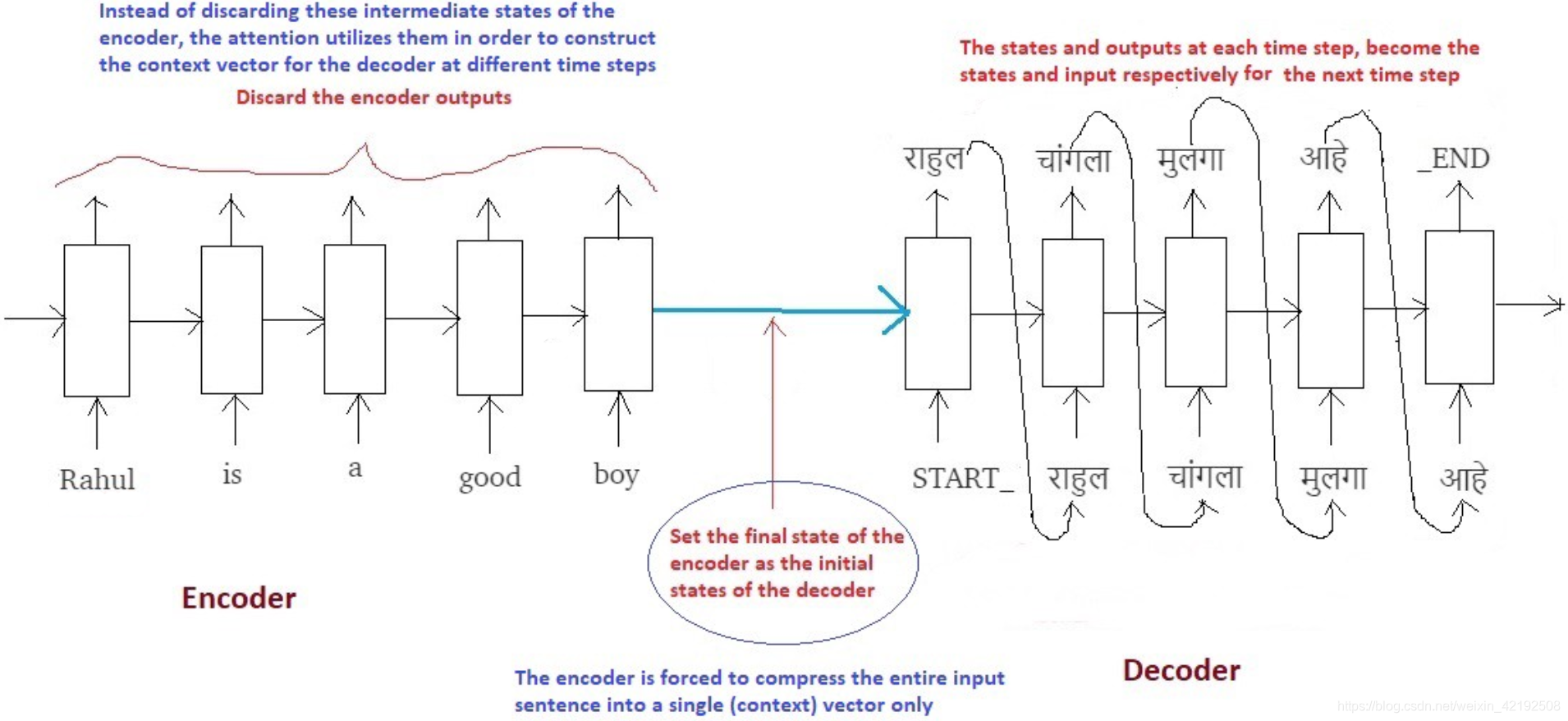
编码器和解码器常用的神经网络有 CNN、RNN、LSTM、GRU 等等,下面以 GRU 为编码器和解码器的神经网络来解释 Attention 机制在机器翻译中的应用。
输入序列:Rahul is a good boy;目标输出序列:राहुल चांगला मुलगा आहे
Encoder 中间状态
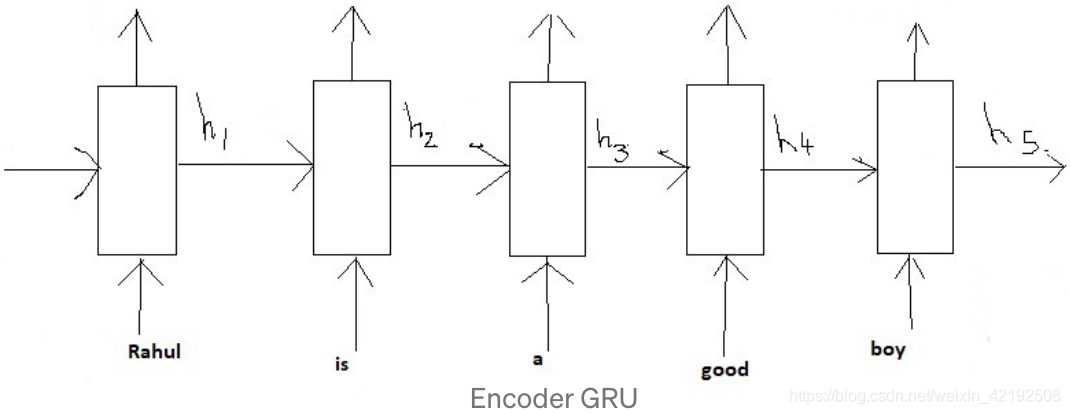
GRU 也是一种特殊的 RNN,相较于 LSTM,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









