






 本文介绍了如何使用Keras对神经网络模型进行序列化,包括保存模型结构到json文件和权重到HDF5文件。通过序列化,可以方便地保存训练过程中的最优模型。此外,文章还探讨了增量训练的概念,展示了如何在已有模型基础上进行增量训练。最后,提到了使用检查点在训练过程中自动保存模型,以便于恢复训练或评估。整个过程结合了模型构建、训练、可视化及恢复,对于理解和实践深度学习模型的保存与更新具有指导意义。
本文介绍了如何使用Keras对神经网络模型进行序列化,包括保存模型结构到json文件和权重到HDF5文件。通过序列化,可以方便地保存训练过程中的最优模型。此外,文章还探讨了增量训练的概念,展示了如何在已有模型基础上进行增量训练。最后,提到了使用检查点在训练过程中自动保存模型,以便于恢复训练或评估。整个过程结合了模型构建、训练、可视化及恢复,对于理解和实践深度学习模型的保存与更新具有指导意义。
由于神经网络训练需要较长时间,自动保存当前最优模型,使得整个训练过程可视化尤为重要。因此可使用Keras对模型进行序列化,即将模型结果和权重分别保存在json文件和HDF5文件中
from sklearn import datasets
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from keras.utils import to_categorical
from keras.models import model_from_json
# 导入数据
dataset = datasets.load_iris()
x = dataset.data
Y = dataset.target
# 将标签转换为分类编码的形式
Y_labels = to_categorical(Y, num_classes=3)
# 设定随机种子
seed = 7
np.random.seed(seed)
# 构建模型函数
def create_model(optimizer='rmsprop', init='glorot_uniform'):
# 构建模型
model = Sequential()
model.add(Dense(units=4, activation='relu', input_dim=4, kernel_initializer=init))
model.add(Dense(units=6, activation='relu', kernel_initializer=init))
model.add(Dense(units=3, activation='softmax', kernel_initializer=init))
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
return model
# 构建模型
model = create_model()
model.fit(x, Y_labels, epochs=200, batch_size=5, verbose=0)
scores = model.evaluate(x, Y_labels, verbose=0)
print('%s: %.2f%%' % (model.metrics_names[1], scores[1] * 100))序列化:使用to_json()方式将模型转换成json描述,并保存为json文件。之后使用save_weight()方式保存模型权重。
#将模型保存为json文件
model_json = model.to_json()
with open('model.json','w') as file:
file.write(model_json)
# 保存模型权重至hdf5文件中
model.save_weights('model.json.h5')反序列:直接读取json文件,并使用model_from_json()函数加载模型,而后使用load_weight方式加载模型权重参数。注意:通过加载方式建立的模型,需要先经过编译,再对其进行使用
# 从json文件中加载模型
with open('model.json','r') as file:
model_json = file.read()
# 加载模型
new_model = model_from_json(model_json)
new_model.load_weights('model.json.h5')
# 重新加载的模型需要再一次编译
new_model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
scores = new_model.evaluate(x, Y_labels, verbose=0)
print('%s: %.2f%%' % (new_model.metrics_names[1], scores[1] * 100))如果每次都需要用全部数据来更新模型,当数据量极大的时候,模型更新的时间开销非常大。这是可以采用增量更新的方式进行模型训练。在实际应用过程中,如果采用增量更新模型,需要事先做好与全量更新的对比试验,以确保增量更新的可行性。
下列代码为使用iris数据集,将其分为基本训练数据集和增量训练数据集。主要思路为:采用基本数据集训练完模型后,先序列化模型,然后重新导入模型,并进行增量训练。
from sklearn import datasets
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from keras.utils import to_categorical
from keras.models import model_from_json
from sklearn.model_selection import train_test_split
# 设定随机种子
seed = 7
np.random.seed(seed)
# 导入数据
dataset = datasets.load_iris()
x = dataset.data
Y = dataset.target
x_train, x_increment, Y_train, Y_increment = train_test_split(x, Y, test_size=0.2, random_state=seed)
# Convert labels to categorical one-hot encoding
Y_train_labels = to_categorical(Y_train, num_classes=3)
# 构建模型函数
def create_model(optimizer='rmsprop', init='glorot_uniform'):
# 构建模型
model = Sequential()
model.add(Dense(units=4, activation='relu', input_dim=4, kernel_initializer=init))
model.add(Dense(units=6, activation='relu', kernel_initializer=init))
model.add(Dense(units=3, activation='softmax', kernel_initializer=init))
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
return model
# 构建模型
model = create_model()
model.fit(x_train, Y_train_labels, epochs=10, batch_size=5, verbose=2)
scores = model.evaluate(x_train, Y_train_labels, verbose=0)
print('Base %s: %.2f%%' % (model.metrics_names[1], scores[1] * 100))
# 模型保存成Json文件
model_json = model.to_json()
with open('model.increment.json', 'w') as file:
file.write(model_json)
# 保存模型的权重值
model.save_weights('model.increment.json.h5')
# 从Json加载模型
with open('model.increment.json', 'r') as file:
model_json = file.read()
