







概要
MapReduce是处理和生成大数据集合的编程模型和相关实现。用户可以通过使用特定的Map和Reduce函数来完成对键值对**<key, value>**的处理。
Map函数主要是用于对处理键值对进行处理,生成中间键值对。Reduce函数主要用户依据中间键(intermediate key),来完成对中间值的归并(merge all intermediate values)。
MapReduce可以认为是一种编程框架,依据这种框架进行设计的程序可以自动完成并行化,并在大型集群上进行处理。运行时系统(run-time system)会自己考虑对输入数据进行划分,调度各部分机器的程序进行执行,处理机器出错。
介绍
在MapReduce之前,也有一些并行化的编程方法。但是这些方法对程序员要求很高:既要求成员能对计算机底层有深刻了解,也需要过硬的编程本领。鉴于对此类方法长久的愤恨,又有感于Lisp和其他多种语言的Map与Reduce方法,谷歌大佬 Jeffrey Dean 和 Sanjay Ghemawat 发明了MapReduce。
编程模型
在MapReduce中,计算任务的输入是键值对集合<key, value>,最后的结果产生的也是键值对集合。
在Map阶段,map函数有用户自己编写。它将键值对集合作为输入,并产生中间结果。这里的中间结果也是键值对集合。在中间过程中,会有一个Combiner发挥作用,它会将拥有相同关键字的键值进行运算处理,其对应的combiner函数可以是用户编写的。同时,Map函数完成,MapReduce还会对具有相同关键字的结果进行组合。
Combiner作用结果后,Partitioner函数会依据关键字将键值对发送到Reduce函数上,作为输入。MapReduce会有内置的sort函数运行,它会将键值对依据关键字进行排序。
需要明白的一点就是,在Map阶段,我们的输入输出是<key, value>键值对集合,但是在Reduce上,我们的输入是<key, List(value)>。也就是说,Reduce上的输入,是一个关键字对应多个值。这是由MapReduce内置的程序完成的,不需要认为干预,他是Map结束后依据关键字进行组合的结果。
在Reduce阶段,reduce函数也是由用户编写的函数。它接收中间结果作为输入,同一关键字的List,会议迭代器的形式传送给reduce函数。最后产生相应结果。如下图,就是一个简单例子。
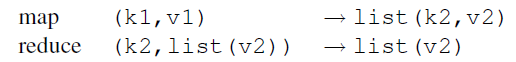
原理简介