# 加载模型
new_model = model_from_json(model_json)
new_model.load_weights('model.increment.json.h5')
# 编译模型
new_model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
# 增量训练模型
# Convert labels to categorical one-hot encoding
Y_increment_labels = to_categorical(Y_increment, num_classes=3)
new_model.fit(x_increment, Y_increment_labels, epochs=10, batch_size=5, verbose=2)
scores = new_model.evaluate(x_increment, Y_increment_labels, verbose=0)
print('Increment %s: %.2f%%' % (model.metrics_names[1], scores[1] * 100))另一种方式是设置检查点,即只要设置的监视指标有所提高就会保存权重文件。检查点可以在程序意外中断时,通过事先保存好的json模型(构建好后即可对模型进行保存)和检查点自动保存的权重信息,实现恢复训练和数据预测。
from sklearn import datasets
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from tensorflow.keras.utils import to_categorical
from keras.callbacks import ModelCheckpoint
# 导入数据
dataset = datasets.load_iris()
x = dataset.data
Y = dataset.target
# Convert labels to categorical one-hot encoding
Y_labels = to_categorical(Y, num_classes=3)
# 设定随机种子
seed = 7
np.random.seed(seed)
# 构建模型函数
def create_model(optimizer='rmsprop', init='glorot_uniform'):
# 构建模型
model = Sequential()
model.add(Dense(units=4, activation='relu', input_dim=4, kernel_initializer=init))
model.add(Dense(units=6, activation='relu', kernel_initializer=init))
model.add(Dense(units=3, activation='softmax', kernel_initializer=init))
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
return model
# 构建模型
model = create_model()
# 设置检查点,此处只要设置的监视指标有所提升就会保存文件
#filepath = 'weights-improvement-{epoch:02d}-{val_accuracy:.2f}.h5'
# 如果只想保存监视指标最好的权重指标文件,只需要将filepath修改为如下途径
filepath = 'weights.best.h5'
#指定检查点保存的文件名称(包括模型权重值)、评估数据集只有在val_acc和mode=‘max’指标上有提升才设置检查点
#checkpoint = ModelCheckpoint(filepath=filepath, monitor='val_accuracy', verbose=1, save_best_only=True, mode='max')
#指定评估数据集只有在loss和mode=‘min’指标上有提升才设置检查点
checkpoint = ModelCheckpoint(filepath=filepath, monitor='loss', verbose=1, save_best_only=True, mode='min')
callback_list = [checkpoint]
model.fit(x, Y_labels, validation_split=0.2, epochs=200, batch_size=5, verbose=0, callbacks=callback_list)可利用History列表对整个模型训练过程中的参数变化进行可视化展示。
from sklearn import datasets
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from tensorflow.keras.utils import to_categorical
from matplotlib import pyplot as plt
# 导入数据
dataset = datasets.load_iris()
x = dataset.data
Y = dataset.target
# Convert labels to categorical one-hot encoding
Y_labels = to_categorical(Y, num_classes=3)
# 设定随机种子
seed = 7
np.random.seed(seed)
# 构建模型函数
def create_model(optimizer='rmsprop', init='glorot_uniform'):
# 构建模型
model = Sequential()
model.add(Dense(units=4, activation='relu', input_dim=4, kernel_initializer=init))
model.add(Dense(units=6, activation='relu', kernel_initializer=init))
model.add(Dense(units=3, activation='softmax', kernel_initializer=init))
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
return model
# 构建模型
model = create_model()
Model = model.fit(x, Y_labels, validation_split=0.2, epochs=200, batch_size=5, verbose=0)
# 评估模型
scores = model.evaluate(x, Y_labels, verbose=0)
print('%s: %.2f%%' % (model.metrics_names[1], scores[1] * 100))
# History列表
print(Model.history.keys())![]() 此处可看到可对loss和accuracy历史进行查询。
此处可看到可对loss和accuracy历史进行查询。
# 可视化accuracy历史
plt.plot(Model.history['accuracy'])
plt.plot(Model.history['val_accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train','validation'],loc='upper left')
plt.show() 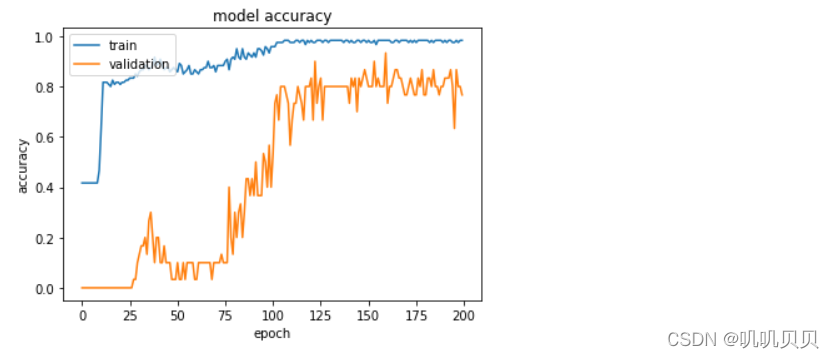
# 可视化loss历史
plt.plot(Model.history['loss'])
plt.plot(Model.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train','validation'],loc='upper left')
plt.show()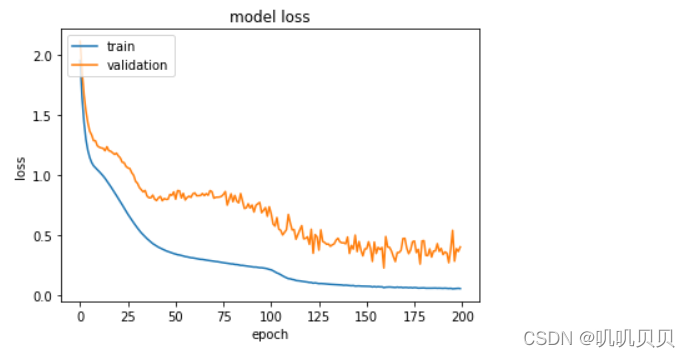
其中,具体参数历史点的值可以在检查点信息中进行查看。
该文代码源自魏贞原《深度学习:基于Keras的Python实践》


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