运行过程
Map装置分布在多个机器上,他们协同工作,自动将输入数据划分为 M M M个划分。这些划分由不同的机器并行执行,Partitioner装置将Map的结果划分为 R R R个部分,发送到Reduce装置上。Partitioner一般使用的函数可以是哈希函数。( h a s h ( k e y ) m o d R hash(key)\ mod\ R hash(key) mod R)划分的数量(R)和划分函数(Partitioner)都可以由用户自己设置。Figure 1的执行流程解释如下:
(1)fork:用户程序中的MapReduce库会先将输入数据划分为 M M M部分,每一个部分的大小大概是16M-64M,之后MapReduce会启动每个机器上的用户程序副本。
(2)assign map/reduce:在众多的用户程序副本中,有一个会很特别。他是众多程序的头头,称之为Master。其余的被称为worker。可以这样认为,一个worker结点或者master结点就是一个机器。master结点会往worker结点上分配map或者reduce。
(3)read:分配到map的worker结点会读取输入文件,产生中间结果,存储出内存中。
(4)local write:缓存在内存中的数据会被定期写入磁盘,之后会有partitioner函数做划分,数据在磁盘的信息会被告知master结点,再由master结点决定将其分配给哪个reduce结点。
(5)remote read:当一个reduce结点被告知存储于磁盘中的数据的位置之后,reduce会调用远程读取程序读取磁盘中的数据,当一个reduce结点读完存储在磁盘中的中间数据后,就会启动排序函数,依据关键字对数据排序。这样,sort函数是必须的,在apache hadoop中,他是内置函数,默认运行。原因在于,发送到同一个reduce中的数据的关键字可能不同,sort可以让同一关键字的数据都组合在一起。
(6)write:程序运行结束后,reduce结点会依次往同一文件顺次写入结果。
(7)当所有map、reduce任务结束后,master程序会唤醒用户程序,返回到用户代码。
Master数据结构
对于每一个map、reduce程序,master会存储其状态(空间、进行、完成),以及每一个正在工作的worker节点的识别码。
master是中间结果从map任务传输到reduce任务的管道。对于每一次map任务,master会存储其中间结果被划分后的位置和大小,并将此信息发送给reduce任务。
容错
容错可以看作是mapreduce的天才之处。在大规模集群中,机器数量大,每一台机器都可能会出现故障,这是无法避免的,因而出错在mapreduce中被认为是常态。
Worker出错
master结点会周期性ping每一个worker结点,倘若结点没有回应则认为该结点出错。出错结点和已经完成任务的结点一样,会被初始化为空间状态,他们依然可以被其他MapReduce程序调用。
结点出错后,他们所执行的任务需要重新执行,因为他们的执行结果存储在其本地磁盘,一旦出错,其磁盘无法访问,因而需要重新执行。但是,reduce结点完成任务后出错则没有重新执行的必要,因为他们的数据存储在全局文件系统中。一旦一个节点的任务重新执行了,所有reduce结点都会收到消息。
其实这里可以引入一个问题:
为什么map执行后不直接把结果传送到reduce结点上进行处理,而是先存储在本地磁盘处理?
A:倘若,map直接将结果传送到Reduce节点上,一旦该结点出错需要重新执行,先前执行了一半数据已经传输出去了,无法收回,每个Reduce节点上都会有出错数据,这次的作业就会出现问题,整个作业都需要重新启动。但是,如果存储在本地,我们只需要重新执行出错任务即可。
Master出错
重新启动
程序正确性保证
MapReduce的并行化执行,和程序顺序执行得到的结果是相同。MapReduce内部依赖map和reduce任务的原子提交。
位置考量
MapReduce一个重要做法就是将计算向数据迁移,这样可以节省网络带宽。分布式文件系统会将每个文件划分为若干个64MB的块,并且为每个块保存3(一般为3)个副本在不同的机器上。master会优先安排文件所在的机器进行任务处理,其次才是靠近的机器。
任务粒度
Map的数量M和Reduce的数量R应当远远大于Worker节点的数量。
后备任务
在一个MapReduce任务快要完成的时候,master会调度正在运行的人物的后备任务进行执行。当后备任务或者原任务完成时,该任务被标记为已完成。
技巧
Partitioning函数
默认是哈希函数,用户也可以手动更改。
顺序保证
在Partitioner之后,会有内置sort函数发挥作用。
Combiner函数
map结果有大量重复的时候,combiner函数可以起到很好的节省带宽的作用。例如:一个map任务产生<a,1><a,1><a,1>,combiner函数可以将其变成<a,3>。一般而言,combiner函数可以和reduce函数拥有相同的实现,两者的不同就是combiner函数的输出为中间结果,reduce的输出为最终结果。combiner函数提高了执行的速度。同时,可以看到combiner是一个可选动作,因而,combiner和map的输出是同种类型的。
输入输出格式
支持多种格式的输入输出
副作用
会产生临时文件夹。不支持两阶段原子提交产生多个输出文件。
跳过bad records
这是一个可选模式,若master发现某一条记录不断出错,就会跳过该记录。
本地执行
帮助解决debug的问题
状态信息
在特定网页上能够看到任务的执行状况
计数器
Apache Hadoop
在hadoop中,主控节点不是master,被称之为JobTracker,它与分布式文件系统的主控结点NameNode一般位于同一个结点上,但也可以分开。worker结点被称之为TaskTracker,与分布式文件系统的DataNode位于同一个结点上。
在hadoop中,TaskTracker向JobTracker发送心跳信息。JobTracker不再主动问讯。
Reference
[1] Dean J, Ghemawat S. MapReduce: simplified data processing on large clusters[J]. Communications of the ACM, 2008, 51(1): 107-113.
[2] 黄宜华, 苗凯翔. 深入理解大数据-大数据处理与变成实践. 机械工业出版社
ps:欢迎关注公众号,掌握实时更新:
















 6630
6630











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









